
VLMを中心としたロングテール欠陥問題へのアプローチ、vLLMによる本番展開
コンピュータに「一度も見たことのないもの」を検出させようとした経験はありますか?インフラ点検の分野では、これは仮説上の問題ではなく、まさに中心的な課題です。最も稀な欠陥こそ、往々にして最も危険なものです。電柱に開いたキツツキの穴、風力タービンブレードのヘアラインクラック、橋梁金具に生じた異常な腐食パターン。こうしたコーナーケースは出現頻度が極めて低く、学習データセットを十分に構築することができません。しかし、たった一つの見逃しが深刻な安全上の問題につながる可能性があります。
従来の教師あり検出器——YOLOとその派生モデル——は、欠陥クラスが明確に定義され、学習データが豊富な場合に優れた性能を発揮します。しかし、コーナーケースの検出はこれらの前提を根本から覆します。検出対象がオープンエンド(「異常なもの全て」)であったり、新しい故障モードが時間とともに出現したり、最も重要な異常がデータ分布の極端な裾に位置していたりします。私たちがインフラ点検チームと協力してこの問題に取り組んだ際、Vision-Language Models(VLMs)をvLLMで効率的にサービングすることで、根本的に異なる、より実用的な解決策が得られることを発見しました。
本記事では、私たちのアプローチの技術的基盤について解説します。曖昧で説明を要するコーナーケースのワークフローにおいて、VLMがなぜopen-set検出器より実用的な優位性を持つのか、vLLMがいかにして本番環境への展開を実現可能にするのか、そして汎用モデルとドメイン特化型点検システムの間のギャップを埋める3つの適応戦略——in-context learning、few-shot fine-tuning、retrieval-augmented generation——について説明します。
従来型検出器がコーナーケースに失敗する理由
インフラ点検における根本的な課題は、教師あり学習の閉世界仮定と、実際のインフラ故障が持つ開世界的性質との間のミスマッチです。
欠陥の分布は本質的にロングテールです。いくつかの一般的な欠陥タイプ(表面クラック、軽度の腐食)がデータセットの大部分を占め、重要な希少異常はごく少数の事例しか持たない裾部分に位置します。点検された風力タービンのうち、35,000基中でヘアラインクラックが確認されたのはわずか約8.5%であり、これは最も重要でありながら検出が最も困難な欠陥タイプです [1]。実際の大量点検における異常率は、全サンプルの1%未満にとどまるのが一般的です [2]。人手による目視検査のエラー率は10〜20%に達し、特定の欠陥タイプを見逃す確率は最大25%にもなります [3]。
インフラの各分野には固有のコーナーケースが存在します。送電線の点検では、キツツキの穴(サブセンチメートル)、コロナ放電(UV帯のみ)、金具部分の微細な撚り線のほつれなど、送電線全体の構造に対して極めて小さい欠陥を扱わなければなりません [4]。橋梁点検では、表面からは見えない内部の微小クラック、複合的な欠陥の重複、汚れや植生に隠された欠陥に直面します。風力タービンブレードの点検では、人の目ではかろうじて確認できるヘアラインクラック、落雷によるエロージョン、表面下の剥離に対処する必要があり、業界の見積もりによればブレード1枚の交換費用は30万ドルを超える場合があります。
10種類の欠陥クラスで学習されたYOLO型検出器は、11番目の欠陥を決して検出できません。これは既知クラスのデータを増やすことで解決できる問題ではなく、閉集合パラダイムの構造的な性質です。
2つの技術的方向性:open-set検出 vs. VLM
最小限のデータでオープンエンドな検出を実現するために一般的に提案されている2つのアプローチを検討しました。
Open-set / one-shot検出
T-Rex2 [5]、Grounding DINO [6]、DINO-X [7]などのモデルは、テキストプロンプト、視覚的プロンプト(バウンディングボックスやポイントの例示)、またはその両方を使用してオブジェクトを特定することを目指しています。T-Rex2は、インフラ点検に関連する重要な知見を提示しました。一般的なオブジェクトではテキストプロンプトが視覚的プロンプトを上回りますが、希少なオブジェクト(出現頻度ランク800〜1,200位)では視覚的プロンプトがテキストを大幅に上回ります [5]。この相補性は、異常な欠陥パターンを言葉で記述することは難しいが、参照画像で示すことは容易な産業環境において、直接的に重要な意味を持ちます。
