
AI アニメ制作リサーチ · 2026年2月
SNSのフィードを開けば、AIが生成した息を呑むようなアニメクリップがすぐに見つかります。雨に濡れた都市景観を駆け抜ける輝く瞳のキャラクター、パーティクルエフェクトの中で旋回するメカスーツ——すべてプロンプトを入力するだけで数秒で生成されます。この技術は確かに印象的です。しかし、実際にアニメを制作しているスタジオのプロのアニメーター——毎週24分のエピソードを納品し続ける人々——に話を聞くと、これらのツールを制作現場で使えている人はほぼ皆無です。この断絶は一時的な不便ではありません。生成AIが今どこに位置しているのか、そして本当に実用的になるために何が必要なのかという本質的な問題を浮き彫りにしています。
私たちは最新世代のAIアニメーションツールを、実際のアニメ制作パイプラインの要件と照らし合わせて詳細に評価してきました。結論として、「制御性ギャップ(controllability gap)」が存在します——生成モデルが最適化している対象(個々の出力の視覚的な印象度)と、制作現場が求めるもの(数千フレームにわたるすべての要素に対する正確で再現可能な制御)との間の構造的な不一致です。このギャップこそが、AIがデモのショーケースから制作ツールへと進化することを阻む最大のボトルネックです。なぜこのギャップが存在するのか、そしてそれを埋めるために何が必要なのかを理解することは、アニメに限らず——精度を求め、もっともらしさだけでは不十分なあらゆるクリエイティブパイプラインに生成AIがいつ参加できるようになるのかという、より広い問いにつながります。
アニメ制作における「制御性」の実際の意味
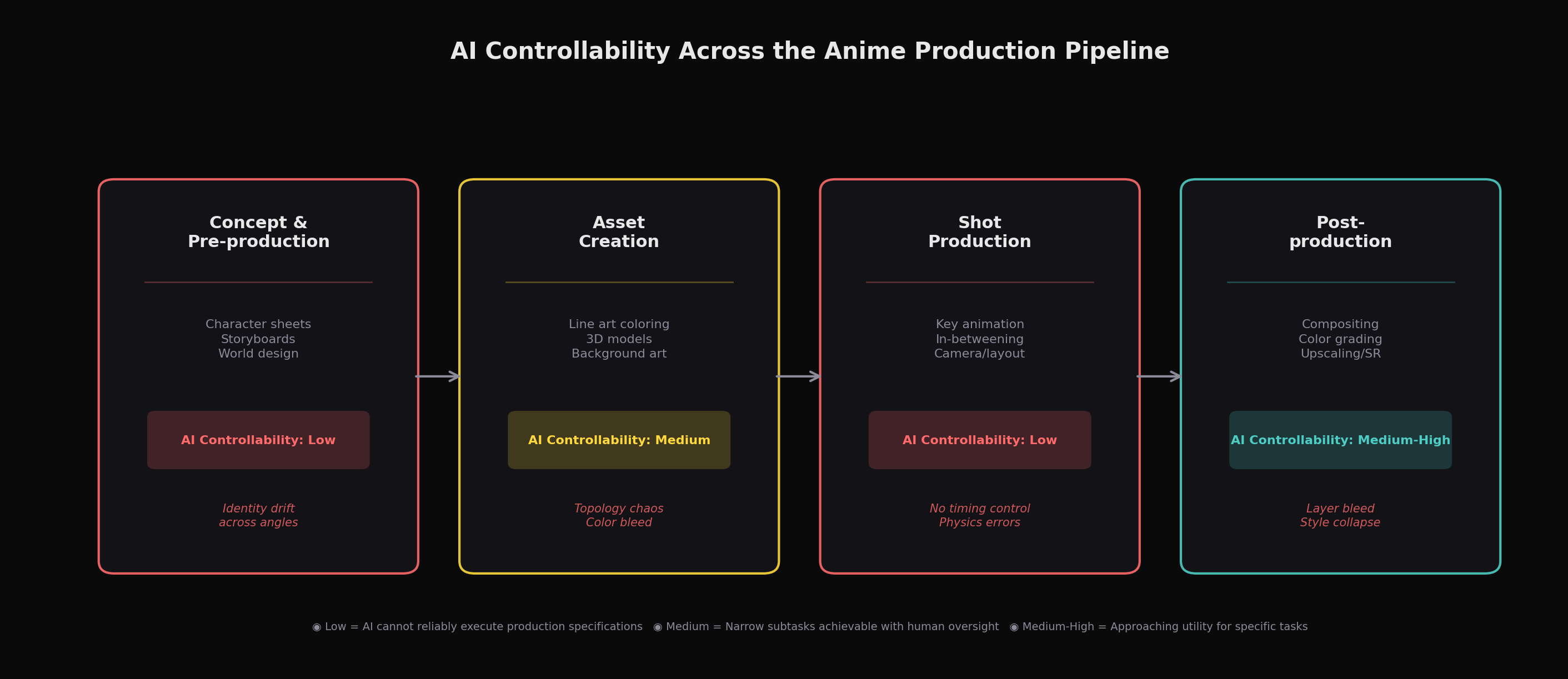
このギャップを理解するには、まずアニメ制作が実際に何を必要としているかを理解する必要があります。「制御性」という言葉は抽象的に聞こえるかもしれませんが、現場のスタジオではパイプラインの各段階で極めて具体的な要求に変換されます。
プリプロダクションでは、キャラクターデザイナーが設定画(モデルシート)を作成します。これは複数のアングルからキャラクターを描いたターンアラウンドで、プロポーション、線の太さ、カラーパレット、表情の幅が正確に指定されています。その後のすべてのアニメーションフレームは、これらの設定画に忠実でなければなりません。原画を描くアニメーターは「もっともらしいアニメキャラクター」を生成しているのではなく、左目が右目からちょうど頭部幅の1.3倍の位置にあり、髪が特定のシルエットで落ち、衣服のしわが確立された規則に従う特定のキャラクターを描いています。これが「キャラが崩れない(on-model)」ということであり、スタジオでは作画監督というチーム全体がモデルから逸脱した描画を修正する仕事を担っています。
制作フェーズでは、レイアウトアーティストが正確なカメラポジションを指定します。多くの場合、ドリーの軌道や焦点距離を定義する3Dプリビズと連携して行われます。原画マンがモーションの極端なポーズ(「原画」)を描き、動画マンが中間フレームを埋めます。ここで重要な芸術的判断はタイミングです。アニメでは「2コマ打ち」(1枚の絵を2フレーム分表示し、1秒あたり12枚のユニークな絵になる)、さらには「3コマ打ち」で作画することが多く、速いアクションで「1コマ打ち」に切り替えるタイミングの選択は、シーンの雰囲気を決定する意図的な創造行為です。キーポーズ間のスペーシング——フレームごとにキャラクターの腕がどれだけ動くか——が重量感、感情、物理法則を伝えます。これらの判断は装飾的なものではなく、アニメーションそのものです。
ポストプロダクションにも独自の制御要件があります。アニメにおけるコンポジットは単に要素を重ねるだけではなく、個別のセルレイヤー(キャラクター、背景、エフェクト)をそれぞれ特定の不透明度、ブレンドモード、カラーグレーディングで精密に管理することを意味します。これらのレイヤー境界を尊重しないスタイル変換やアップスケーリングツール——キャラクターの影を背景のグラデーションに滲ませたり、意図的にフラットなセルシェーディング領域を滑らかにしてしまうもの——は、節約する以上のクリーンアップ作業を生み出します。
