
産業用の合成データに求められる目的が、生成AIの主流が追求している目的とは正反対であること、そして自動車OEMとの統制下の検証から何が明らかになったかを論じる研究ノートである。
専門的なCVモデル(物体検出、セマンティックセグメンテーション、OCR、深度推定、追跡)の性能は、訓練に用いたデータの質を超えることはない。これらのモデルにとって最も困難なのは、ありふれた場面ではなくコーナーケースである。すなわち、希少な物体クラス、通常では起こりにくい空間配置、意図的に演出したり収集したりすることが不可能な状況である。デモで印象的に動作する検出器と、本番環境で耐え抜く検出器とを分けるのは、この領域における差である。
データ問題に対する主流の対応は、収集規模を拡大することである。つまり、より多くのラベル付き画像、より多くのアノテータ、より多くのストレージである。しかし、安全性が問われる場面でのロングテール視覚タスクにおいて、この方針はすぐに限界に達する。世界はロングテールであり、コーナーケースは要求に応じて収集できるものではない。従来型のデータ拡張(反転、切り取り、色相のジッタなど)は、ノイズ的な変動に対する不変性を導入するに留まり、新しい視覚的内容を持ち込まない。最も価値ある事例こそが、訓練セットへの追加が最も難しい事例である。
本稿では、ロングテール視覚タスクのための合成データが満たすべき設計目的を整理し、その目的が、なぜ主流の生成AIが最適化している目的と意図的に逆向きなのか、そして同じ目的のもとで自動車OEMとの統制下の検証から何が明らかになったのかを述べる。
ずれ:視覚的魅力と訓練上の有用性
生成AI業界は、美しい画像を生み出すことを競っている。視覚的品質、美的整合性、人間評価者から見たプロンプト忠実性などが、最先端のtext-to-image研究を駆動する目的であり、汎用生成器の多くが最適化対象としているものである。
しかし、視覚的魅力に最適化されたモデルは、そのままでは有用な訓練データの供給源にはならない。人間評価者が減点しない以下の2つの性質は、合成データを訓練素材として有害にしてしまう性質そのものである。
位置のドリフト。 生成器は「日本の高速道路でフレーム外に一部はみ出すトラック」の美しい画像を生成しうるが、プロンプトが指定した位置とはわずかに異なる位置にトラックを配置することがある。人間採点者から見れば問題ない。しかし、その画像で訓練される下流の検出器にとっては、プロンプトから導出されたバウンディングボックスのアノテーションが描画された物体位置と整合しなくなり、モデルはアノテーションとピクセルとの間に微妙に誤った対応関係を学習してしまう。
ドメインシフト。 Webスケールの美的画像で訓練された生成器は、「魚眼カメラから見た日本の高速道路」らしく見える画像を生成するが、対象カメラ系の歪みプロファイル、露出特性、ノイズフロアと実際に一致しているわけではない。生成された画像は人間評価者には正しく見える一方で、CNNの特徴抽出器には別ドメインに見える。そして、その混合データで訓練されたモデルは、最良の場合は合成データを無視し、最悪の場合は実データを犠牲にして合成分布を学習することになる。
これらの性質は、コンテンツ生成の場面では許容されるが、訓練データとしては失格である。
別の目的:機能的正しさ
以上の分析から導かれる設計目的は、述べること自体は単純である。すなわち、人間採点者にとってより見栄えのする画像ではなく、認識モデルの性能を向上させる訓練データを生成することである。この目的は、測定可能な2つの性質に分解される。
位置忠実性
生成された物体は、アノテーションが指定する位置に正確に現れる。入力レイアウトが構築上そのまま出力アノテーションとなり、別途のラベリング工程は存在せず、プロンプトの空間的意図と描画されたピクセルとの間にずれは生じない。検出モデルにとって、合成データが少しでも使い物になるかどうかを決めるのはこの性質である。セグメンテーションモデルでは、物体境界に沿ってピクセル粒度でこの性質が成立している必要がある。
汎用生成器はこの性質に対して中立でないどころか、逆向きに最適化されている。指定されたレイアウトを厳密に保持する生成器は、人間評価者から「制約されて見える」として減点されてしまうためである。コンテンツ生成にとっては正しい損失関数だが、訓練データにとっては誤った損失関数である。
スタイル整合性
生成画像は対象とする展開環境(特定のカメラ系、照明、大気条件、センサノイズプロファイル)の視覚特性と一致しており、しかも極めて少数の参照画像から、アノテーションなしでそれを実現する。
これは、合成と実データの間のドメインギャップを埋める性質である。展開ドメインに一致しない合成画像と実画像の混合で訓練されたモデルは、実画像のみで訓練されたモデルよりも実際の性能が悪化する場合がある。スタイル整合性こそが、合成データが訓練信号を希釈するのではなく寄与する側に立たせる性質である。
ロングテールにおける欠落の分類と、それに対応する生成手法
ロングテールにおける失敗モードは様々であり、それぞれ異なる種類の合成データを必要とする。以下の4分類はツールの機能項目ではなく、実データセットで繰り返し直面した欠落と、それに対応するための合成事例の種類を整理したものである。実際の訓練においては、これらは単一バッチの中で組み合わせて用いられうる。
1. ロングテールの再バランス
既存シーン内で、過剰に表現されている物体クラスを希少クラスに置換する。シーン構成は保持され、対象物体のみが変化する。結果として、新規データ収集を伴わずにクラス分布が直接的に再バランスされる。