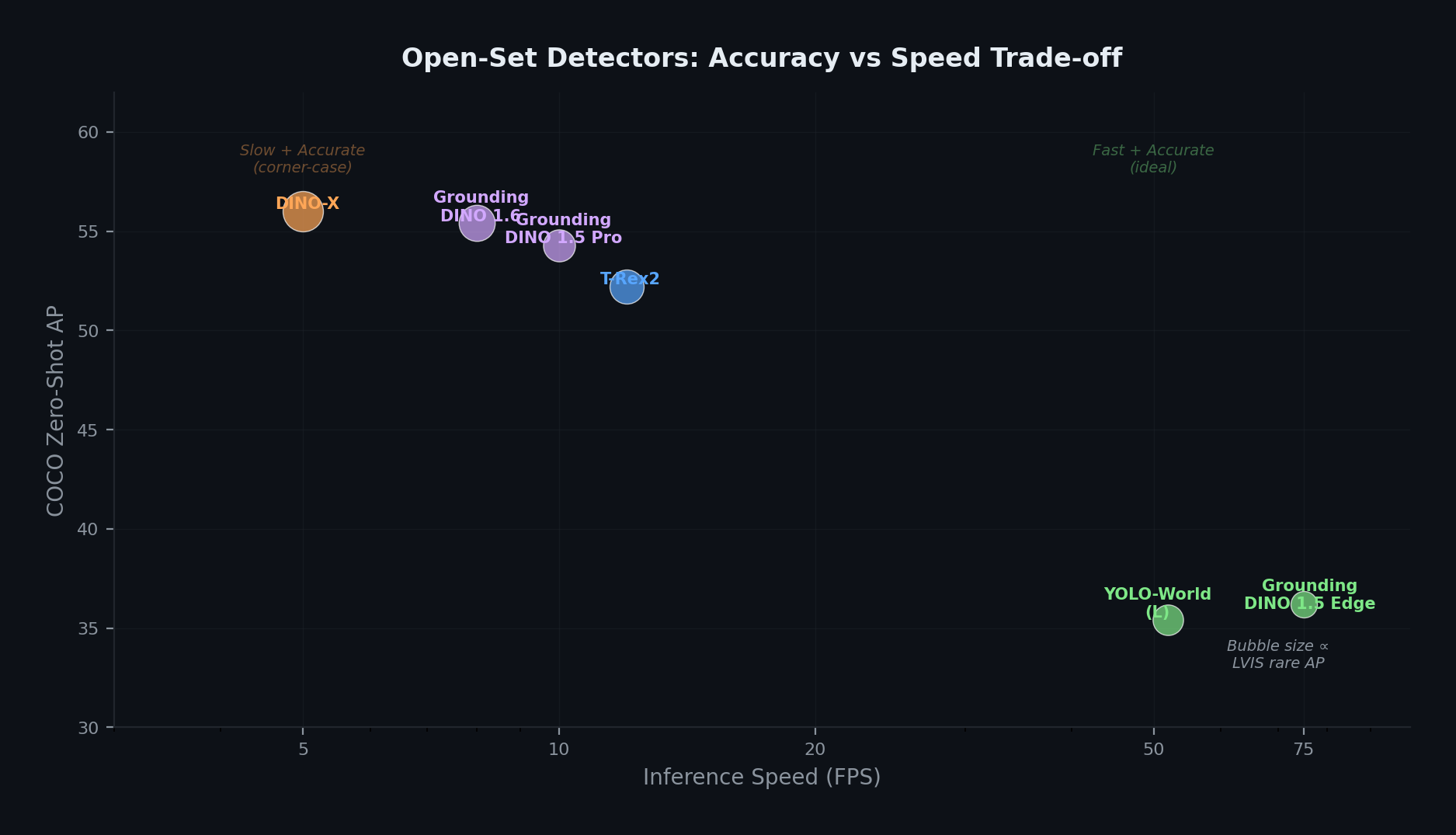 Open-set検出モデルは、精度と速度の明確なトレードオフを示します。DINO-XはCOCOおよびLVIS希少クラスの双方でzero-shot APの最高値を達成し、YOLO-Worldは一次スクリーニングに適したリアルタイム性能を提供します。バブルサイズはLVIS希少クラスAPに比例しており、これはコーナーケース検出において最も重要な指標です。
Open-set検出モデルは、精度と速度の明確なトレードオフを示します。DINO-XはCOCOおよびLVIS希少クラスの双方でzero-shot APの最高値を達成し、YOLO-Worldは一次スクリーニングに適したリアルタイム性能を提供します。バブルサイズはLVIS希少クラスAPに比例しており、これはコーナーケース検出において最も重要な指標です。
DINO-Xは現時点で最先端の性能を達成しており、COCOのzero-shotで56.0 AP、LVISの希少クラスで63.3 APを記録しています。後者は従来の最高値から5.8 APの改善です [7]。YOLO-Worldは異なるアプローチを採り、YOLOv8の上にopen-vocabulary機能を構築することで、52 FPSで35.4 APを達成しています。これはGrounding DINOファミリーと比較して桁違いの速度です [8]。
しかし、これらのモデルは私たちのユースケースにおいて実用上の限界に直面しました。クライアントのコーナーケース検出対象は、プロンプトに基づく検出器が確実に特定するには曖昧で一般的すぎることが多かったのです。「構造的に異常なもの全て」や「予期しない変形」といった概念は、テキストプロンプトに明確にマッピングすることが困難であり、視覚的プロンプトには環境条件の変化に対して汎化しない可能性のある慎重に選択された参照ボックスが必要です。
VLMによる点検
Vision-Language Models——Qwen2-VL [9]、InternVL [10]、LLaVA-OneVision [11]——は根本的に異なるアプローチを採ります。プロンプトからバウンディングボックスを生成するのではなく、自然言語を通じて画像について推論を行います。VLMに「この電柱に何か異常はありますか?」と尋ねると、異常の内容、その推定原因、おおよその位置を記述した構造化された回答が得られます。
産業用異常検出におけるVLMの進化は急速です。AnomalyGPT(AAAI 2024)は、正常な参照画像が1枚あるだけで、VLMがMVTec-AD(産業用異常検出の標準ベンチマーク)において86.1%の精度と94.1%の画像レベルAUCを達成し、さらにマルチターンの診断対話をサポートできることを実証しました [12]。LogicAD(AAAI 2025)は論理的異常(部品の欠落、配置の誤り)に取り組み、MVTec LOCO ADで86.0%のAUROCを達成し、従来手法から18.1%の改善を示しました [13]。InfraGPT(2025)は、都市インフラの欠陥検出と管理のためのエンドツーエンドのVLMベースフレームワークを実証しました [14]。
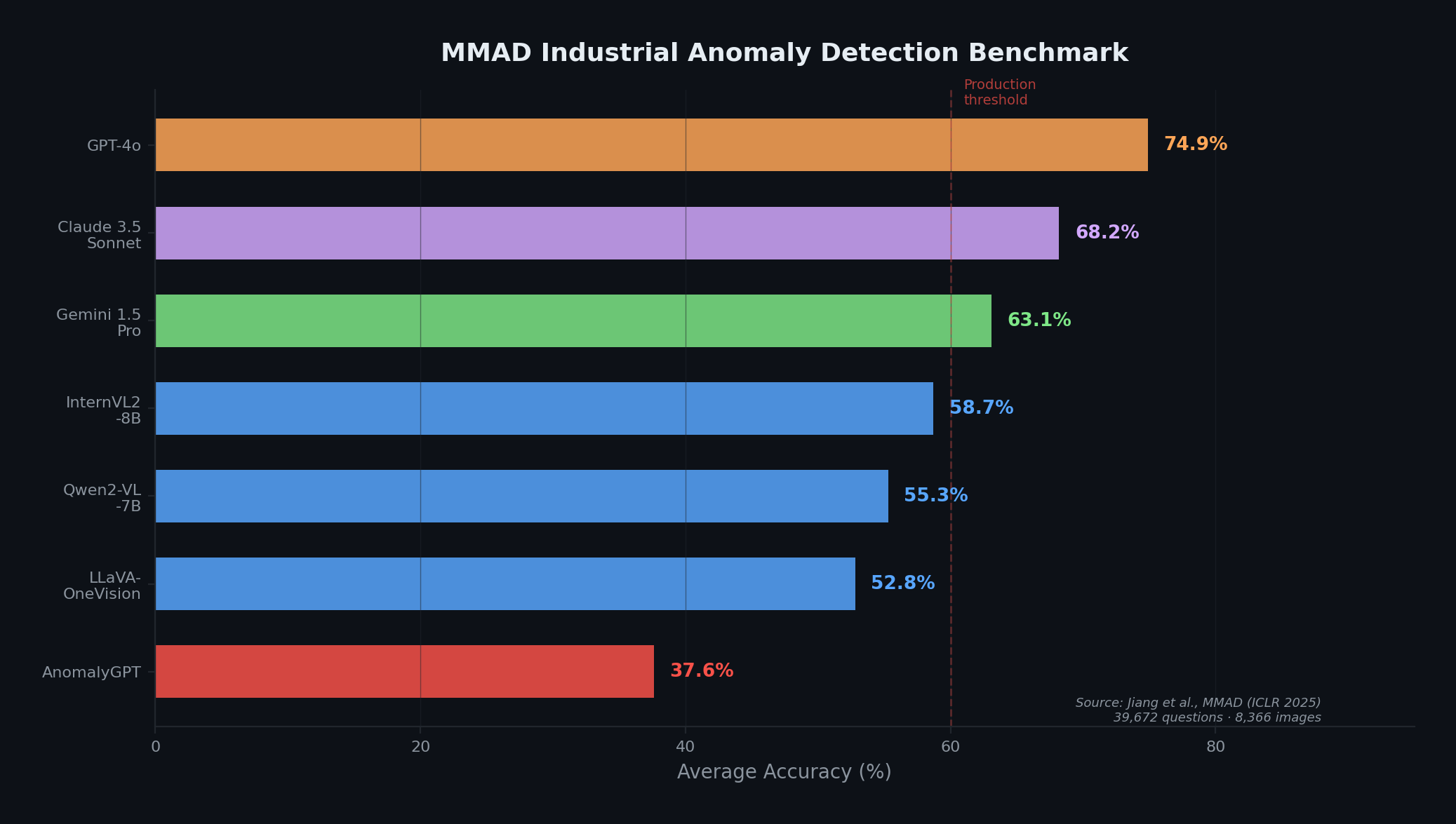 MMADベンチマーク(ICLR 2025)は、産業用異常検出におけるVLMの最も包括的な評価であり、最高性能のモデルでも大幅な改善の余地があることを明らかにしています。フロンティアAPIモデルとオープンウェイトモデルの間のギャップが、ドメイン特化型の適応の必要性を示しています。データはJiang et al. [15]より。
MMADベンチマーク(ICLR 2025)は、産業用異常検出におけるVLMの最も包括的な評価であり、最高性能のモデルでも大幅な改善の余地があることを明らかにしています。フロンティアAPIモデルとオープンウェイトモデルの間のギャップが、ドメイン特化型の適応の必要性を示しています。データはJiang et al. [15]より。
