
A research essay on the layer of the Physical AI stack that remains unclaimed: site-specific, maintained, provenance-carrying records of what assets exist, where they are, what state they are in, which rules and risks attach to them, and where our knowledge of them ends.
The public debate about Physical AI data is a debate about training. Teleoperation trajectories are precious and scarce; simulation has a domain gap; web-scale video has no grounding. All three arguments are about the same question: how do we make the brain. Almost nobody asks the question that follows immediately after: when a trained, general-purpose robot arrives at a specific bridge, plant, or city block on its first working day, what does it read? It needs the asset's identity and inspection history, the rules that govern it, the risk modelled for its location, and the boundary of what anyone actually knows. None of that is in the photons reaching its sensors that day, and no amount of model scaling puts it there. Physical AI does not have one data problem; it has two. The training problem (how to make the brain) has the entire field working on it. The grounding problem (what the brain reads when it arrives) has almost no one.
The argument of this essay runs in three steps. First, information about the physical world divides cleanly into what a machine can sense on-site and what it cannot, and autonomous driving has already run that experiment to a verdict: the market stopped paying for the world data cars learned to sense, and kept paying for the part they never will. Second, the canonical Physical AI data pyramid (web video, simulation, teleoperation) is missing a layer: the operational record of specific real-world sites, what exists there, what state it is in, what was judged and done about it. That layer has an awkward property: it cannot be collected, only accumulated as a byproduct of operational work. Third, the well-funded companies currently claiming the words "world model" and "spatial intelligence" are building four identifiable layers (localization, generation, alerting, control), and none of them is building this one. We will call it the record layer, give it its minimal specification, and show why the least glamorous line in that specification, an honest account of what is not known, decides whether the layer can feed autonomy at all.
What a robot cannot sense
Take any piece of information about a physical site and ask one question: could a machine standing at the site recover it, here and now, from its own sensors?
One class of information passes the test. Geometry, appearance, layout, the current visible condition of a surface: all of it is in the photons and the point clouds, and onboard perception keeps getting better at extracting it. LiDAR-inertial odometry now runs at 100 Hz on embedded hardware; dense reconstruction is a commodity. Any data product whose value proposition is "we measured the geometry so the robot doesn't have to" is competing against the robot's own improving senses, and it is on borrowed time.
The other class fails the test, and fails it permanently:
- History. When was this bridge last inspected, by whom, and what did the inspector conclude? What did this same crack look like five years ago?
- Rules. Which statute governs this asset, what load is it rated for, what clearance does work near it require?
- Identity. Which asset, in whose register, is this? What is it connected to?
- Modelled risk. What flood depth did the hazard authority project for this location? Under which scenario?
- Epistemic state. Has anyone actually surveyed this? With what method, and how much should the answer be trusted?
This is not a sensor limitation that better sensors will erode. The information is not in the photons. No camera resolution recovers last year's inspector judgment from a concrete surface; no LiDAR return encodes which of two indistinguishable valves is the one the permit covers. Asset tags, QR codes, and signage do not weaken the line; they prove it. A robot reads them optically, but the information they carry was authored, registered, and physically placed before it arrived: supplied context in its oldest form.
Some of the missing information was in photons once, and some of it is in photons right now, just not the robot's. The image of the same crack from the last inspection is history in physical form. A fixed camera around the next corner sees what the robot cannot see from where it stands; its stream is live, but everything that makes the stream usable, that the camera exists, where it points, and how far to trust it, has to be supplied. The material inside a painted column, and how many people live behind a wall, were never visible from the street at all. Everything except the live pixels reaches the robot through the same channel: as a supplied record. The line this essay draws is therefore not photons versus no photons. It is what the robot's own senses can recover, here and now, versus everything that has to be delivered from outside them: structured, bound to the asset, kept where a machine can ask for it.

The cleanest evidence that this partition governs what the market will pay for comes from the field that has pressure-tested it hardest: autonomous driving's HD maps.