核心的な問題はこうです。アニメ制作は、芸術の形を借りたエンジニアリング領域であるということです。 あらゆる創造的判断は仕様でもあり、あらゆる仕様は何十人ものアーティストによって何百、何千フレームにわたって再現可能でなければなりません。一方、生成AIはプロンプトに対して統計的にもっともらしい出力を生成するように設計されていますが、「もっともらしい」と「正確に仕様通り」は根本的に異なる目標です。
根拠:現在のツールはどこで不足しているか
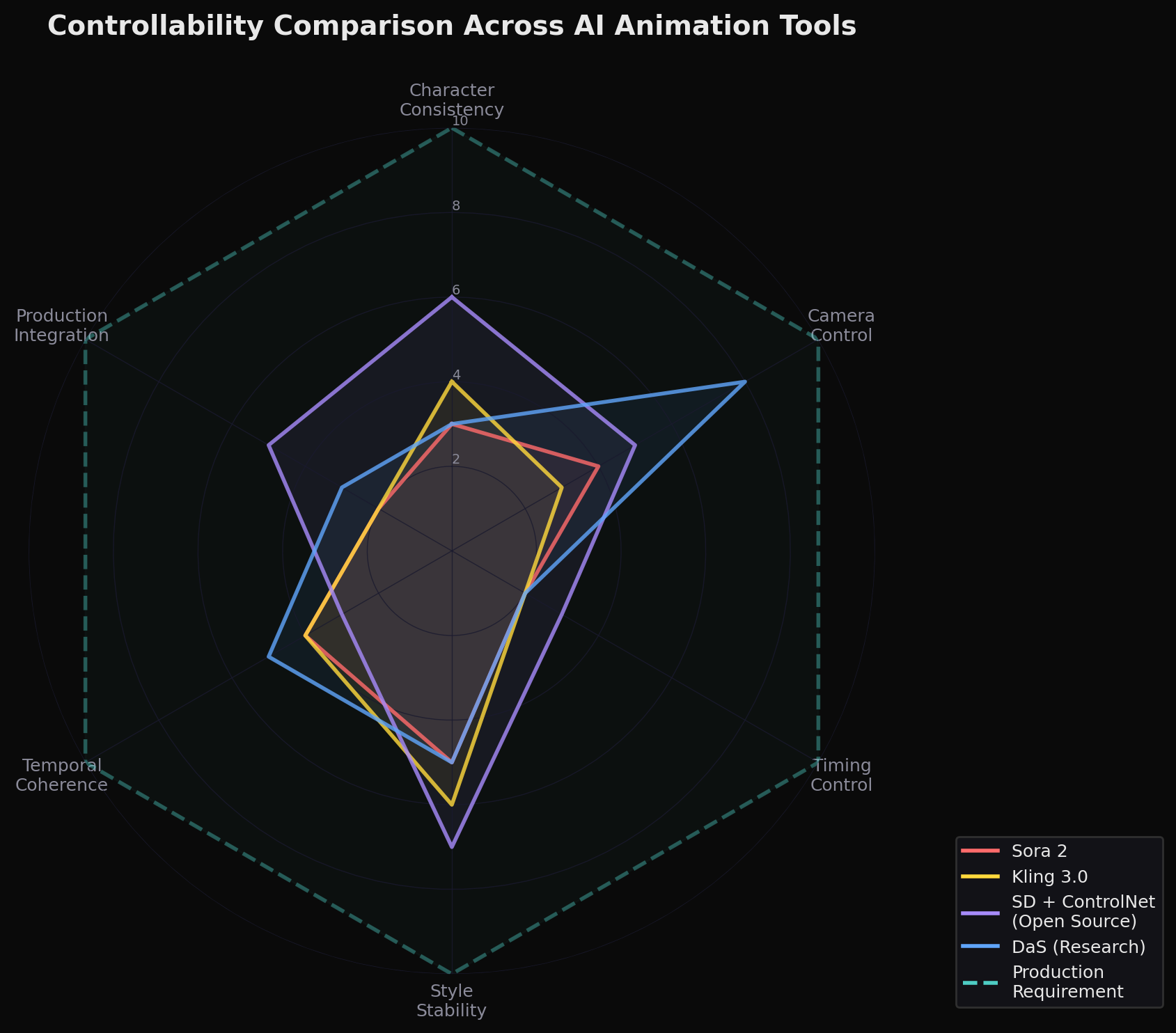
パイプラインのすべての段階にわたって最新世代のツールを検証し、上述の制作要件——ショット間のキャラクターアイデンティティの一貫性、カメラの精度、時間的安定性、レイヤーレベルのコンポジット制御——と照らし合わせて評価しました。手法は定性的なもの——制作パイプラインに精通した実務者による構造化されたハンズオンテストであり、統制されたプロンプトとブラインド評価による正式なベンチマークではありません。この前提のもとで、パターンは一貫していました:個々の出力は印象的ですが、制作レベルの制御は不十分です。
動画生成モデルはショット間でのキャラクターアイデンティティの維持に大きな困難を抱えています。 Sora 2、Kling 3.0、Runway Gen-4.5、Seedance 2.0、Luma Ray3、Vidu Q1のアニメスタイル生成をテストしました。いずれも5〜20秒の視覚的に印象的なアニメクリップを生成できます。Kling 3.0の「Stylistic Omni」エンジンはアニメのプロポーションとモーションに明示的にチューニングされています。Viduはアニメ最適化を謳い、Aura Productionsと提携して50話のAIアニメシリーズを制作しています。Sora 2の公式ドキュメントは「アニメスタイルに優れている」と主張しています。
しかし、これらのモデルはいずれも、複数のショットにわたってキャラクターのアイデンティティを確実に保持することができません——これは単一のシーン、ましてやエピソード全体にとって最低限の要件です。カット間で細かいディテールが消えます:腕時計、イヤリング、衣装のアクセサリー。さらに深刻なのは、Runway Gen-4をアニメシーンの連続性テストにかけた際、私たちがスタイル崩壊(style collapse)と呼ぶ現象が観察されたことです——キャラクターが生成中にアニメからセミリアリスティックなレンダリングに自発的に遷移してしまいました。Klingは直接比較でアニメの様式的一貫性をより良く維持しましたが、手描きアニメーションが設計上実現しているフレームレベルのアイデンティティ保持を保証することはできませんでした。根本的な問題はアーキテクチャにあります:diffusionモデルは学習した分布からサンプリングし、各サンプルは部分的に独立しています。現在のモデルはフレーム間のアイデンティティ保持に大きな困難を抱えていますが、DaSのような新しいアプローチは、ターゲットを絞ったアーキテクチャソリューションがこのギャップを部分的に解消できることを示しています。時間的境界を超えてアイデンティティを強制する明示的なコンディショニングメカニズムがなければ、ドリフトは依然として根強い課題です。
カメラ制御は依然として不正確です。 アニメの撮影は非常に意図的なものです——都市景観をゆっくりとパンする、キャラクターの目にスナップズームする、走る人物を追うトラッキングショットなど。最近の研究はここで実際に進歩を遂げています。Diffusion as Shader(DaS)はHKUST、NTUなどによるSIGGRAPH 2025の論文で、3Dトラッキング信号を使用した統一アーキテクチャにより、単一のフレームワーク内でカメラ制御、オブジェクト操作、モーション転送を実現します。重要な洞察はエレガントです:ダイナミックな3Dポイントを座標に応じて色付けして「トラッキングビデオ」を生成することで、DaSは従来の手法が依存していた2Dヒューリスティクス(深度マップ、オプティカルフロー)ではなく、3D対応の制御信号にdiffusionを基盤づけます。I2VControl-Camera(ICLR 2025)は異なるアプローチを取り、カメラ座標空間のポイント軌跡を使用してカメラの動きとオブジェクトの動きを分離します。