しかし、MMADベンチマーク(ICLR 2025)——8,366枚の産業画像にまたがる39,672問からなる、現時点で最も厳密な評価——は、GPT-4oでさえMMADの質問応答タスク全体で平均精度が74.9%にとどまることを明らかにしました [15]。これは厳しい結果ですが、同時に示唆に富んでいます。VLMの素の能力だけでは不十分であり、本番利用にはドメイン特化型の適応が不可欠であるということです。さらに重要な点として、VLMはなぜそれが異常であるかの自然言語による説明をネイティブに提供します。これはopen-set検出器単体では提供できない能力であり、人間が介在する点検ワークフローにおいて極めて重要です。
VLMを中心としたソリューションスタック
研究フェーズの成果に基づき、3つの適応モードを備えたVLM中心の点検スタックを設計しました。各モードは独立して展開可能ですが、組み合わせて使用することも想定されています。例えば、LoRAでfine-tuningしたモデルに、推論時にRAGをさらに付加することが可能です。3つのモードはデプロイの成熟度の異なる段階に対応しており、段階的に導入できます。
 3つの適応モードは、デプロイの成熟度の異なる段階に対応しています。In-context learningは初日からの運用を可能にし、LoRA fine-tuningは本番環境の安定性を提供し、Visual RAGは再学習なしにドメイン知識を付加します。
3つの適応モードは、デプロイの成熟度の異なる段階に対応しています。In-context learningは初日からの運用を可能にし、LoRA fine-tuningは本番環境の安定性を提供し、Visual RAGは再学習なしにドメイン知識を付加します。
In-context learning:即時展開
新しいコーナーケースが特定された場合——例えば、これまで見たことのないタイプの碍子の損傷——in-context learningによって即座にシステムに組み込むことができます。参照画像(正常および欠陥あり)を、注意深く設計された指示テンプレートとともにVLMプロンプトに直接配置します。Ueno et al.(2025)は、fine-tuned ViP-LLaVAを使用したsingle-shot ICLがMVTec-ADでMCC 0.804、F1スコア0.950を達成し、専門モデルと同等の性能を示すことを実証しました [16]。ユークリッド距離ベースの例選択がコサイン類似度ベースのRICESを上回るという彼らの発見は、検索システムの設計に実用的な示唆を与えます。
トレードオフは明確です。ICLは学習計算コストがゼロですが、高解像度の点検画像1枚あたり2,000〜4,000の視覚トークンを消費し、コンテキストウィンドウを急速に埋めてしまいます。性能は通常、参照画像4〜8枚程度で頭打ちになります。
Few-shot fine-tuning:本番環境の安定性
安定した再現性のある挙動が求められる定常的な点検業務では、LoRA fine-tuning(Low-Rank Adaptation)がTransformerの注意機構層に小さな分解行列を導入し、ベースの重みを固定したまま全パラメータのわずか0.1〜0.5%のみを学習します [17]。QLoRAはさらにベースモデルを4-bit NF4形式に量子化し、VRAM要件を大幅に削減します。Qwen2.5-VL-7Bの場合、QLoRA rank 8であれば単一GPUで約16〜24 GBのVRAMでfine-tuningが可能です。
データ要件は驚くほど少量で済みます。低リソースの産業環境におけるLoRAの有効性を示す間接的な証拠として、PLG-DINO(2025)は、LoRAでfine-tuningしたGrounding DINOが、少数データの産業欠陥検出シナリオにおいて全てのYOLO派生モデルを上回ることを実証しました [18]。ただし、この結果はopen-set検出器に関するものであり、VLMではないため、VLMのfine-tuningへの直接的な転用は検証なしに想定すべきではありません。私たち自身のVLM実験では、500〜2,000のラベル付きサンプルでzero-shotベースラインから大幅な改善が得られ、5,000サンプルを超えると改善効果は逓減しました。生成されるアダプタの重みはわずか200〜400 MBであり、フルモデルの14 GB以上と比較して、バージョン管理やA/Bテストが容易です。