Through the 2010s, the industry's assumption was that autonomy required centimeter-accurate, manually surveyed, manually maintained geometric maps, supplied as a data product. That business model failed economically: collection was expensive, refresh was slow, coverage stalled on highways, the sector consolidated around 2021, and by 2023 leading Chinese OEMs (XPeng, Li Auto) had publicly dropped HD-map dependence in favor of perception-centric stacks [1][2]. But the market did not stop paying for world data. What survived and grew is the "lite map": automatically generated, frequently refreshed, and carrying the content the car cannot see (lane-level rules, topology, regulatory attributes) rather than the dense geometry it can.
The market kept paying for the non-sensable residue and stopped paying for what the vehicle had learned to recover itself. Two corollaries follow.
Corollary 1. The world data durably worth supplying to an autonomous system is the part it cannot sense on-site. Supplying the rest can be a useful shortcut, and prior maps still bootstrap navigation today, but it is a race against onboard perception, and the race has one ending.
Corollary 2. A human crew standing at the same site cannot sense that information either. The inspection team at the bridge does not perceive the asset's load rating, its repair history, or the flood model for the floodplain it stands in; all of it must be supplied to them too, today. The demand for the non-sensable layer therefore does not wait for robots. It exists now, with paying consumers (the demand section below names them), and the arrival of machine consumers changes the reader, not the content of what must be supplied. What does change is the format the new reader can accept, and that format gap is what the rest of this essay is about.
This is the actuator-exchange observation at the heart of this essay: the actuator will change; the record will not. Today the consumer of the supplied layer is a human crew reading a dashboard, or an underwriter reading a risk table. The deployment pattern emerging on the robot side (examined below) suggests the next consumer is a machine calling an API. And the buyers do not change either: the asset operators, insurers, and municipalities paying for inspection and risk data today are the likeliest deployers of the robots tomorrow; when the actuator swaps, no new customer needs to be found.
There is a precedent for layers that survive their consumers being swapped out. Bloomberg's data infrastructure was built for human traders and was consumed, structurally unchanged, by algorithmic trading when it arrived. Google Maps accumulated a decade of human use before becoming the machine-called substrate of ride-hailing and delivery dispatch. In both cases the layer was built against the information's own structure rather than the reader's, and the reader swap was an expansion, not a rebuild.
The missing layer of the data pyramid
The Physical AI community describes its data supply as a pyramid [3]. At the base, web-scale video and human demonstration footage: vast, cheap, and ungrounded, with no action labels, no physical state, no connection to any specific deployable site. In the middle, simulation and synthetic data: controllable and scalable, with a domain gap that must be engineered against. At the top, robot teleoperation trajectories: perfectly grounded in the robot's own embodiment and brutally expensive, the scarcest resource in the field.
Notice what all three layers have in common: they exist to train the policy. The pyramid is a description of how to make the brain. It contains no layer describing what the brain consults about the specific world it is deployed into.
The missing layer is the operational record of the real world: tuples linking (imagery, asset, location, state history, expert judgment, action, outcome). A photograph of a girder tied to the bridge's identity in the national register, to its coordinates, to the deterioration grade assigned at the last statutory inspection, to the repair that followed, and to what the repair achieved. Nothing about this is training data in the pyramid's sense. Its job is grounding: it converts a generally intelligent system into one that is competent at this site.

Three properties of this layer explain why the pyramid's economics never produced it.
It is local, dynamic, private, and confidence-weighted, which means it lives permanently outside model weights. A foundation model can absorb everything the internet knows about bridges in general; it cannot absorb the inspection history of bridge #38122 in a prefectural register updated last quarter, for the same reason large language models did not absorb your company's document store. Retrieval did not die when LLMs got stronger; it became more valuable, because stronger reasoning over private, current context beats weaker reasoning over it. Site context is to Physical AI what retrieval context is to language models: the part that is always outside the weights, no matter how good the weights get.