これらは真の進歩です。しかし、現時点で公開されている中で最も洗練された制御フレームワークと言えるDaSでさえ、依然として生成パラダイムの中で動作しています。従来のものよりも大幅に優れたガイダンスを提供しますが、決定論的なレンダリングを保証することはできません。3秒間のドリーインが35mm換算の焦点距離で終わるように指定するアニメーション監督は、その仕様が毎回正確に実行されることを必要としています。「MotionCtrlより大幅に優れている」は「プロダクションレディ」と同義ではありません。
着色ツールは限定的な問題をうまく解決しますが、より広い限界を明らかにします。 MangaNinjaはAlibaba、HKU、HKUSTによるCVPR 2025 Highlightの論文で、真に印象的なリファレンスガイド付き線画着色を実証しています。そのデュアルブランチアーキテクチャ——リファレンスU-Netとローカルな対応学習を強制するパッチシャッフリングモジュールの組み合わせ——は、極端なポーズ変化を超えてもキャラクターのカラーアイデンティティを維持できます。インタラクティブなポイントベースのガイダンスシステムにより、アーティストはリファレンスとターゲット間のマッチングポイントを指定でき、従来の自動化アプローチよりもはるかに高い制御性を実現します。
これはおそらく、現在のツールの中で制作上の実用性に最も近いものです。明確に定義されたサブタスク(線画の着色)を、有意義なアーティスト制御(リファレンス画像とポイントマッチング)で解決しているからです。しかし、MangaNinjaでさえlatent spaceで動作するため、diffusion過程で細部が微妙に変化する可能性があります。そして決定的に、これは単一フレームツールです——連続するアニメーションフレームに適用しても、それらのフレーム間の時間的一貫性が本質的に保証されるわけではありません。制作の文脈では、フレーム間のわずかな色のちらつきさえ許容されません。
3Dアセット生成はアニメーション対応のトポロジーを生成できません。 Hunyuan3D 2.5(Tencentの100億パラメータモデル、2025年4月リリース)、Tripo AIのPrism 3.0、Meshy AIの最新版を調査しました。Hunyuan3D 2.5は注目すべき改善を示しています:幾何学的解像度が512から1024に倍増し、v2.0の出力をリギングやスケルタルアニメーションに不適格にしていたトポロジーの問題に具体的に対処しました。現在はalbedo、normal、roughness、metallicのPBRマップを生成します。
しかし、「アニメーション向けに改善されたトポロジー」は「アニメーション対応のトポロジー」と同義ではありません。AI生成メッシュは依然として高密度——コミュニティテストではHunyuan3Dから数十万トライアングルが報告されていますが、決定的な公式数値は確認できていません——であり、スケルタル変形、ブレンドシェイプ、リアルタイムレンダリングを含む制作パイプラインでは手動のリトポロジーが必要です。Tripo AIはゲームアセット向けによりクリーンなクワッドベースのトポロジーを生成しますが、品質は予測不能に変動します。アニメの3D部門にとって——手描きアニメーションのリファレンスジオメトリとして3Dモデルを使用したり、ハイブリッド制作の直接的なレンダーターゲットとして使用する場合——エッジフロー、ジョイント変形ゾーン、フェイスカウントを制御できないことは、これらのツールが補助的な役割にとどまることを意味します。