RAG:ドメイン知識による根拠づけ
クライアントが内部知識——欠陥カタログ、エンジニアリングガイドライン、過去の類似事例——を保有している場合、retrieval-augmented generationは推論時にこのコンテキストを動的に注入します。既知の欠陥画像はCLIPまたはDINOv2のembeddingを用いてベクトルデータベースにインデックスされ、クエリ画像ごとに視覚的に最も類似したtop-kの事例が検索されてVLMプロンプトに注入されます。VisRAGは、ドキュメントを画像として直接embeddingすることで、テキストベースのRAGに対して20〜40%のエンドツーエンド性能向上を実証しました [19]。ただし、Wallace et al.のInspectVLM研究(2025)は注意を促す反例を提示しています。統合型VLMアーキテクチャは理論的には魅力的ですが、慎重なドメイン固有の適応なしには、点検領域が変わると信頼性が大幅に低下します [20]。風力タービンブレード点検におけるRAG強化VLMに関する別の研究(2025)では、検索による根拠づけが、ベースモデル単体では性能が低かったケースにおいて分類精度を大幅に向上させたことが報告されています [21]。
RAGの際立った利点はトレーサビリティの向上です。全ての出力を特定の検索された根拠に遡ることができ、規制の厳しい点検の現場における人間のレビューに寄与します。ただし、トレーサビリティは厳密な監査可能性と同義ではありません。VLMの最終出力が検索された根拠に忠実であるとは限らず、検索された事例がモデルの推論を完全に制約するわけでもありません。実運用では、RAGはレビュー容易性を大幅に改善し、有用なエビデンスの追跡を可能にしますが、重要な意思決定における人間の判断の必要性を排除するものではありません。
vLLM:これを実用化するサービングエンジン
VLMを中心とした点検スタックは、推論が本番ワークロードに対して十分に高速かつメモリ効率的である場合にのみ実現可能です。vLLMは、2つの核心的イノベーション——PagedAttentionと連続バッチング——によってこれを実現しています [22][23]。
PagedAttentionがKV cacheのボトルネックを解消
自己回帰生成の過程で、モデルは全ての前方トークンに対するkeyおよびvalueの行列(KV cache)を保持する必要があります。高解像度画像を処理するVLMにとって、これは特に負荷が大きくなります。私たちのQwen2-VL-7B(FP16 KV cache、28層、4 KVヘッドのGQA、128次元ヘッド)のプロファイリング結果では、1トークンあたり約0.03 MBのオーダーでKV cacheが生成されるため、1024×1024の画像1枚が約4,096の視覚トークンを生成する場合、KV cacheだけでおよそ100 MB以上を消費し得ます。
従来のサービングシステムは各シーケンスに連続的なメモリブロックを事前割り当てしており、フラグメンテーションと過剰予約によってKV cacheメモリの60〜80%を浪費していました [22]。
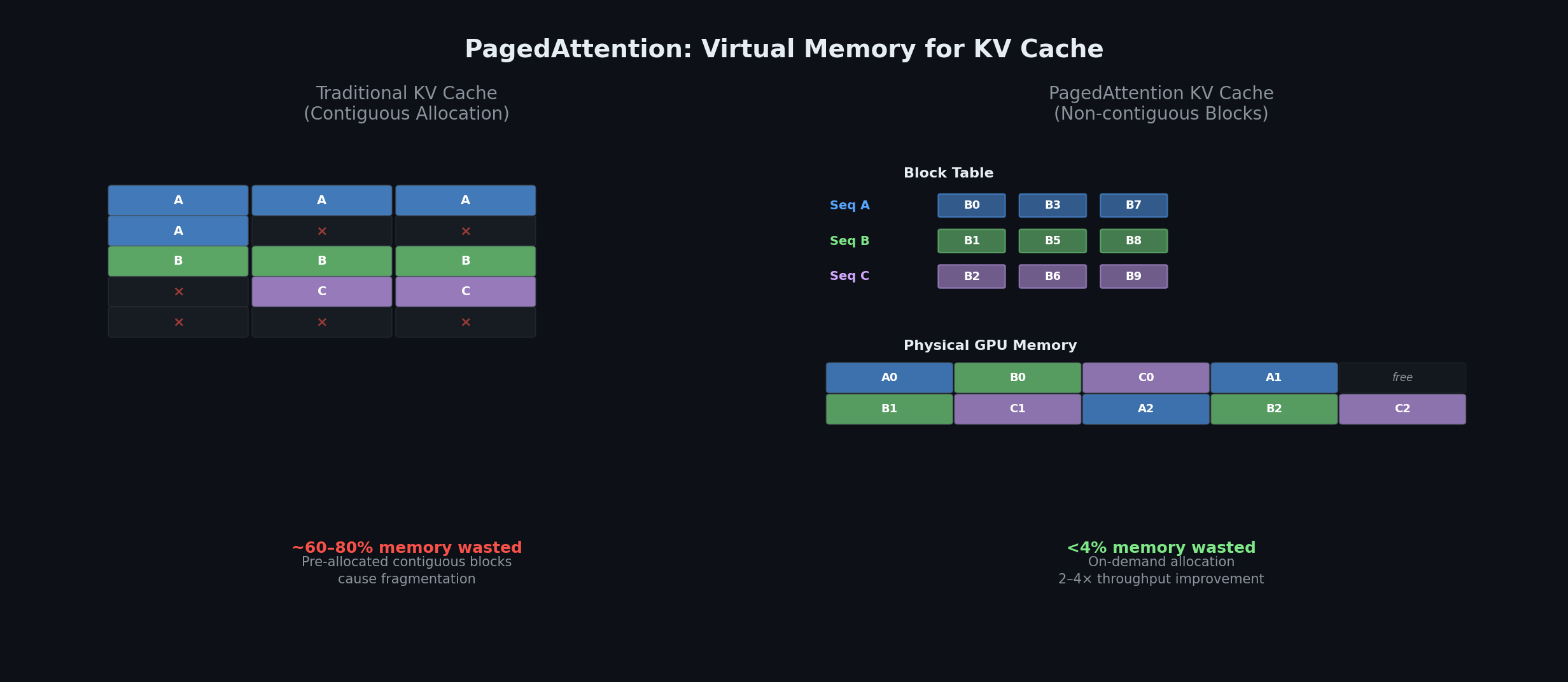 PagedAttentionはオペレーティングシステムの仮想メモリの概念を借用しています。連続的なメモリを事前割り当てする代わりに、KV cacheブロックを非連続的な物理メモリに格納し、ブロックテーブルを通じてマッピングします。これによりメモリの無駄が60〜80%から4%未満に削減され、2〜4倍のスループット向上が実現されます [22]。
PagedAttentionはオペレーティングシステムの仮想メモリの概念を借用しています。連続的なメモリを事前割り当てする代わりに、KV cacheブロックを非連続的な物理メモリに格納し、ブロックテーブルを通じてマッピングします。これによりメモリの無駄が60〜80%から4%未満に削減され、2〜4倍のスループット向上が実現されます [22]。
