
A research note on the field that decides whether a public hazard dataset is deployable into operational decisions, drawn from an end-to-end indexing pass over 29 Japanese cities on top of Project PLATEAU, published as the open-source plateau-bridge pipeline.
Pipelines built on PLATEAU commonly treat a row with
river_flood_covered = trueandriver_flood_depth_max = 0as this building was modelled and found safe. That conflation is wrong, and we measured how wrong it is on real PLATEAU 2024 data. In Tokyo's Suginami-ku alone, the conflation fabricates roughly 63,000 buildings as surveyed-and-safe when PLATEAU's flood layer in fact carries no modelled depth coverage for the area they sit in. The honest classification for those buildings iscovered = false(we don't know), and a hazard dataset that cannot return that answer is not deployable into insurance, real-estate due diligence, or municipal disaster planning.
The first column most engineers add to a hazard table is a depth or in-zone value: "how deep does the flood get at this building." That column is necessary and not sufficient. A depth value of zero is ambiguous: it can mean "the model considered this location and found it dry" or it can mean "the model never looked here at all." A hazard dataset that lets those two states share the same row encoding is structurally dishonest, and downstream consumers cannot recover the distinction from the data alone.
This note works through the field that has to exist to disambiguate them, what we will call coverage confidence, and the design constraints that surface once it has to be populated against real PLATEAU cities. Three observations dominate the discussion below. First, the naive default that source metadata supports (declared_full_admin) systematically overstates coverage across the cities examined here. Second, the obvious-looking fix of cross-referencing MLIT's KSJ polygons makes the problem worse for many cities, because PLATEAU's bundled flood polygons can contain the corresponding KSJ polygons rather than the other way round. Third, the design that survives both observations is a new confidence tier, inundation_bounded, paired with a sanity check that catches incomplete cross-references before they mask data the pipeline already has.
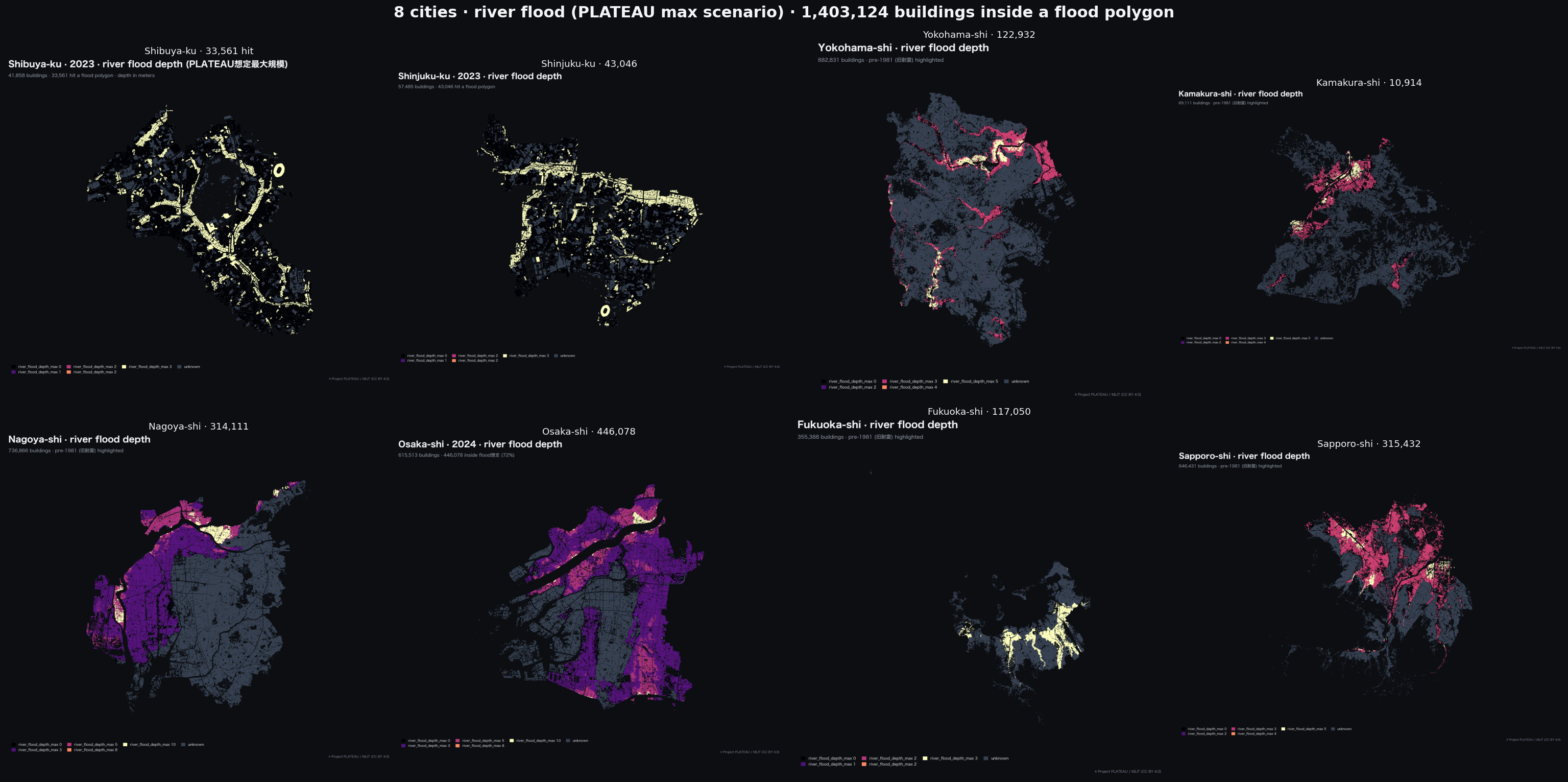