なぜ従来の評価指標は重要な点を見落とすのか
制御性ギャップが持続するより深い構造的理由があります:研究コミュニティが生成モデルの評価に使用する指標は、アニメ制作が実際に重視するものを測定していないのです。

動画生成品質の標準ベンチマークであるFrechet Video Distance(FVD)は、2025年のICLR論文(「Beyond FVD」)で3つの重大な限界があることが示されました:依拠するI3D特徴空間がメトリクスの基礎となるガウス仮定に違反していること、時間的歪みに対する感度が低いこと(フレーム順序の違反を十分にペナルティしない)、そして信頼性の高い推定に通常使用されるよりもはるかに多くのサンプルを必要とすることです。アニメに関して具体的に言えば、FVDは滑らかな24fps補間と意図的に2コマ打ちや3コマ打ちで制作されたリミテッドアニメーションを区別できません——しかし、この区別はアート形式にとって根本的なものです。
FID(Frechet Inception Distance)はImageNetで事前学習されたInception v3の特徴量に依拠しています。ImageNetはフォトリアリスティックなデータセットであり、その分布はアニメのフラットな色彩、太い輪郭線、簡略化されたフォームとはほとんど似ていません。優れたアニメを生成するモデルが、出力が写真に見えないという理由だけでFIDスコアが低くなる可能性があります。一方、CLIPスコアはWebクロールされたalt-textキャプションで学習されており、あるCivitAIの評価研究が指摘したように、「Booruタグ付けが通常の画像とどれほど異なるかを考えると、アニメモデルには適していません」。アニメAI実践者が正確なキャラクター指定(髪の色、目の形、数千の特定タグによる衣装の詳細)に使用するDanbooruタグ付けシステムは、CLIPの学習分布に表現されていません。
16次元の包括的な評価スイートであるVBenchでさえ、アニメに対する構造的なバイアスがあります:時間的なちらつきにペナルティを課しながら滑らかさを報酬とするため、完全に静止した画像がダイナミックだが意図的にリミテッドなアニメーションよりも高スコアになります。既存のベンチマークで、フレーム間の線の太さの一貫性、セルシェーディング境界の配置の品質、アニメーションのタイミングが1コマ打ち対2コマ打ちの慣例に適切に従っているかどうか、あるいはスミアフレーム(高速アクションで使用される意図的なモーション歪み)が正しく配置されているかどうかを測定するものはありません。アニメ固有の評価ギャップは、研究者が制作に関連する能力を最適化する体系的なインセンティブを欠くことを意味しており、これらの能力が未発達なままである要因の一つです。
業界の慎重かつ分断された対応
アニメ業界とAIツールの関係は、制御性ギャップを実践的に反映しています。252.5億ドル(3兆8400億円)の市場規模(日本動画協会の2024年データによる——過去最高を更新、前年比14.8%増)と深刻な労働力不足にもかかわらず、実際の導入は限定的かつ慎重なままです。
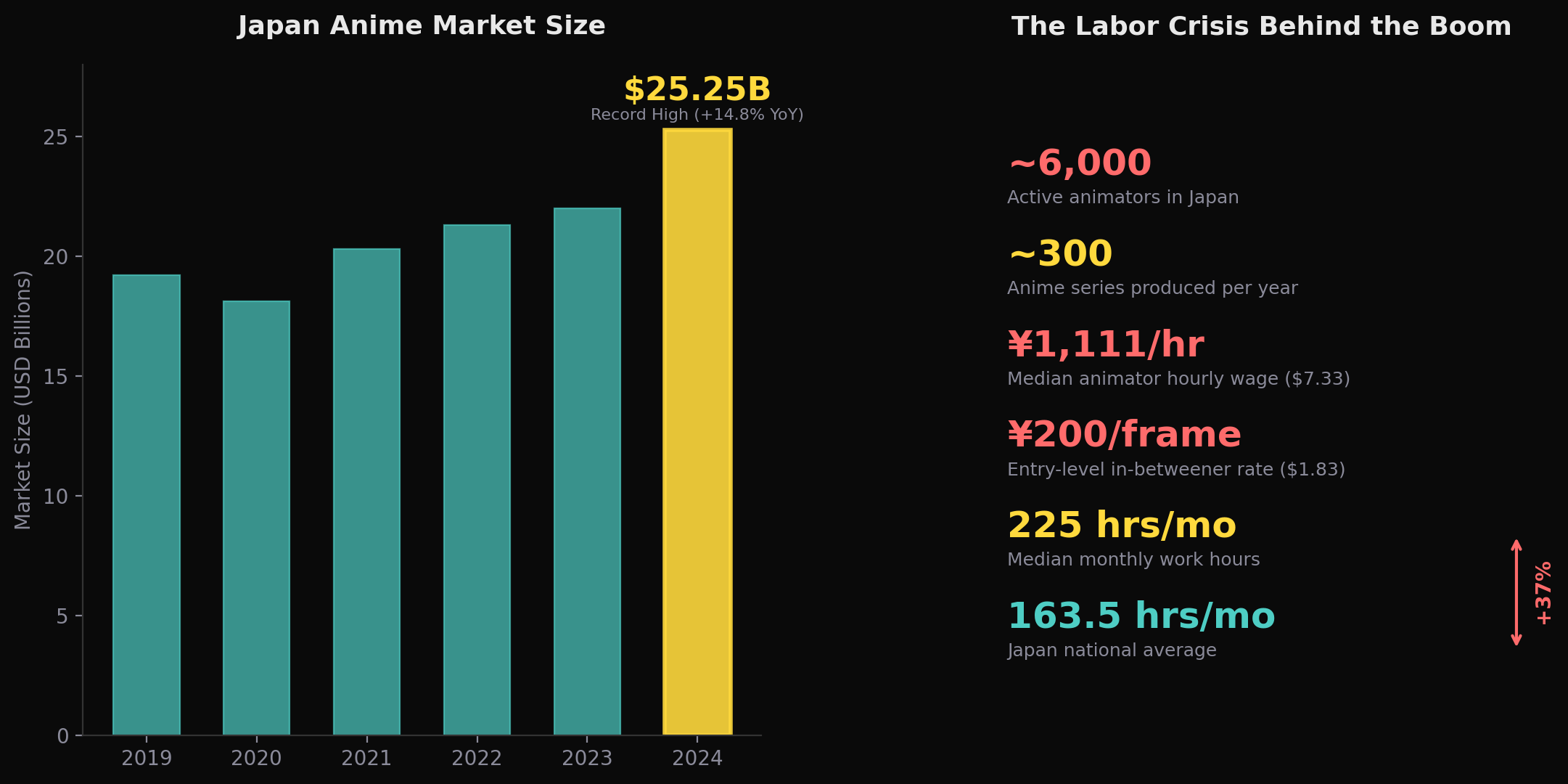
労働力の状況は真に深刻です。日本には約6,000人のアニメーターがいます(朝日新聞の報道による)。一方、年間のアニメシリーズ制作本数はこの20年間で約3倍の年間約300タイトルにまで増加しています(業界集計による)。これらの数字は異なる調査・異なる時期のものであるため、単一の統一的な生産性指標として読むべきではありません——しかし、方向性は明確です:生産量は人員の増加をはるかに上回るペースで拡大しています。アニメーターの時給の中央値は1,111円(7.33ドル)——東京の最低賃金をわずかに下回る水準——で、新人の動画マンは1枚あたり約200円(1.83ドル)を得ています(2024年のNAFCA調査による)。2024年の国連人権理事会報告書は、「200億ドル規模のアニメビジネスのグローバルな収益性と、それを創造するアーティストの待遇との間の著しい対照」を明示的に非難しました。自動化への経済的インセンティブは巨大です。