It cannot be collected; it can only accrue. Web video is crawled, simulation is computed, teleoperation is purchased by the hour. The operational record resists all three modes. The expert judgment in the tuple exists only because a qualified engineer was contractually obligated to stand at the asset and produce one; the outcome exists only because someone did the repair and came back. There is no collection campaign that produces this layer at a price anyone will pay: collecting it means duplicating, at full cost, work the world already funds once as inspection and maintenance. It is a byproduct of operating, inspecting, insuring, and maintaining the physical world. Public registers, scans, and CAD imports can bootstrap a static skeleton of the layer; what they cannot supply is the moving part, the judgment-and-outcome stream that keeps the record current and trusted. That dictates the industrial structure of whoever builds it: you cannot be a data company that visits the world; you must be embedded in the work the world already pays for, and accumulate the record as the work's exhaust.
Its absence is invisible until deployment day. A policy trained on the full pyramid demos beautifully in any environment and still cannot answer the first operational question a deployment asks: is this asset the one in the work order, and is it safe to act on? The gap does not show up in benchmarks. It shows up at the site.
The record layer
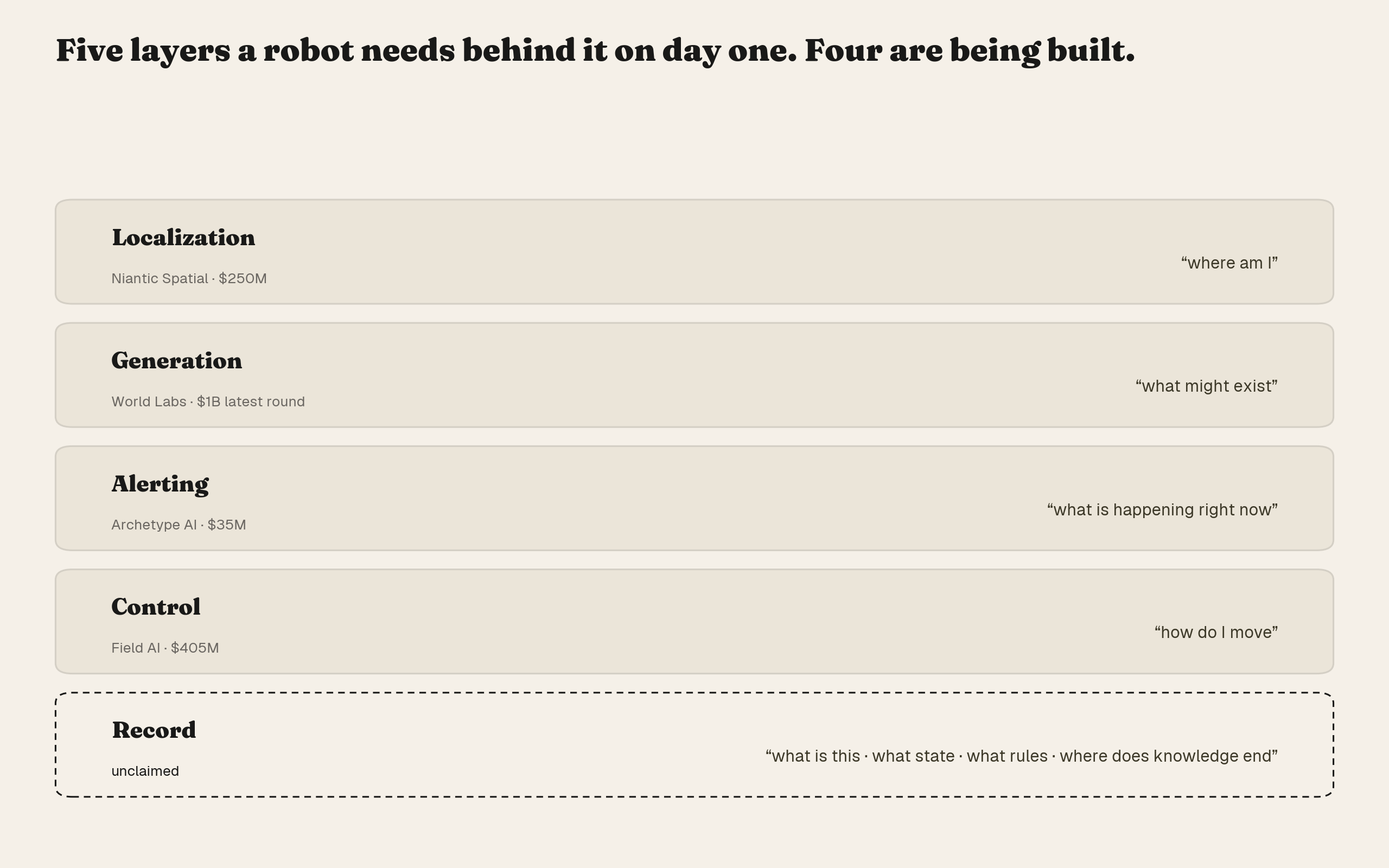
If the layer is real and the demand precedes the robots, the obvious question is who is building it. The current generation of companies claiming the "world model" and "spatial intelligence" vocabulary has raised, in aggregate, more than $1.7B. Examined at the level of what their products actually emit, they sort into four layers, none of which is this one.