The empirical work runs against 29 Japanese cities covering 5,258,094 buildings: the 23 Tokyo special wards plus six regional cities (Yokohama, Kamakura, Nagoya, Osaka, Fukuoka, Sapporo). Each city was rebuilt under each candidate confidence model and the row-level classifications compared. The indexing pipeline that produced these results is published as open source under the name plateau-bridge [1], and the data-integrity invariants the resolver enforces are recorded as a separate document referenced from the codebase [2]. The pointers exist so the findings below are reproducible; the note itself is about the finding, not the tool.
Why one field decides whether a hazard dataset is honest
A hazard column on a building row is informative only when paired with a column recording the epistemic state of that row. The minimum schema is five fields per hazard kind:
{kind}_covered # was this building inside the survey extent?
{kind}_coverage_source_ids # which authority claims to have surveyed it
{kind}_coverage_confidence # how trustworthy is the "covered" claim
{kind}_depth_max # depth, only meaningful when covered = true
{kind}_hit_source_ids # which inundation polygon actually hit

The third field is the one this note is about. Its job is to record how the pipeline decided a building was covered. Without that field, the row can be technically correct in the data while being misleading in interpretation, because two very different epistemic states (a careful survey concluding "safe" versus the absence of any survey at all) become indistinguishable to downstream queries.
The semantics are inherited from the ISO 19115 lineage-and-quality framework [3] and are enforced by a single hard invariant: covered = false ⇒ depth = null. A building that was not surveyed cannot have a depth value, period; the pipeline writes null, not zero, and downstream UIs must surface that null as a distinct visual state. Tests in the codebase pin this invariant against representative edge cases (a building whose centroid lies inside an inundation polygon but outside the coverage extent), to prevent regressions [2].
The implication for design is that introducing coverage_confidence as a first-class field costs storage roughly equal to the depth field itself (one short enum per hazard per building). For 5.26 M buildings × 5 hazard kinds, that is approximately 25 million enum values added to the schema; on Parquet with ZSTD and dictionary encoding, the on-disk cost is well under one percent of the bundle. The field carries the load-bearing distinction the dataset is built around, and the storage required to carry it is essentially free.