PagedAttentionはKV cacheを固定サイズのブロック(通常は16トークン単位)に分割し、GPUメモリ上に非連続的に配置可能にします。各シーケンスは論理ブロックを物理ブロックにマッピングするブロックテーブルを維持しており、これはOSの仮想メモリにおけるページテーブルに相当します。物理ブロックはオンデマンドで割り当てられ、共通プレフィックスに対してはcopy-on-write方式で共有されます。その結果、メモリの無駄は4%未満となり、従来のシステムに対して2〜4倍のスループット向上が実現されます [22]。
連続バッチングによるGPU利用率の最大化
従来の静的バッチングでは、バッチ内の全リクエストが最も遅いシーケンスの完了を待つ必要があり、GPUサイクルを浪費していました。vLLMの連続バッチングはイテレーションレベルの粒度で動作します。デコードステップごとに、スケジューラが完了したシーケンスを除去し、待機中のリクエストを即座に挿入します。ベンチマークでは、HuggingFace Transformersに対して14〜24倍、Text Generation Inferenceに対して2.2〜3.5倍のスループット向上が示されています [22]。
vLLM V1におけるVLM固有の最適化
vLLM V1(2025)は、重要なマルチモーダル機能を導入しました [24]。エンコーダキャッシュは計算済みのvision embeddingをGPU上に保存し、類似するプロンプト間でvisionエンコーダの冗長な再実行を排除します。vLLM V1のドキュメントによれば、メタデータ強化プレフィックスキャッシュは単なるトークンIDではなく画像コンテンツのハッシュを使用し、同じ<image>プレースホルダを共有する異なる画像間のキャッシュ衝突を防止します。ハイブリッド並列化フラグ(--mm-encoder-tp-mode data)は、visionエンコーダをデータ並列で実行し、言語モデルをテンソル並列で実行することで、vision encoding時のall-reduce通信を削減します。
Red Hatの開発者チームが報告した4×H100 GPU上のMolmo-72Bに対するベンチマークでは、V1はV0に対して約40%のスループット向上を達成しています [24]。AMDのROCmチームも独立して、データ並列でのvision encodingの有効化が、画像の多い推論ワークロードにおいて大幅な速度向上をもたらすことを確認しています [25]。
本番展開:GPU選定からパイプラインアーキテクチャまで
本プロジェクトの最終フェーズでは、実際のリソース制約の下でのオンプレミス展開に向けた運用化に焦点を当てました。
GPUメモリとハードウェア選定
VLMは、visionエンコーダの重み、視覚トークンのembedding、クロスモーダル注意機構により、テキストのみのモデルと比較して追加のVRAMを消費します。具体的な要件(私たちの見積もり)として、Qwen2-VL-7BはFP16で約16〜17 GB(単一のL40Sに収まり、KV cache用の余裕もあり)、INT8では8〜9 GBに削減されます。Qwen2-VL-72BはFP16で約144 GBを必要とし、FP8量子化で4×A100-80GBに収まります。min_pixels/max_pixelsパラメータを制約せずに高解像度画像を処理すると、24 GB GPUでメモリ不足エラーが発生するとの報告があります [9]。
私たちの産業用点検ワークロードにおいて、NVIDIA L40S(48 GB GDDR6)はメモリ容量、推論スループット、調達コストのバランスに優れており、7B VLMをフル精度で処理しつつKV cache用の十分な余裕を確保できました。1日あたり約1,000枚の画像を処理するワークロードでは、私たちの構成ではL40S 1台で十分でした。コストモデリングに基づくと、ハードウェア購入費用はクラウドコストに対しておよそ7〜10か月で損益分岐点に達しますが、クラウドの価格帯や利用率のパターンによって大きく変動します。
高解像度点検画像の処理
産業用カメラは4K以上の解像度で撮影しますが、VLMの入力制限にはインテリジェントなタイリングが必要です。Qwen2-VLの675Mパラメータ ViTは、min_pixelsとmax_pixelsにより制御される可変トークン数でネイティブ解像度の画像を処理します [9]。InternVLは画像を448×448のタイルに分割し(1〜40タイル、最大4Kに対応)、pixel shuffleにより各タイルを256の視覚トークンに削減し、コンテキスト維持のためのグローバルサムネイルを追加します [10]。