| Company | Raised | What the product emits | Layer |
|---|---|---|---|
| Niantic Spatial [4] | $250M | Centimeter-level positioning, semantic 3D queries against a geospatial foundation model | Localization |
| World Labs [5] | $1B (latest round) | Generated 3D environments, described by the company as "digital cousins… not exact replicas" | Generation |
| Archetype AI [6] | $35M | Real-time sensor fusion producing instantaneous alerts | Alerting |
| Field AI [7] | $405M | Robot autonomy software; field data arises as a byproduct of control | Control |
Each of the four does something a robot genuinely needs. Localization tells the machine where it is. Generation gives it somewhere to practice. Alerting tells it what is happening right now. Control tells it how to move. As of mid-2026, the public product surfaces of all four contain no asset state records, no risk scores bound to asset identity, no provenance fields, no confidence metadata. Nobody in the funded cohort is producing the layer that records what is known about this specific world, and how well.
That layer, the operational record the pyramid is missing, is the record layer: site-specific, maintained records of assets, their states, and their risks, carrying provenance and epistemic confidence, structured for machine consumption.
In stack diagrams this slot is usually labelled context: everything a general intelligence must be supplied about the specific world it operates in. Make that concrete for a deployed robot, and context turns out to have three feeds. There is the geometry it navigates by, the map or the twin, which it increasingly builds and refreshes with its own sensors. There are the senses it borrows, the fixed camera around the corner, another machine's viewpoint, which extend its perception across space. And there are the records: what the things in the map are, what state they are in, what rules attach to them, how far any of it can be trusted. The third feed is what makes the first two operational. A bare mesh lets a robot move; it does not tell the robot what anything is. It becomes a robot-ready map when the load rating, the material, the occupancy behind the wall, and the slope's behaviour in rain are riveted to its coordinates. A borrowed camera is noise until something records its existence, its pose, and its calibration. Of the four funded layers, alerting lives in this second feed: it streams events, without the registry that would make a stream trustworthy. The record layer is the third feed, and the reason the other two add up to a place where a machine can be trusted to work.
We use the narrower name deliberately. Context names what the layer is for; record names what it has to be made of, and the difference is what the four product surfaces above leave unbuilt. Any of the four companies can say, accurately, that they provide context. None of them maintains records.
The record layer's minimal specification is four requirements, each earning its place by a failure mode it prevents.
- Structured records, not documents. A PDF inspection report is the format in which the record layer dies. Whatever a human consumer receives must be a view over structured storage, never the storage itself; otherwise the work produces revenue and accumulates nothing a machine can later consume.
- Bound to geography and asset identity. A finding that cannot be joined to a register entry and a coordinate is an anecdote. The unit of the layer is the asset, not the file.
- Mandatory provenance and confidence fields, with enforced nulls. Every value carries which source asserted it and how much it should be trusted, and where there is no evidence, the record says null, never a default.
- Queryable by API. The test of the layer is mechanical: a machine can call it without a human translating. A dashboard may sit on top; the dashboard is not the product.