The naive default: declared_full_admin
The natural starting point, and the one many pipelines published on top of PLATEAU adopt either explicitly or by omission, is to take the source metadata at its word. PLATEAU's metadata/udx_*_op.xml per-theme XML files include free-text descriptions like "全行政区域を対象として作成" (created to cover the entire administrative area). When this declaration is present, a pipeline can mark a building as covered = true if and only if its centroid intersects the city's admin polygon. This is the confidence tier labelled declared_full_admin below.
The trouble is that declared_full_admin overstates coverage in essentially every Japanese city we examined, and the overstatement is not a small fraction. The mechanism is straightforward: MLIT does not actually survey every parcel in a city. Flood projections are produced for flood-prone areas, typically along rivers, coastlines, and watershed lowlands. A building that sits uphill, away from any modelled water system, lies outside the area where the published flood layer records any depth value at all. The honest classification of that building is no modelled-depth evidence either way, which is not the same as modelled and safe.
The free-text declaration in PLATEAU metadata is technically accurate at the level it asserts (the dataset is "for" the entire administrative area), but it is silent on the question that actually matters to a downstream consumer (was this individual building investigated). The result is that a row labelled covered = true, depth = 0 under declared_full_admin is ambiguous in exactly the way the coverage-confidence field is supposed to disambiguate.
The empirical magnitude is what makes this worth taking seriously. Suginami-ku in central Tokyo is a useful illustrative case because its geography is mostly inland and hilly: a substantial fraction of its built area sits well outside MLIT's modelled river-flood zones. Under declared_full_admin, Suginami's pipeline output classifies 142,660 buildings as covered = true, of which 79,912 intersect a flood projection (depth > 0) and the remaining 62,748 are encoded as depth = 0 (i.e., the data implies surveyed safe). Once clipped to the area where PLATEAU records modelled depth (the construction is described in the next two sections), essentially all of those implicit-safe rows reclassify as unknown. The empirical table later in this note records 63,064 buildings as unknown for Suginami under the new resolver. The arithmetic is straightforward: the baseline covered = true count of 142,660 drops to 80,389 under inundation_bounded, producing on the order of 62,000 newly-unknown rows; the small residual between that figure and the 63,064 total reflects buildings already classified unknown under the baseline (centroids that fell outside the admin polygon edge). The hit column moves only marginally over the same operation (79,912 → 80,389, a sub-1% boundary-edge shift caused by buildings that intersect a modelled-depth polygon under the new resolver but did not under the centroid-vs-polygon test of the baseline).
A reclassification at this scale in a single ward is not a corner case; it is the modal outcome. We saw similar magnitudes across the 23 Tokyo special wards and the six regional cities, with the specifics depending on each city's geography. The pattern is consistent: declared_full_admin is a usable default, but it is not safe to ship as an unqualified label.
The obvious fix that does not work
The natural next step, once declared_full_admin is understood as overstated, is to find an authoritative coverage polygon against which to clip the admin boundary. MLIT publishes such polygons separately, in the Kokudo Suuchi Joho (国土数値情報, KSJ) catalog [4]. The relevant series is A31 (洪水浸水想定区域, "estimated flood inundation zones"). Pulling the A31 polygon for each PLATEAU source-document, intersecting with the admin boundary, and using the result as the explicit extent is the textbook answer.
The resolver for this approach consists of a parser that reads PLATEAU's metadata XML to extract source-document names (free-text Japanese strings naming the flood-projection documents that fed each hazard layer), a curated coverage_sources.json mapping each source-document name to its KSJ download URL, and a downloader that pulls and unions the KSJ polygons into a single CoverageExtent. The mapping table populated for this experiment contained 39 prefectural-A31 entries covering Tokyo, Kanagawa, and Osaka. Running the pipeline against Suginami-ku and inspecting the output exposes the failure mode the design has to handle. Under the KSJ-as-explicit-polygon configuration, Suginami's classification becomes:
| Confidence tier | covered = true count |
of which depth > 0 |
|---|---|---|
declared_full_admin (baseline) |
142,660 | 79,912 |
explicit_polygon (KSJ A31 only) |
10,786 | 10,764 |
The number of "covered" buildings collapsed from ~143,000 to ~11,000, and the hit count collapsed from ~80,000 to ~11,000 in lockstep. Two interpretations of this drop are possible. The first is that declared_full_admin was wildly overstating coverage and the KSJ polygons are revealing the actual surveyed area. The second is that we are now wildly understating coverage by clipping against an incomplete polygon.