4K点検画像に対する推奨アプローチは以下の通りです。まず、制限付きの解像度にリサイズ(長辺2048〜4096 px)し、欠陥の位置特定のためにスライディングウィンドウクロップを使用します。グローバルなコンテキスト把握のために全体画像を低解像度で処理し、関心領域の高解像度クロップと組み合わせます。最後に、non-maximum suppressionによりタイル間の結果を集約します。
ハイブリッドパイプライン
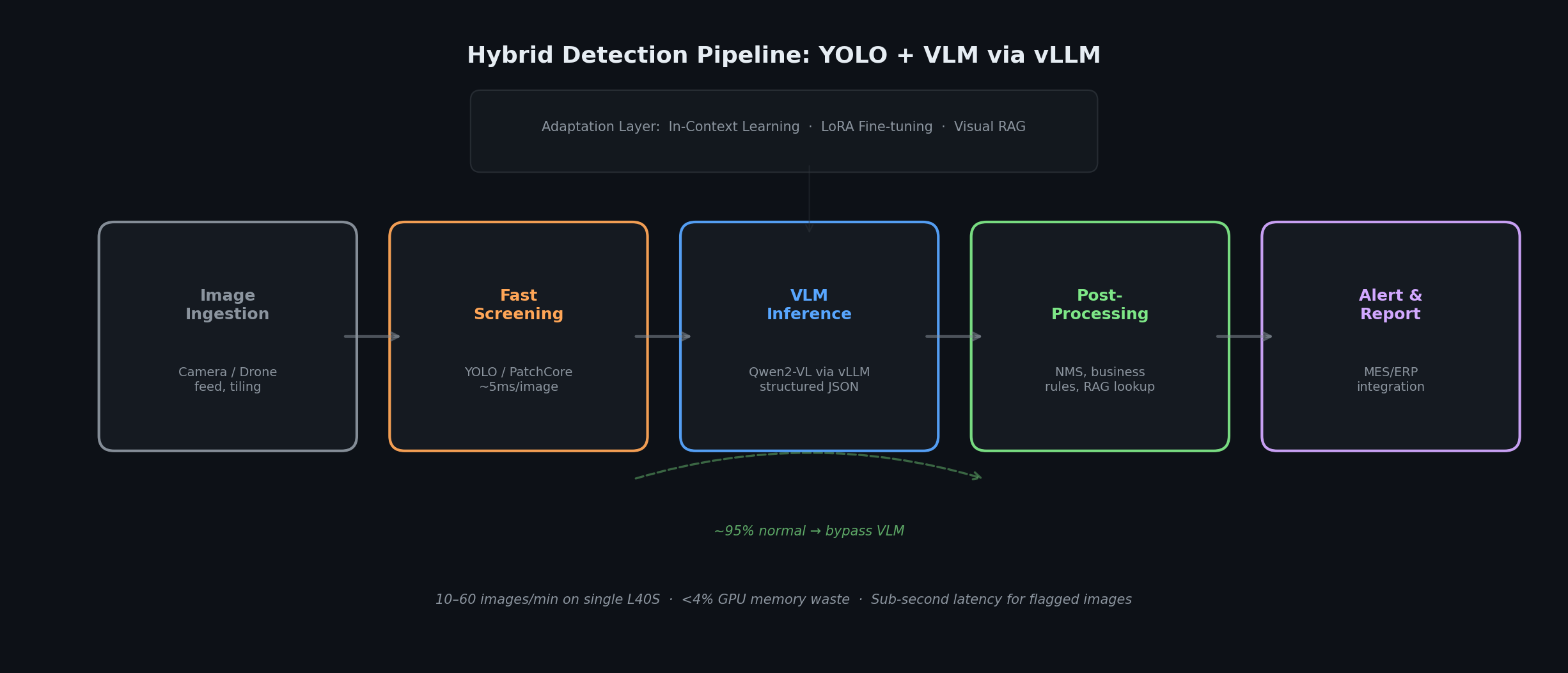 本番パイプラインは、高速な一次スクリーナーとVLMの推論を組み合わせます。私たちのデプロイでは、約85〜95%の画像が一次スクリーナーでフィルタリングされ(ドメインと異常率に依存)、VLM推論量を7〜20倍削減しました。実際の比率は、フラグ付き異常とともにVLMに送られる不確実なケースやボーダーラインケースの割合に依存します。
本番パイプラインは、高速な一次スクリーナーとVLMの推論を組み合わせます。私たちのデプロイでは、約85〜95%の画像が一次スクリーナーでフィルタリングされ(ドメインと異常率に依存)、VLM推論量を7〜20倍削減しました。実際の比率は、フラグ付き異常とともにVLMに送られる不確実なケースやボーダーラインケースの割合に依存します。
最適な本番アーキテクチャは速度と深度を両立します。カメラやドローンからの画像取り込みが、リサイズ、正規化、タイリングを行う前処理サービスに流れます。軽量な一次スクリーナー(YOLOなどの物体検出器、PatchCoreなどの異常検出手法、SigLIPなどのvision-languageエンコーダ)が明らかに正常なケースをフィルタリングします。ここで重要なのは、このスクリーナーは高い適合率ではなく、高い再現率にチューニングすべきだという点です。スクリーナーの役割は、明らかに正常な画像のみを確信を持って除外し、不確実なケースやボーダーラインのケースは全てVLMに送ることです。一次段階を適合率重視に積極的にチューニングしてしまうと、VLMが検出すべきまさにそのコーナーケースをフィルタリングしてしまうリスクがあり、ハイブリッドアーキテクチャの目的が損なわれます。私たちのデプロイでは、スクリーナーの動作点を意図的に低い閾値以上の異常スコアを持つ全画像を保持するよう設定し、加えて設定可能な割合の「不確実な」サンプルも保持しました。VLMはOpenAI互換APIを備えたvLLMでサービングされ、フラグが立った画像のみを構造化されたシステムプロンプトを使用して処理し、欠陥タイプ、位置座標、重大度、自然言語による根拠を含むJSONを返します。後処理ではマルチタイルの結果を集約し、ビジネスルールを適用し、欠陥カタログとの照合を行います。アラートは既存のMES/ERPシステムと統合されます。
このワークロードにおけるvLLMの主要な設定は以下の通りです。--gpu-memory-utilization 0.9で利用可能なKV cacheを最大化し、点検間で繰り返されるシステムプロンプトに対してprefix cachingを有効にします。--limit-mm-per-prompt "image=5"でリクエストあたりのメモリを制限し、chunked prefillにより長い画像プロンプトが既存リクエストのデコードをブロックするのを防ぎます。
単一のL40S上でQwen2.5-VL-7Bを使用した場合、私たちのテストではVLMステージで画像解像度と出力長に応じて毎分約10〜60枚の処理が可能でした。ハイブリッドアプローチにより、個々のフラグ付き画像に対してサブ秒のレイテンシが達成可能です。
結果と今後の展望
本プロジェクトでは、極端なデータ不足の状況下でのコーナーケース検出への実用的な道筋を確立しました。言語的な定義のみの段階からラベル付き事例が利用可能な段階まで、複数の運用上の現実に対応するワークフローを構築しています。
3つの知見が私たちのアプローチを形作りました。第一に、ハイブリッドアーキテクチャは本プロジェクトにおいて最も優れた設計であることが証明されました。このパターンは、異常率が低い画像中心の類似の点検ワークロードにも適用可能であると考えていますが、これは単一プロジェクトの知見にとどまります。ミリ秒レベルのレイテンシで動作する高速な一次スクリーナーが正常画像の大多数(私たちのデプロイでは85〜95%)をフィルタリングし、VLMが従来の検出器では構造的に対応できないコーナーケースに必要な推論の深さを提供します。