しかし、AIに投資しているスタジオは、生成的な制作ではなく、厳密に範囲を限定したサブタスクにAIを導入しています。Sonyの子会社であるA-1 PicturesとCloverWorksを通じて開発されたAnimeCanvasソフトウェアは、クリック数を約15%削減するAI支援の仕上げ(インク&ペイント)と、4作品で導入された自動リップシンクエンジンを提供しています。Toei Animationは日本のAI企業Preferred Networksに投資し、背景生成を対象とした将来のツールを開発しています(Scenifyコラボレーションを通じて公に実証済み)。絵コンテ生成や中割り修正も関心領域として報じられていますが、まだ公式には確認されていません。同社は、発表がファンの大規模な反発を招いた後、「現在の制作にはこの技術を使用していない」と明確に説明しました。Sony Pictures ImageworksはSpider-Verseシリーズ向けに、各フレームでアーティストが描く可能性のある線を予測するMLツールを開発しましたが、アーティストは各提案を承認、修正、または却下します。私たちが調べた中で最も目立つスタジオ導入事例に共通するのは、人間が管理するワークフロー内でのアシスタントとしてのAIであり、自律的なジェネレーターとしてではないということです。
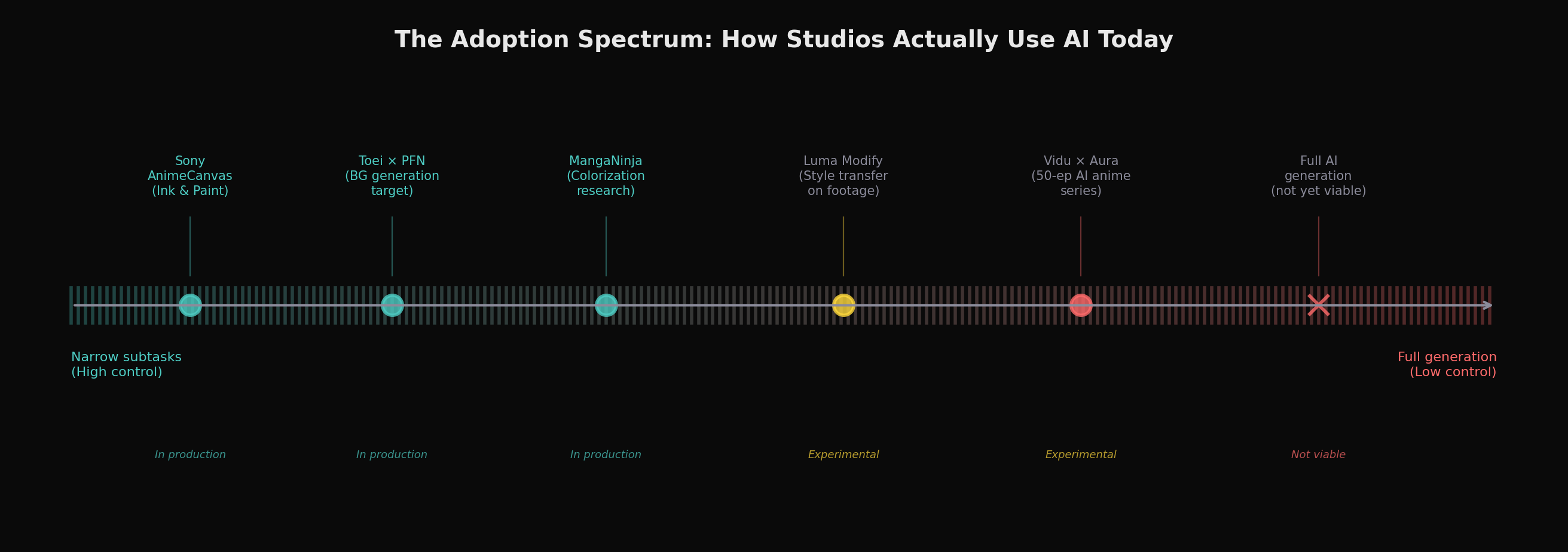
より野心的なAIアニメ制作の試みはすべて、大きな批判に直面しています。Netflix JapanのThe Dog & The Boy(2023年)は、すべての背景画像にAIを使用しましたが、芸術的な不整合や、人間の背景美術家を単に「AI (+Human)」とクレジットしたことで専門家から批判されました。Corridor DigitalのAnime Rock, Paper, Scissors(2023年)は、Stable Diffusionを使用して実写映像にスタイル変換を適用したもので、Anime News Networkが「いいえ、AIでアニメは作れません」というタイトルの詳細な分析を公開するきっかけとなりました——AIはアニメーターが何を作るかは理解しているが、なぜその判断をするのかは理解していないと主張する内容でした。アニメーション業界アナリストのMatt Fergusonが2025年末にまとめたように:「アニメーションのTV・映画におけるAIの役割は、依然としてかなり限定的です。用途は限定的かつ的を絞ったものであり、プロセスを完全に自動化するのではなく、アーティストの作業を補完する傾向があります。」
ギャップを埋める新たな道筋
現在の限界にもかかわらず、いくつかの研究方向が制御性ギャップを縮小する真の可能性を示しています。これらのアプローチには共通の戦略があります:アニメをエンドツーエンドで生成しようとするのではなく、制作が実際に機能する方法に合致した構造化された制御インターフェースを提供するということです。
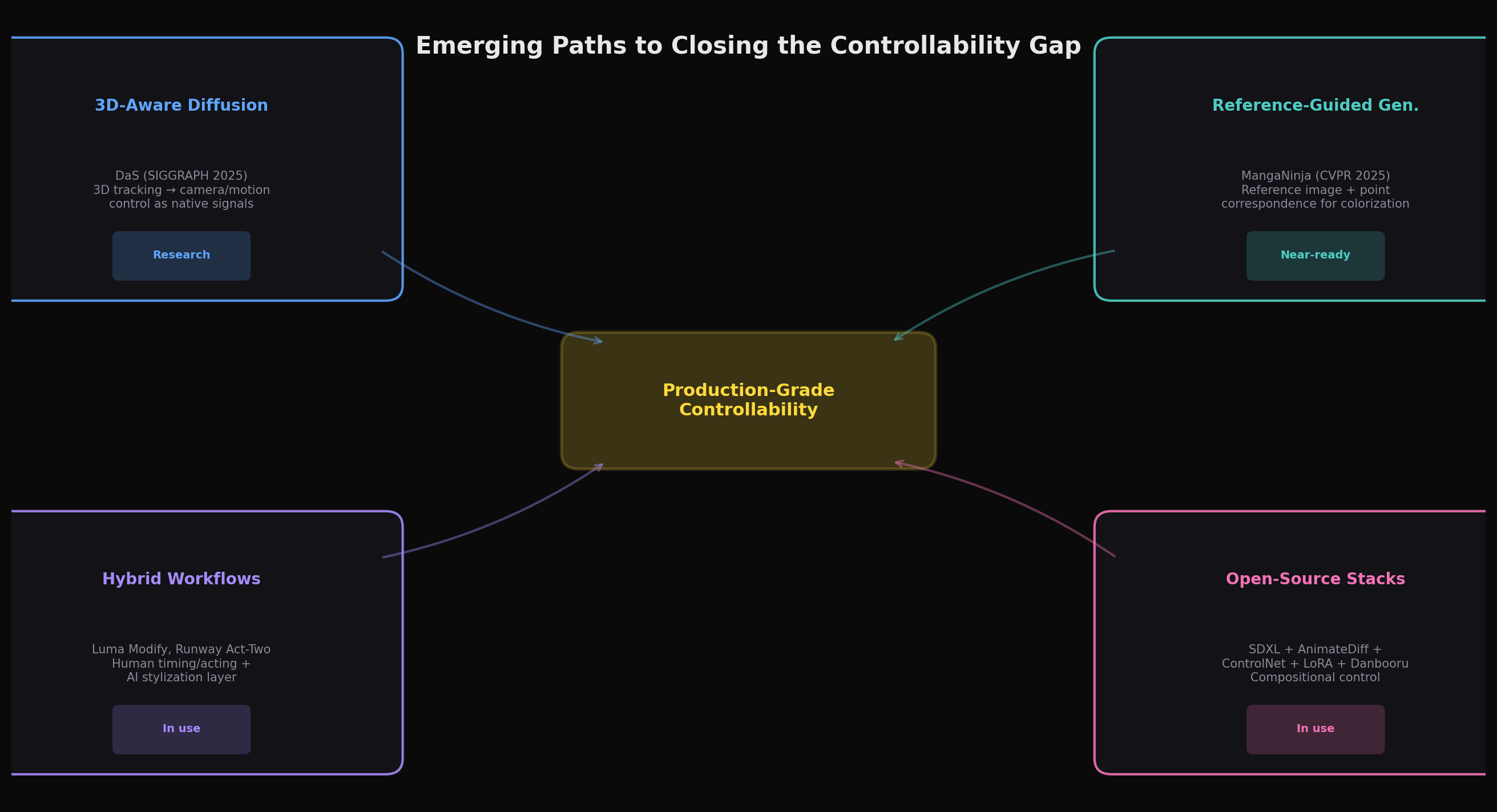
3D対応diffusionは、私たちの評価では、カメラとシーン制御に対してアーキテクチャ的に最も健全なアプローチです。 DaSの洞察——映像は本質的にダイナミックな3Dコンテンツの2Dレンダリングであるため、汎用的な映像制御には3D対応の信号が必要である——は、アニメーターが3Dシーン表現で作業し、diffusionモデルを洗練されたレンダラーとして使用する未来を示唆しています。このシステムはすでに、1万本未満の動画で学習され、単一の統一アーキテクチャを通じてカメラ制御、オブジェクト操作、メッシュからビデオへの生成、モーション転送をサポートしています。このアプローチが、3D制御信号から決定論的(またはほぼ決定論的な)スタイル化出力を生成できるレベルまで成熟すれば、すでに3Dプリビズを広く使用しているアニメ制作ワークフローに自然にマッピングできる可能性があります。