Tracing through PLATEAU's own published metadata for Suginami's flood layer made the second interpretation the correct one. Suginami's PLATEAU 2024 udx/fld/ data is fed by prefectural-river inundation projections for Arakawa-system tributaries (荒川水系神田川・善福寺川・妙正寺川 など; portions are catalogued under KSJ A31 prefectural-jurisdiction files), together with Tokyo Metropolitan Government's 流域浸水予想区域図 series (神田川流域 ほか), which are independent metropolitan urban-flooding scenarios not in KSJ A31. The TMG series covers urban-flooding scenarios (heavy rain on small urban watersheds) that the national A31 series does not include.
The cleanest way to see the mismatch is to compare what each source covers in Suginami. KSJ A31-21_13 (Tokyo prefecture) contains 41,051 polygons, of which 2,087 intersect Suginami's admin polygon, covering approximately 10.2% of the ward's land area. PLATEAU's own bundled flood polygons, by contrast, intersect 79,912 of the ward's 142,660 buildings (roughly 56% of building centroids) under declared_full_admin. The KSJ polygon is a strict subset of where PLATEAU records modelled flood depth, not a superset.
The consequence is that using KSJ A31 as the explicit-polygon extent actively masks data PLATEAU already has. A building whose location was modelled by the TMG series and has a non-zero depth value from PLATEAU's flood polygon would, under naive KSJ-as-extent, be classified as covered = false because its location is outside the KSJ A31 boundary. The pipeline would write depth = null for a building whose depth value was already computed. This is the more damaging of the two errors: the original declared_full_admin overstatement at least leaves the depth value intact for downstream consumers to interpret, whereas the KSJ-induced error overwrites a known depth with null and destroys the underlying datum.
The "obvious" textbook fix turns out to be the failure mode the design has to defend against.
The introduced tier: inundation_bounded
The data-integrity rule at the centre of the project's design, explicitly recorded in the codebase's HONESTY document [2], is "never reverse-engineer the coverage extent from inundation polygons." The intent of that rule is to forbid the synthetic move of buffering or dilating known flood polygons to fabricate a surveyed-safe zone around them. "The model thinks the river floods here; therefore a 100m buffer around the flood is surveyed-safe" is the canonical way to lie about hazard coverage, because it claims investigation where none happened. The rule was written precisely to head off that move.
The discovery that KSJ alone strictly understates where PLATEAU records modelled flood depth forces a reading of the rule. Buffering or dilating inundation polygons synthesises a boundary the source data does not assert and is correctly forbidden. Taking the union of PLATEAU's bundled flood polygons at their native boundary, with no dilation, is a different operation: it makes no synthetic claim. The boundary it produces is the boundary of PLATEAU's bundled modelled-depth polygons, and what we report is exactly that. The pipeline is not asserting safety in the buffered region around floods; it is asserting the absence of a model outside the modelled region.
That distinction is the basis for a new confidence tier, inundation_bounded. The rule, in code, is: when PLATEAU's per-building flood-depth polygons are available for a hazard theme, the union of those polygons (with no buffering, no dilation, no smoothing) is used as the coverage extent. Inside the union, buildings are covered = true with depth values copied from the polygon they intersect. Outside the union, buildings are covered = false, depth = null. The tier is stricter than declared_full_admin (it eliminates the implicit-safe fabrication) and broader than explicit_polygon against KSJ alone (it captures the metropolitan and prefectural sources PLATEAU has but KSJ does not publish).
The resolver applies four tiers in order, most trustworthy first:
explicit_polygon. A separately-published 想定区域 / 調査範囲 polygon, either named on the catalog entry or auto-resolved via KSJ. The published polygon is what the survey authority itself claims as the surveyed area, so it is the strongest signal.inundation_bounded. When PLATEAU bundles per-building flood polygons, the union of those polygons is taken as the extent. The literal truth of the data: inside the union, modelled with a depth value; outside, not modelled.declared_full_admin. When the source metadata claims full-administrative coverage and step 2 is not applicable, intersect with the admin polygon. Retained for hazard themes whose PLATEAU bundles lack per-building polygons.unknown. None of the above.covered = false,depth = null. Downstream UIs must render this state distinctly.