第二に、ベースモデルよりも適応スタックの方が重要です。私たちのデプロイでは、1,000のドメイン固有サンプルでLoRAによりfine-tuningされ、Visual RAGで補強された7B VLMが、対象の点検タスクにおいて素のフロンティアモデルを大幅に上回りました。ただし、これは単一プロジェクトの知見であり、制御されたベンチマーク結果ではないことに留意が必要です。段階的なアプローチ——数日でのzero-shot展開、数週間でのLoRA fine-tuning、数か月でのドメイン特化——は、即座に価値を提供しながら本番レベルの精度構築に向けて進展させることを可能にします。
第三に、私たちのような画像中心の点検ワークロードにおいて、vLLM V1のマルチモーダルイノベーションはVLMベース推論の経済性を大幅に改善しました。エンコーダキャッシュ、ハイブリッド並列化、メタデータ強化プレフィックスキャッシュは、画像の多いワークロードのメモリおよびスループットの課題に特化して対応しています。
残された課題は精度です。最高性能のVLMでもMMADの産業用ベンチマークにおける精度は74.9%にとどまり [15]、現在の手法の限界を露呈するために設計された新しいデータセットMVTec AD 2では、最先端手法でも平均AU-PROが60%を下回っています [26]。ドメイン特化型fine-tuning、点検フィードバックからの強化学習(EMIT [27]や類似の強化学習アプローチで実証された手法)、そして現場の性能を最大限に向上させるラベリングを優先する能動学習ループを通じて、このギャップを埋めること——これが2025〜2026年において最もインパクトの大きい取り組み領域です。
参考文献
[1] Shihavuddin et al. "Barely-Visible Surface Crack Detection for Wind Turbine Sustainability." arXiv:2407.07186, 2024.
[2] Baitieva et al. "Supervised Anomaly Detection for Complex Industrial Images." CVPR 2024.
[3] Li et al. "Surface Defect Detection Methods for Industrial Products with Imbalanced Samples: A Review of Progress in the 2020s." Knowledge-Based Systems, 2024.
[4] Zhang et al. "Deep Learning in Automated Power Line Inspection: A Review." arXiv:2502.07826, 2025.
[5] Jiang et al. "T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy." ECCV 2024. arXiv:2403.14610.
[6] Liu et al. "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection." ECCV 2024. arXiv:2303.05499.
[7] Ren et al. "DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding." arXiv:2411.14347, 2024.
[8] Cheng et al. "YOLO-World: Real-Time Open-Vocabulary Object Detection." CVPR 2024. arXiv:2401.17270.
[9] Wang et al. "Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution." arXiv:2409.12191, 2024.