The third requirement is the least glamorous of the four, and it decides whether the layer can safely feed autonomy. Machine perception already enforces it everywhere on the sensing side of the line this essay draws: detectors emit confidence scores, state estimators carry covariance, mapping stacks keep an explicit unknown state that no planner treats as free. Nothing in a modern robot's pipeline treats the absence of a measurement as a measurement of absence. That convention collapses at the boundary where sensing ends and records begin. A bridge register row with a blank damage field: does it mean inspected and sound, or never inspected? A human reader applies ambient skepticism. A machine consumer applies none. It reads the row. If those two states share one encoding, the dataset silently converts ignorance into clearance, and every system built downstream inherits the conversion.
The schema that restores the convention is small: per attribute, a covered flag, the source that claims coverage, a confidence tier recording how coverage was decided, and one hard invariant: covered = false ⇒ value = null. An asset nobody examined cannot carry a state value, period. We have published this design worked out in full against a national-scale open dataset, including the failure modes that only surface when the schema has to be populated from real, imperfect sources [8][9]. Epistemic boundary data, the explicit record of where knowledge ends, is not metadata. It is the entry ticket.

Nor is it schema hygiene in search of a use case. For 167 communities across the Nankai Trough scenario, records of this kind (road-graph fragility, hazard exposure, demographics, terrain reads, every score term traceable to the exact public-data query that produced it) were composed into per-community isolation-risk rankings; on the 2024 Noto Peninsula retrospective, where the actually-isolated communities are publicly documented, the method recovered 22 of the 26 in its top-26 [10]. Provenance-carrying, confidence-weighted records are what decisions get made from, today, by humans.
From the consumer side, the gap is just as concrete. Having packaged and operated a full LiDAR-based autonomous navigation stack in production [11], we can report what it actually reads at runtime: maps with their unknown cells, traversability, waypoints. The geometric layer arrives with its epistemic state intact; everything above it (identity, history, rules, risk) never arrives, because nothing exists to supply it. The consumer interface of the record layer is, today, an empty socket.
The same test separates the geospatial and asset-management incumbents from the layer. Esri, Hexagon, Trimble, and Autodesk hold large pieces of the operating surface, from GIS and reality capture to BIM and work-order systems, but their default unit is a map, a model, a drawing, or a ticket inside a human workflow. The record layer is narrower and stricter: asset-state records bound to register identity and coordinates, carrying provenance, confidence, and enforced nulls, behind an interface a machine can call without a planner or a GIS analyst translating. An incumbent becomes part of the layer the day its outputs satisfy that spec; adjacency is not the layer.
The four funded layers answer where am I, what might exist, what is happening, and how do I move. The record layer answers what is this, what state is it in, what rules apply, and where does our knowledge end. A robot on its first working day needs all five behind it. Only four are being built.
The demand side, today
A skeptic should at this point ask whether any of this is demand, architecture, or only narrative. The evidence comes at three altitudes, and only the first is a purchase-order market today.
Insurers and asset-software incumbents are already buying the human-consumed version of the layer. In January 2025, Moody's acquired CAPE Analytics [12], whose product is exactly the shape this essay describes: imagery in, address-level structured risk attributes out. Over 120 risk-predictive attributes per property across the US and large parts of Canada and Australia, used by nearly half of the top-50 US property insurers, and cash-flow positive before the acquisition. Bentley Systems (FY2024 revenue $1.35B) is building out Asset Analytics, its imagery-to-asset-condition line, as a leadership-designated growth initiative, and disclosed that the portfolio, accelerated by two acquisitions closed at the end of 2025, reached a roughly $50M revenue run rate [13]. That is a real market, and a small one: what an early layer looks like from the inside. And CoStar acquired Matterport at roughly $1.6B enterprise value with a stated rationale that includes extracting information from the 3D spatial database with AI/ML [14]. What was bought is machine-readable building data, not cameras. These cases are also the boundary of what exists: each is one vertical, one consumer type, built for human decision loops; none claims the cross-asset, machine-consumable spec of the previous section. The layer's strongest existence proofs are, at the same time, the measure of how unclaimed it remains.