An implementation of this resolver fits in roughly 250 lines of Python over GeoPandas, plus a metadata-XML parser and a KSJ downloader. The mechanics are routine; the load-bearing design decisions are the ordering above and the sanity check described next.
The sanity check: containing the KSJ-incomplete-mapping failure
The four-tier resolver above is correct in isolation but is exposed to a regression. Once the coverage_sources.json mapping table is populated for a watershed (i.e., once explicit_polygon resolves to a KSJ polygon for that hazard), step 1 takes priority over step 2. If the KSJ polygon is incomplete relative to what PLATEAU actually models, exactly the Suginami / TMG-flood-series case described above, promoting to explicit_polygon will write null for buildings whose depth values are present in PLATEAU. The very upgrade meant to improve coverage confidence becomes the move that destroys data.
The defence is a sanity check inside the resolver, applied between step 1 and step 2. After computing a candidate explicit_polygon from KSJ, the resolver intersects that candidate with PLATEAU's bundled inundation polygons and computes the area ratio: fraction of PLATEAU's hazard-polygon area contained inside the candidate. If the ratio falls below a threshold (currently 0.95, i.e., 95%), the candidate is rejected and the resolver falls through to inundation_bounded. The threshold is conservative on purpose: we would rather demote a near-perfect KSJ mapping to inundation_bounded than risk masking real depth data.
Two test cases pin this behaviour in the codebase:
test_resolver_falls_back_when_ksj_insufficient_vs_hazard
test_resolver_accepts_ksj_when_it_dominates_hazard
The first fixes Suginami-style data: a KSJ polygon that covers 15.5% of PLATEAU's hazard area, well below the threshold, must fall through to inundation_bounded. The second fixes the complementary case: a KSJ polygon that contains 95%+ of PLATEAU's hazard area is accepted and the city's confidence tier rises to explicit_polygon. Together, the two tests pin the design intent: the system upgrades when the upgrade is safe and refuses to upgrade when the upgrade would mask data, regardless of which authority "should" be more trustworthy.
The sanity check runs at build time, once per city per hazard. Its cost is one shapely union per hazard plus one intersection-area computation. A log line is emitted every time the check triggers, so a curator adding a new KSJ mapping that turns out to be incomplete sees, in the build output, exactly which city demoted to inundation_bounded and why. Data-integrity failures must be loud at build time rather than silent at query time.
Empirical result across 29 cities
Running the full 29-city catalog under the four-tier resolver and comparing row-level classifications against the prior declared_full_admin baseline yields a clean aggregate effect: across the 5.26 M buildings, approximately 1.74 million rows previously classified covered = true, depth = 0 under declared_full_admin are reclassified to covered = false, depth = null under inundation_bounded. These are the implicit-safe rows described earlier; under the new resolver they sit outside the modelled-depth polygon, and the dataset records the absence of modelled-depth evidence rather than a depth value.