[10] Chen et al. "InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks." CVPR 2024.
[11] Li et al. "LLaVA-OneVision: Easy Visual Task Transfer." arXiv:2408.03326, 2024.
[12] Gu et al. "AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models." AAAI 2024 (Oral). arXiv:2308.15366.
[13] Kim et al. "LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction." AAAI 2025.
[14] Alani et al. "InfraGPT Smart Infrastructure: An End-to-End VLM-Based Framework for Detecting and Managing Urban Defects." arXiv:2510.16017, 2025.
[15] Jiang et al. "MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection." ICLR 2025. arXiv:2410.09453.
[16] Ueno et al. "Vision-Language In-Context Learning Driven Few-Shot Visual Inspection Model." arXiv:2502.09057, 2025.
[17] Hu et al. "LoRA: Low-Rank Adaptation of Large Language Models." ICLR 2022. arXiv:2106.09685.
[18] Chen et al. "PLG-DINO: Industrial Defect Detection via Prompt-Learning Grounding DINO." OpenReview, 2025.
[19] Yu et al. "VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents." arXiv:2410.10594, 2024.
[20] Wallace et al. "InspectVLM: Unified in Theory, Unreliable in Practice." ICCV 2025 Workshop. CVF.
[21] "RAG-enhanced visual language model for wind turbine blade inspection." IFAC-PapersOnLine, 2025. ScienceDirect.
[22] Kwon et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP 2023. arXiv:2309.06180.
[23] vLLM Project. https://github.com/vllm-project/vllm
[24] Red Hat Developer. "vLLM V1: Accelerating Multimodal Inference for Large Language Models." 2025.
[25] AMD ROCm Blogs. "Accelerating Multimodal Inference in vLLM: The One-Line Optimization for Large Multimodal Models." 2025.
[26] Bergmann et al. "The MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection." arXiv:2503.21622, 2025.
[27] Li et al. "EMIT: Enhancing MLLMs for Industrial Anomaly Detection via Difficulty-Aware GRPO." arXiv:2507.21619, 2025.