On the robot side, site digitization is emerging as a precondition of deployment, not an afterthought. The industrial deployment path NVIDIA's Mega Omniverse Blueprint defines [15] runs in one direction: robot fleets are developed, tested, and validated inside a physically accurate digital twin of the specific facility first, and deployed into the real facility after. The named early cases follow the pattern. KION and Accenture mapped GXO's Épinoy warehouse with spatial scanners and built the digital twin before the first autonomous truck was deployed into it, operating as of March 2026 [16]. Schaeffler is rolling out digital twins across its plants with a target of more than half of its global factories by 2030, already tests humanoid robots inside those twins, and in May 2026 signed a phased agreement with the robotics company Humanoid to deploy a four-digit number of robots across its facilities by 2032 [17]. Foxconn's industrial arm reports testing and training humanoids for its factories in the same Omniverse workflow [18]. The claim has to be worded carefully. These twins are today mostly geometry, the sensable class, so what the chain establishes is architectural precedence (the site is made machine-readable before the robot arrives, not by the robot after it arrives), not evidence that anyone is consuming records yet. Commercial scale-out also remains early, with one publicly confirmed warehouse in the KION case. The record layer is the part of that site readability the twins still omit. What the chain shows is a direction, not yet a market.
And in Japan, the record's content is already mandated by law. Under the Road Act's enforcement regulations, roughly 730,000 bridges and 11,000 tunnels must receive close visual inspection every five years by qualified personnel, and the law explicitly requires that the results be recorded and the records preserved for as long as the asset is in service [19]. About 91% of those bridges are managed by municipalities, and 450 of Japan's municipalities, a quarter of the total, employ zero civil engineering staff [20], making outsourced, digitized inspection structural rather than cyclical. The statute is format-neutral: a paper record complies. That gap is the opening. The law already mandates that the record exist for the asset's lifetime; it does not yet mandate that the record be machine-readable. The infrastructure ministry, meanwhile, is actively organizing the market for the upgrade: its inspection-support technology catalog (now in its third national inspection cycle, 2024-2028) certifies imagery-based inspection methods as substitutes for close visual inspection [21], and the ministry's own national road-structures database has exposed bridge and tunnel condition grades through an API since 2022 [22]. The state itself already publishes asset state as data. On the open-data substrate, Project PLATEAU's national budget runs at roughly ¥2.3B per year explicitly for 3D city-model data deliverables, with open data now covering 306 municipalities [23]: a verified, recurring, national-scale line item for machine-readable world data, and still a small one. The Japanese demand argument in this essay rests entirely on statute and budget documents, not on third-party market forecasts, because the forecasts we adversarially checked did not survive the check.

What the market has already killed
A thesis is only as credible as its account of the graveyard. Three failures define the constraints under which a record layer is viable, and anyone claiming the layer should be able to recite them.
HD maps: manually maintained static context dies. The full post-mortem is above; the constraint it leaves behind is that the record layer must sit on the automated-extraction side of the line from day one. Human surveyors keying in attributes is the HD-map cost structure wearing a new narrative, and it will meet the same end. The legal inspection cycle matters here for a second reason: besides creating demand, it works as a refresh mechanism. The statutory five-year cadence regenerates the record layer's state fields as a funded byproduct, rather than as a cost the data vendor eats. The cadence also matches the content: lane geometry decays in weeks, which made HD-map refresh a treadmill; asset condition decays over years, which makes a five-year statutory clock workable. (A boundary we hold ourselves to: we do not describe any of this as "continuously updated." On current evidence, nobody, including the flagship industrial workflows, can honestly claim continuous update loops for site records. Cadence is real; "continuous" is, for now, marketing.)
Matterport: the standalone spatial-data company gets repriced. Matterport's acquisition price was 75-85% below its 2021 peak valuation. Building data is valuable (CoStar paid $1.6B for it), but the market has decisively repriced independent spatial-data companies. The viable structure is the one every positive example in this essay shares: CAPE's attributes are bundled into underwriting; Bentley's analytics are bundled into infrastructure software. No private buyer pays for a context layer in the abstract. They pay for an outcome (a policy priced, an inspection report filed, a risk ranked), and the record layer accrues as that work's structured exhaust. Bundling can look like a compromise of the thesis. Given the byproduct property, it was never optional.