For Suginami specifically:
| Confidence tier | covered = true |
depth > 0 (hit) |
depth = 0 (implicit safe) |
|---|---|---|---|
declared_full_admin (baseline) |
142,660 | 79,912 | 62,748 |
inundation_bounded (after the fix) |
80,389 | 80,389 | 0 |
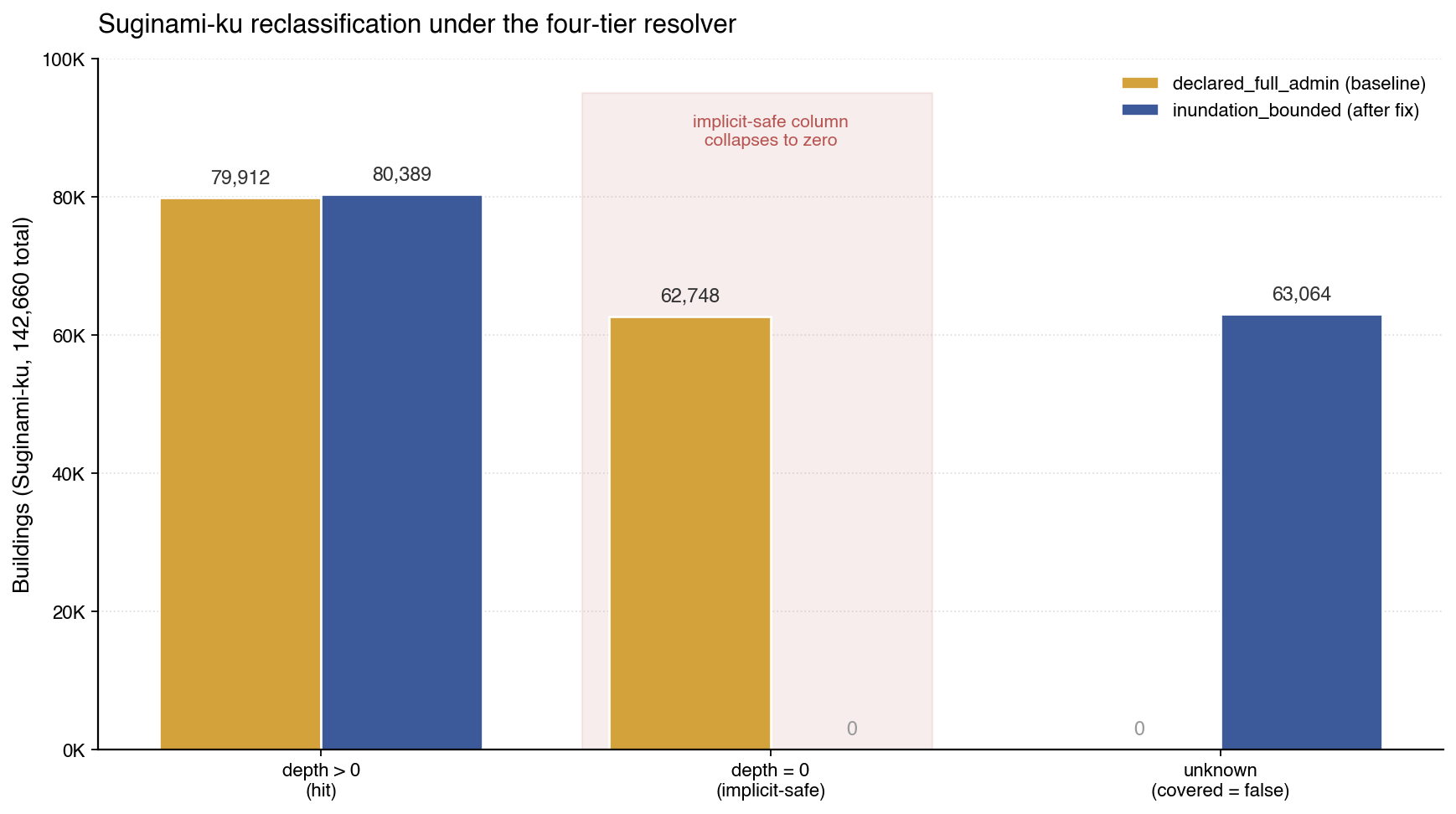
The implicit-safe column drops to zero by construction: every covered = true row under inundation_bounded has a depth value, because the extent is the modelled-depth polygon. Buildings outside the modelled area are classified as unknown rather than surveyed-safe. The new count of 63,064 unknown buildings in Suginami is the honest answer to "how many of this ward's buildings have no modelled flood depth in PLATEAU." The hit count is essentially unchanged across the two configurations (79,912 → 80,389, a sub-1% boundary-edge difference), which is the property the design was meant to achieve: the reclassifications occur in the previously-implicit-safe column, not in the modelled-and-flooded column. The pipeline is not hiding data; it is correctly relabelling buildings whose status was previously unknown-but-recorded-as-safe.