リファレンスガイド生成は制作ロジックに合致しています。 MangaNinjaの明示的なリファレンス画像とポイントベースの対応マッチングを使用するアプローチは、アニメ制作が実際に機能する方法を反映しています——色彩設計はモデルシートや前のフレームを参照します。このパラダイムを時間的なシーケンスに拡張すること(各フレームがモデルシートと前のフレームの両方を参照する形)で、無条件生成が欠いているアイデンティティの一貫性を提供できる可能性があります。IP-Adapterやリファレンスコンディショニングアプローチの広範なファミリー、特にオープンソースのStable Diffusionエコシステム内のものは、テキストではなく画像を通じてスタイルとキャラクターを指定することを可能にします——視覚作業にとってはるかに自然なインターフェースです。
ハイブリッドな人間-AIワークフローは、現在の導入パターンから判断して、最も早い実用的な成果をもたらす可能性があります。 Luma Ray3のModify機能は、実写映像をアニメスタイルの出力に変換しつつ、元のパフォーマンスのモーション、タイミング、感情的な表現を保持できます。RunwayのAct-Twoは、顔の演技を生成されたキャラクターにマッピングします。これらのツールは本質的に、AIを洗練されたロトスコープまたはスタイル変換レイヤーとして、それ以外は従来のパイプラインの中で扱います——そしてこれは、まさに適切な野心のレベルかもしれません。AIにアニメーションをゼロから生成させるのではなく(すべての要素を同時に制御する必要があるタスク)、ハイブリッドワークフローでは人間が得意なこと(タイミング、演技、構図)を人間が担当し、AIが得意なこと(一貫したスタイル化、テクスチャ生成、高速な反復)をAIが担当します。
オープンソースエコシステムは、私たちの評価では、現時点で最も深い制御性を提供しています。 Stable Diffusionエコシステム——特にPony Diffusion V6 XLのようなSDXLベースのアニメモデルに、AnimateDiff(モーション用)、ControlNet(構造ガイダンス用)、IPAdapter(スタイルリファレンス用)を組み合わせたもの——は、本稿執筆時点でクローズドな商用モデルでは再現されていないレベルの構成的な制御を提供します。アーティストは複数のControlNet(ポーズ、深度、線画)をスタックし、30〜100枚の画像で学習したキャラクター固有のLoRAを適用し、これらのコンポーネントを連鎖させる再現可能なComfyUIワークフローを構築できます。Danbooruタグ付けシステムは、アニメ実践者に数千の具体的な視覚属性の精密な語彙を提供します。このエコシステムは技術的に要求が高く、商用モデルよりも短く低解像度の出力を生成します——しかし、プロダクションレベルの制御に近いものへの最も明確な現行の道筋です。
次に何が必要か
生成AIがアニメにおいて印象的なデモから制作ツールへと移行するためには、いくつかの要素が収束する必要があります——そしてそのうちのいくつかは純粋に技術的なものではありません。
第一に、研究コミュニティにはアニメ固有の評価ベンチマークが必要です。制作が実際に重視するものを測定するもの:フレーム間の線の一貫性、セルシェーディングの品質、リファレンスシートに対するキャラクターのon-model忠実度、タイミングの適切性(1コマ打ち対2コマ打ち対3コマ打ち)、フラットカラー領域の空間的一貫性です。これらの指標がなければ、研究者はアニメーションの精度を最適化する体系的なインセンティブを欠くことになります——そしてベンチマークの欠如がモデルをフォトリアリズムに傾斜させる唯一の理由ではありませんが(学習データの分布、商業的需要、RLHFチューニングもすべて寄与しています)、研究コミュニティが努力の方向を転換するための最も効果的なレバーの一つを奪っています。2025年のサーベイ論文「Anime Generation through Diffusion and Language Models」はこのギャップを明示的に特定していますが、包括的なベンチマークはまだ存在しません。