Omniverse Cloud: platform narrative outran revenue. NVIDIA shuttered its Omniverse Cloud service in August 2025 for lack of demand, per reporting by The Information in January 2026 [24]. A horizontal, platform-level "digital twin of everything" offer, from the strongest possible distributor, did not find buyers fast enough. The reading is double-edged. It clears space for vertical entries: if the giants' horizontal play has not closed, the layer will be built bottom-up, one paying vertical at a time. And it is a warning addressed to essays like this one: a narrative, however coherent, is not a validated market. The difference between this essay and a pitch deck is supposed to be the discipline of saying so.
Put the three together and the graveyard stops reading as rejection. Across the adjacent layers it has priced, the market has been specifying the record layer, killing, one failure at a time, the configurations that don't work (manual maintenance, standalone data plays, horizontal platforms) and rewarding the one that does: automated extraction, bundled with work the world already pays for, vertical-first, refresh funded by the work's own cadence. Anyone who accepts the byproduct property should expect no standalone claimant to exist; that absence follows from the economics. The gap is the absence of operators holding the machine-readability spec inside the bundles.
Honest boundaries
Three things this essay has not shown, stated with the same care as the things it has. First, no robot company has yet bought site records at arm's length: the machine consumer is a trend judgment grounded in the deployment architecture, not an observed transaction, and we price it as upside on a layer that is already a business for human consumers, as Moody's, Bentley, and CoStar have demonstrated with their balance sheets. Second, the verified pure-data spend is still small: the budget line we can document is PLATEAU's ~¥2.3B/year, and anyone quoting multi-trillion-yen addressable markets for this layer is ahead of the auditable evidence. Third, the layer's one failure mode is internal: nothing prevents doing all of this work and accumulating nothing, by delivering conclusions as documents instead of records. The discipline that decides the outcome is a single quarterly question asked of one's own past deliverables: could a machine consume this today, without a human translating? Every "no" is the HD-map failure, locally re-enacted. The record layer is not a product category one announces; it is a specification one either holds the line on, deliverable by deliverable, or doesn't.
The brain is being built by the best-funded research organizations in the world. The body is being built by a manufacturing ecosystem compounding annually. Both will arrive at the site and ask the same questions a human crew asks on day one: what is this, what state is it in, what rules apply, what is known, and what is not. Someone has to have written that down, structured, bound to the asset, provenance attached, nulls enforced, before they arrive.
We are writing it down: in Japan first, where the statute already mandates the record and the state has already built the open-data substrate beneath it, to the spec this essay has argued for. The pipelines, schemas, and rankings cited above are not illustrations of the layer. They are its first entries. The first data problem has the whole field working on it. The second now has an address.
Before the robots arrive, someone has to make the world machine-readable.
References
- P. Chen, Z. Luo, X. Jiang, Z. Yin, J. Li, Maps for Autonomous Driving: Full-process Survey and Frontiers. arXiv:2509.12632, 2025. On the economics of manually maintained HD maps and the shift to lightweight, automatically updated map content. arxiv.org/html/2509.12632v1
- On the 2021 consolidation and the 2023 OEM shift: NVIDIA, "NVIDIA Acquires DeepMap," June 2021, blogs.nvidia.com; Woven Planet (Toyota), CARMERA acquisition, July 2021, woven.toyota; TechNode, "Xpeng, Li Auto, and Huawei: Competition heats up in assisted driving," July 2023, technode.com
- NVIDIA, GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. arXiv:2503.14734, 2025. Source of the data-pyramid framing: web data and human videos at the base, simulation-generated synthetic data in the middle, real-robot data at the top. arxiv.org/abs/2503.14734
- Niantic Spatial, "Niantic's next chapter," 2025. nianticlabs.com/news/niantic-next-chapter
- World Labs, funding announcement, 2026. worldlabs.ai/blog/funding-2026
- Archetype AI, Series A announcement. archetypeai.io/blog/archetype-ai-series-a
- Field AI, "$400M+ raised to advance embodied AI at scale," 2025. fieldai.com/news
- plateau-bridge. Open-source pipeline indexing 29 Japanese cities (~5.26M buildings) from Project PLATEAU CityGML into queryable per-building Parquet records. github.com/pixelx-jp/plateau-bridge, 2026.