Per-city specifics depend on geography: wards with significant inland built area (Suginami, Setagaya, Nakano; Fukuoka, Nagoya) show the largest absolute drops in covered count; wards adjacent to major rivers (Edogawa, Adachi) show smaller relative drops because more of their area sits inside PLATEAU's bundled flood polygons. The aggregate runtime overhead of the four-tier resolver against the baseline pipeline is one extra shapely.union_all per hazard per city, which runs under 20 seconds for the largest cities.
Why this matters downstream
Coverage confidence shows up at the joining seam, wherever another system takes a per-building hazard row and acts on it. An insurance underwriting model joining a portfolio against the table has to decide what to do when the table says covered = false. A municipal disaster-planning dashboard has to decide whether to render a building as safe, at-risk, or unknown. A research pipeline computing exposed-population statistics has to decide whether covered = false rows belong in the denominator. The "safe" default treats absence of evidence as evidence of absence; the "cautious" default escalates because absence of a model is not absence of risk. Which default is right is the consumer's decision, but the dataset has to make the decision possible by encoding safe and unknown distinctly at the row level. A dataset that fabricates surveyed-safe for buildings MLIT never modelled takes that decision away. Aggregations undercount risk because implicit-safe rows pull central tendency toward zero; UIs cannot render unknown because the data does not carry the distinction.
The point is not specific to PLATEAU. Any public hazard dataset publishing per-building depth values without a coverage-confidence field has the same conflation; any downstream pipeline inherits it transitively. The fix lives at the source: the field has to exist in the schema and the pipeline has to populate it honestly. Adding it after the fact requires recovering information that was discarded at ingestion, which is usually not possible.
What's still open
Mapping-table population. The coverage_sources.json mapping from PLATEAU source-document names to KSJ URLs is community-curated by design, covering roughly 150 distinct flood-projection documents across Japan, each a manual cross-reference. The current table covers 39 prefectural-A31 entries for Tokyo, Kanagawa, and Osaka. Extending it to national regional-bureau A31 files (Kanto, Kinki) and to the remaining 44 prefectures is mechanical work but volumetrically large.
Cross-source unification. Tokyo Metropolitan Government's 流域浸水予想区域図 series, the very files that caused the KSJ-only fix to fail, are distributed largely as PDF reports, with some machine-readable depth/elevation derivatives available through Tokyo Open Data but no single published shapefile for the polygon extents. PLATEAU's pipeline ingests these somehow; recovering the polygon extents in a form the resolver can consume directly is the remaining gap.
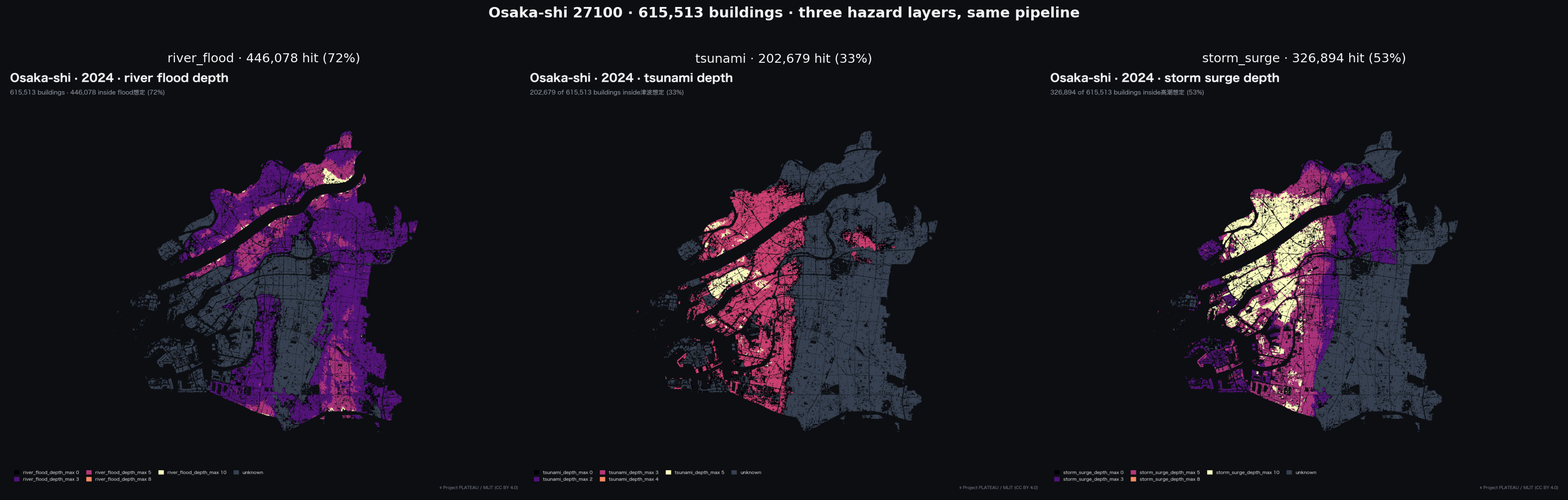