第二に、モデルアーキテクチャは生成型から制御可能生成型へと移行する必要があります——構造化された仕様(キャラクターモデルシート、タイムシート、カメラレイアウト)をアダプターモジュールを介した後付けの条件付けではなく、ファーストクラスの入力として受け入れるシステムです。3Dシーン情報をControlNetスタイルのボルトオンではなくネイティブの制御信号として扱うDaSのアプローチは正しい方向を示しています。アニメ制作が必要としているのは、「クリエイティブジェネレーター」よりも「プログラマブルレンダラー」に近いものです。
第三に、著作権の状況が安定する必要があります。日本は矛盾した立場にあります:著作権法第30条の4は比較法的に見て寛容な条文であり、情報解析のための著作物の使用を認める規定を有しています。しかし同条には「享受を目的としない」要件と、著作権者の利益を「不当に害することとなる場合」には適用されないという条件が付されており、文化庁もこれらの規定に関する解釈指針が法的拘束力を持たないことを強調しています。第30条の4の実務上の適用範囲はますます争われています。そして2025年10月、Studio Ghibli、Toei Animation、Bandai Namco、Kadokawa、Shueisha、その他数十の権利者を代表するCODA(コンテンツ海外流通促進機構)は、OpenAIに対して事前の許諾なくメンバーのコンテンツを学習に使用することを中止するよう正式に要求しました。この未解決の緊張は法的不確実性を生み出し、学習データの出所が不明確なツールの導入をスタジオに躊躇させています。
第四に、業界は労働経済に正直に向き合う必要があります。制御性ギャップと労働力危機は関連しています:薄利で搾取された労働者によって運営されるスタジオには、独自のAIツールを開発するリソースも、ワークフローを再設計する組織的能力もありません。AIを「労働力不足」の解決策として位置付けることは、根本的な問題が報酬にある場合には空虚に響きます——Netflix JapanのThe Dog & The Boyが反発を招いたのは、まさに専門家がアニメーション労働力の不足は存在せず、適切に報酬を受けるアニメーション労働力の不足だけが存在すると指摘したからです。クリエイターへの価値の流れを再構築することなくコストを削減するAIツールは、業界を持続不可能にしている搾取を深化させるリスクがあります。
生成AIに関するより広い教訓
アニメ制作の事例は、アニメーションをはるかに超えて適用される真実を結晶化しています:「印象的な出力を生成できる」と「プロのワークフローに参加できる」の間のギャップは、デモが示唆するよりもはるかに大きく、制御性——生の視覚品質ではなく——こそが最も不足が顕著な軸です。 現在の生成モデルは、視覚的には多くの制作用途に対してすでに十分な品質を持っています。不足しているのは、正確に指示される能力——詳細な仕様を受け入れ、それを忠実に、繰り返し、実際の制作が求める持続的なタイムスケールにわたって実行する能力です。
この教訓は、他の精度依存型の視覚領域——建築、工業デザイン、科学的イラストレーション、医療画像——にも当てはまると私たちは考えていますが、それぞれが独自のワークフロー構造、規制上の制約、許容閾値を持っており、ここでは検証していません。確実に言えるのは、アニメ業界が一貫性に対する極度の要求、十分に文書化された制作パイプライン、そして深刻な経済的圧力によって、制御性ギャップを最大限に可視化しているということです。このギャップを埋めることは、応用AI研究における最も重要でありながら過小評価されている課題の一つであると私たちは考えています——そしてアニメの要求のために開発された解決策は、もっともらしさよりも仕様への忠実度が重要な他の分野にも転用できる可能性が高いでしょう。
よくある質問
Q: AIは今日すでにアニメを制作できるのですか?