- Telling "Safe" from "Unsurveyed" in PLATEAU's Hazard Data: An Open-Source Coverage-Confidence Layer. Yodo research, May 2026. yodolabs.jp/en/research/coverage-confidence-public-hazard-data
- Community Isolation Risk for the Nankai Trough. Yodo research, May 2026. yodolabs.jp/en/research/community-isolation-risk-nankai-trough
- nav-autonomy-deploy: An Open-Source Production Runtime for LiDAR-Based Autonomous Navigation. Yodo research, April 2026. yodolabs.jp/en/research/nav-autonomy-deploy
- Moody's Corporation, "Moody's to Acquire CAPE Analytics, Adding AI-Powered Geospatial Property Risk Intelligence to Its Industry-Leading Insurance Risk Models," January 13, 2025 (acquisition completed January 2025 per Moody's Q1 2025 Form 10-Q). ir.moodys.com. Insurer adoption and cash-flow status: CAPE Analytics, "CAPE's New Chapter with Moody's," January 2025, capeanalytics.com; attribute count: CAPE corporate boilerplate, "over 120 novel risk-predictive property insights."
- Bentley Systems, "Q4 and Full-Year 2024 Results" (total revenues $1,353.1M), bentley.com; "Bentley Systems Acquires Talon Aerolytics and Pointivo Technology for Asset Analytics Leadership," January 5, 2026 (portfolio "revenue run rate of approximately $50 million"; both transactions closed December 2025), bentley.com
- CoStar Group, "CoStar Group to Acquire Matterport, Global Leader in Immersive 3D," completed February 2025. investors.costargroup.com
- NVIDIA, "Mega Omniverse Blueprint," CES 2025. blogs.nvidia.com/blog/mega-omniverse-blueprint/
- KION Group, "KION deploys first AI-supported autonomous industrial truck at GXO warehouse in Épinoy, France" (spatial scan to digital twin before deployment), March 16, 2026. kiongroup.com
- NVIDIA, Schaeffler digital-twin case study (more than half of global manufacturing sites by 2030), nvidia.com/en-us/case-studies/schaeffler/; Humanoid, "Humanoid secures landmark deal with Schaeffler to deploy thousands of humanoid robots," May 13, 2026. thehumanoid.ai
- NVIDIA, "NVIDIA Omniverse Physical AI Operating System Expands to More Industries and Partners," GTC, March 18, 2025. Brand Cheng (CEO, Fii): "Using NVIDIA Omniverse and Mega, we're testing and training humanoids to operate in our leading factories as we advance to the next wave of physical AI." nvidianews.nvidia.com
- 道路法施行規則 (Road Act Enforcement Regulations), Article 4-5-6: five-year close visual inspection of bridges and tunnels, with results to be recorded and preserved while the structure remains in service. MLIT. mlit.go.jp/common/001260175.pdf
- MLIT, municipal engineering-staff statistics: 450 municipalities (25.8%) with zero civil/building engineers (FY2017); municipal civil engineering staff down 27% from the 1996 peak. mlit.go.jp/common/001258713.pdf
- MLIT, 点検支援技術性能カタログ (Inspection Support Technology Performance Catalog) and the periodic bridge inspection guidelines permitting catalog technologies in the third inspection cycle (2024-2028). mlit.go.jp/road/sisaku/inspection-support/
- 全国道路施設点検データベース (National Road Structures Inspection Database), public API since July 2022. road-structures-db.mlit.go.jp
- MLIT, Project PLATEAU FY2025 budget lines (都市空間情報デジタル基盤構築調査 ¥1.136B + 構築支援事業 ¥1.173B) and open-data coverage (306 municipalities, May 2026). mlit.go.jp/page/content/001854876.pdf, mlit.go.jp/plateau/open-data/
- The Information, "Nvidia's Big Ambitions to Solve Manufacturing Show Slow Returns So Far," January 2026 (Omniverse Cloud shuttered August 2025 for lack of demand). theinformation.com