Temporal joins and beyond-flood themes. The published field in coverage_sources.json records when each KSJ source was issued; the resolver does not yet use it to automatically demote stale explicit_polygon matches (e.g., A31-2017 polygons being applied against PLATEAU 2024 inundation data). The four-tier design is implemented uniformly across river_flood, inland_flood, tsunami, landslide, and storm_surge, but the empirical results in this note are flood-specific. Tsunami (KSJ A40), landslide (A33), and storm-surge (A49) plausibly show the same declared_full_admin overstatement, but the four-tier resolver has not been evaluated against them at scale.
References
- plateau-bridge. Open-source pipeline indexing 29 Japanese cities (~5.26 M buildings) from PLATEAU CityGML into queryable Parquet. github.com/pixelx-jp/plateau-bridge, 2026.
- plateau-bridge HONESTY.md. The data-integrity invariants the pipeline enforces, including the
covered = false ⇒ depth = nullrule and the "never reverse-engineer extent from inundation polygons" rule. github.com/pixelx-jp/plateau-bridge/blob/main/docs/HONESTY.md, 2026. - ISO 19115-1:2014, Geographic information: Metadata, Part 1: Fundamentals. The international standard on geographic metadata, including the lineage and quality elements that underlie coverage-confidence semantics. International Organization for Standardization, 2014.
- 国土数値情報ダウンロードサイト (KSJ). MLIT's catalog of national geospatial information, including the A31 series of estimated flood inundation zones. nlftp.mlit.go.jp/ksj/.
- Project PLATEAU. MLIT's open 3D city model programme. mlit.go.jp/plateau/.
- OGC CityGML 2.0 specification. The base data model PLATEAU's CityGML files conform to. Open Geospatial Consortium, 2012. PLATEAU additionally uses Japan's i-UR (i-都市再生) Application Domain Extension, which adds the building-attribute and hazard-attribute fields the resolver reads.
- M. F. Goodchild, "Citizens as sensors: the world of volunteered geography." GeoJournal 69(4), 211–221, 2007. Foundational paper on user-contributed geographic data quality, relevant by analogy: the same coverage-confidence problem (was this datum observed at all) recurs in volunteered data.
- P. Mooney and M. Minghini, "A review of OpenStreetMap data." In Mapping and the Citizen Sensor, Ubiquity Press, 2017. A review of data-quality work on OSM, including coverage and completeness measures that parallel
coverage_confidencefor crowdsourced data. - G. B. M. Heuvelink, Error Propagation in Environmental Modelling. Taylor & Francis, 1998. The textbook on how data-quality fields propagate through joins and aggregations; the principles below the surface of the
inundation_boundeddesign. - Apache Parquet, column-oriented storage format used for the per-city building tables. parquet.apache.org.
- MIERUNE plateau-gis-converter (nusamai), the Rust converter for PLATEAU's i-UR CityGML extensions; the pipeline shells out to nusamai for the CityGML → GeoJSON conversion. github.com/MIERUNE/plateau-gis-converter.
- DuckDB. The in-process analytical database used for the SQL examples and benchmarks against the per-city Parquet outputs. duckdb.org.