「制作する」の意味によります。AIは、単体で見れば視覚的に印象的な5〜20秒のアニメスタイル動画クリップを生成できます。Vidu(コア機能としてアニメ最適化をマーケティング)やKling 3.0(アニメのプロポーションにチューニングされたStylistic Omniエンジン搭載)のようなツールは、本当にアニメフレームに見える結果を生み出します。ViduはAura Productionsと提携して50話のAI生成SFシリーズを制作しており、「ポストプロダクションコストの数倍の削減」を報告しています。しかし、Toei、MAPPA、WIT Studioのようなプロスタジオの基準を満たすアニメーションを、大規模な人間の介入なしに制作できるAIツールは現在存在しません。コアの限界——ショット間のキャラクター一貫性、正確なタイミング制御、長いシーケンスにわたるスタイルの安定性——は未解決のままです。AIが今日できるのは、特定のサブタスクの支援です:着色、背景生成、リップシンク、超解像。SonyのAnimeCanvasとToeiのPreferred Networksへの投資は、このアシスティブパラダイムを代表しています。
Q: Google Flowのようなフルパイプラインのサポートを謳うツールはどうですか?
Google Flowは2025年5月のGoogle I/Oでローンチされた印象的な映像制作プラットフォームで、Veo 3とImagen 4によって駆動されています。テキストからビデオ、シーン拡張、開始フレーム/終了フレームトランジション、ネイティブオーディオ生成をサポートし、2億7500万本以上の動画の作成に使用されています。しかし、Flowは主にフォトリアリスティックでシネマティックなコンテンツ向けに設計されており、特にアニメ向けではありません。アニメ固有のスタイル制御(LoRAファインチューニングやDanbooruタグコンディショニングに相当するもの)がなく、キャラクターモデルシートの一貫性を強制するメカニズムがなく、アニメーションのタイミング慣例に対する制御も提供しません。ユーザーはFlowを通じて手描きイラストをアニメーション化することに成功しており、キーフレームトランジション機能は理論的には原画間の補間をサポートできますが、アニメ制作が必要とする専門的な制御インターフェースを備えていない汎用ツールのままです。
Q: AIはアニメーターに取って代わるのですか?
予見可能な将来においてはそうはならず、この問い自体が適切でない可能性があります。制御性ギャップは、最も高い創造的判断を要する役割——アニメーションの見た目と感触を決定する原画マンやアニメーション監督——が、現在のAIにとって最も再現が困難であることを意味しています。より反復的で仕様に従う作業を伴う役割——動画(中割り)や彩色など——は自動化にさらされやすい可能性がありますが、背景美術、レイアウト補助、ポストプロダクションのクリーンアップといった他の機能もおそらく同様の立場にあります。正確な影響の程度は、各サブタスクにおいて制御性がどれだけ速く向上するかに依存します。明確なのは、最も低賃金のポジション(日本の新人動画マンは1枚あたり約1.83ドル)が、最も自動化しやすい役割と大きく重なっていることです。皮肉なことに、業界の経済を再構築せずにこれらの役割を自動化することは、状況を改善するのではなく悪化させる可能性があります——トレーニンググラウンドとして機能するエントリーレベルのポジションを排除しつつ、より少ないシニアアーティストにより多くの作業を集中させることになるからです。より建設的な枠組みは、AIがアニメ制作を持続可能なものにできるかどうかです——過酷な労働量(月の中央値225時間、日本の全国平均163.5時間に対して)を削減しつつ、クリエイティブコントロールを維持し、AI支援ワークフローを中心とした新しいキャリアパスを創出することによって。
Q: 最も有望な短期的応用は何ですか?
リファレンスガイド着色が、プロダクションへの準備に最も近いと言えるでしょう。MangaNinja(CVPR 2025)は、diffusionモデルがリファレンス画像とアーティストが指定したポイント対応に従いながら高い忠実度で線画を着色できることを実証しています。これは実際の制作ボトルネックに直接対応しています——着色は、かなりのリソースを消費する反復的で仕様駆動の作業です。残された主要な課題は時間的一貫性です:フレームに独立して適用された場合に色がちらつかないようにすることです。リファレンスガイドアプローチがフレームシーケンス全体にわたる一貫性を強制するように拡張できれば(おそらく各フレームをリファレンスシートと前のフレームの出力の両方でコンディショニングすることにより)、このサブタスクは近い将来の自動化の最有力候補の一つですが、具体的なタイムラインを予測する確かな根拠はまだありません。AI支援の背景生成もまた有力な候補です。Toei Animationはこれをターゲットアプリケーションとして明示的に特定しており、このタスクはキャラクターアニメーションを困難にするキャラクター一貫性の要件による制約が少ないためです。
Q: これはより広いAI動画生成の状況とどう関連しますか?
アニメの制御性ギャップは、一般的な問題の特に顕著な事例です。すべてのフロンティア動画生成モデル——Sora 2、Kling 3.0、Runway Gen-4.5、Seedance 2.0——は正確な制御性に苦心しています。カメラの指示は近似的に解釈されます(ドリーインがズームになり、オービットがパンになります)。キャラクターの詳細はショット間でドリフトします。複雑な多要素のコレオグラフィーには広範なイテレーションが必要です。これらの限界は、SNSコンテンツ、マーケティング動画、クリエイティブな探索——各出力が単体で成立し、意図への近似的な準拠で十分な場面——では許容されます。しかし、出力が正確な仕様を満たし、長いシーケンスにわたって一貫性を維持する必要があるあらゆる制作の文脈——アニメだけでなく、映画のVFX、建築ビジュアライゼーション、医療アニメーションでも——では不適格となります。アニメ業界の極端な要件は、有用なベルウェザー(先行指標)となります:AIツールがアニメ制作の要求を満たせるようになれば、他の精度依存型の視覚制作にも対応できる可能性を示す強力なシグナルとなるでしょう——ただし、各領域には独自の制約があり、個別の検証が必要です。
主要参考文献: Diffusion as Shader (SIGGRAPH 2025) · MangaNinja (CVPR 2025) · I2VControl-Camera (ICLR 2025) · Beyond FVD (ICLR 2025) · Hunyuan3D 2.5 (Tencent, 2025) · APISR (CVPR 2024) · AJA Market Report 2024 · NAFCA Animator Survey 2024