2. インスタンス密度の増加
既存シーン内のもっともらしい位置に新たな物体インスタンスを追加する。生成された各画像は元の画像よりも多くのラベル付き物体を含み、フレームあたりの訓練信号がより密になる。


3. 特定コーナーケースの狙い撃ち
検出器に学習させたい状況(極端に近接したトラック、通常では起こりにくい空間配置、希少な構成など)を明示的に指定し、必要なだけ多様な事例を生成する。


4. 未知物体の生成
訓練データに一度も現れなかった物体(路上落下物、通常では遭遇しない障害物、動物など)を、指定位置に正しいアノテーション付きで新規カテゴリとして生成する。これにより、実世界での訓練サンプルがゼロのクラスにまで検出器の語彙を拡張する。


大手自動車OEMとの統制下の検証
上記の整理は、検証可能な問いを提起する。すなわち、この種の合成データで検出モデルを訓練することは、運用者が関心を寄せるコーナーケースに対して実際に性能向上をもたらすのか、という問いである。これに答えるため、大手自動車OEMのR&D部門との統制下の検証が実施された。
当該OEMの自動運転チームは、広角および魚眼レンズを含むマルチカメラのセンサスイートを運用している。同社からは本番データセットから24,000枚のアノテーション付き画像が訓練セットとして提供され、別途用意されたホールドアウトのテストセットも併せて提供された。データセットの分布は業界で典型的なものであった。
- 乗用車:数千インスタンス。
- スクールバス、消防車、工事用車両:それぞれ数えるほど。
- 自車に近接しフレームをほぼ覆う車両、すなわち自動運転車にとって最も危険なシナリオは、著しく過小に表現されていた。
- フレーム外にはみ出すほど近接して部分的にしか写らないトラック:24,000枚中233インスタンス。
生成モデルはOEMのカメラ構成に適応され、上記の4つのモードにわたって約36,000枚の合成画像が生成された。合成データを実訓練セットに追加し、各混合データに対して検出モデルを最初から訓練し直し、ホールドアウトのテストセットで性能を測定した。
検証の設計
以下に報告する数値は、ある1社のOEMとの単一の取り組みから得られたものである。読者が結果の射程を判断できるよう、設定を明示する。
- 検出器。 YOLO系の標準的なシングルステージ検出アーキテクチャを用い、各データ混合について最初から訓練した(ImageNetやCOCOによる事前学習なし)。ハイパーパラメータ構成は、OEMが当該センサスイート向けに社内で用いているものと同一とした。
- 訓練データ。 OEMから提供された24,000枚のアノテーション付き本番フレーム。本稿の各実施において実訓練データのラベルは一切変更していない。混合に追加された合成フレームは、構築上得られるアノテーション(位置忠実性に基づく)を持ち、それぞれの生成モードがタグ付けされている。
- テストデータ。 OEMから提供された、独立のホールドアウト用テストセット。テストセットは生成器に一度も見せておらず、合成生成物の選別にも使用していない。本検証中、テストセットの画像は確認していない。
- 指標。 ホールドアウトのテストセット上のmAP@0.50:0.95。
- ベースライン。 実データのみの3条件:実24,000、実30,000、実60,000フレーム(OEMが供給可能な最大量)。「同等量の合成データ」に関する所見の比較対象は実30Kベースラインである。
- 繰り返し。 本稿で報告する実行は、各データ混合につき単一の乱数シードで訓練された。複数シードによる分散の推定は行っておらず、したがって個々のmAP点に信頼区間は付与しない。本研究で支柱となる所見は方向性(合成量の増加に伴うmAPの単調増加)であり、絶対値は単一の取り組みからの点推定として解釈すべきである。
- 外的妥当性。 1社のOEM、1つのカメラ構成(広角および魚眼レンズ)、1つの検出器系である。転移可能と考えるのは設計目的(位置忠実性+スタイル整合性)であり、具体的な数値そのものではない。
以下のいずれも本検証では確立されていない。すなわち、合成データが任意の比率で実データの普遍的代替となること、検証範囲を超えて曲線が単調増加し続けること、あらゆる難易度において合成サンプル1件あたりの価値が実サンプル1件あたりの価値と等価であること、である。確立されたのは、当該OEMにおいて、本研究で生成した合成データが検証された量の範囲でプラスの寄与をもたらしたこと、そして実データで体系的に過小表現されていた特定のコーナーケースに対し、狙い撃ちで生成された合成事例が改善をもたらしたことである。
合成データ量とともにmAPが向上する
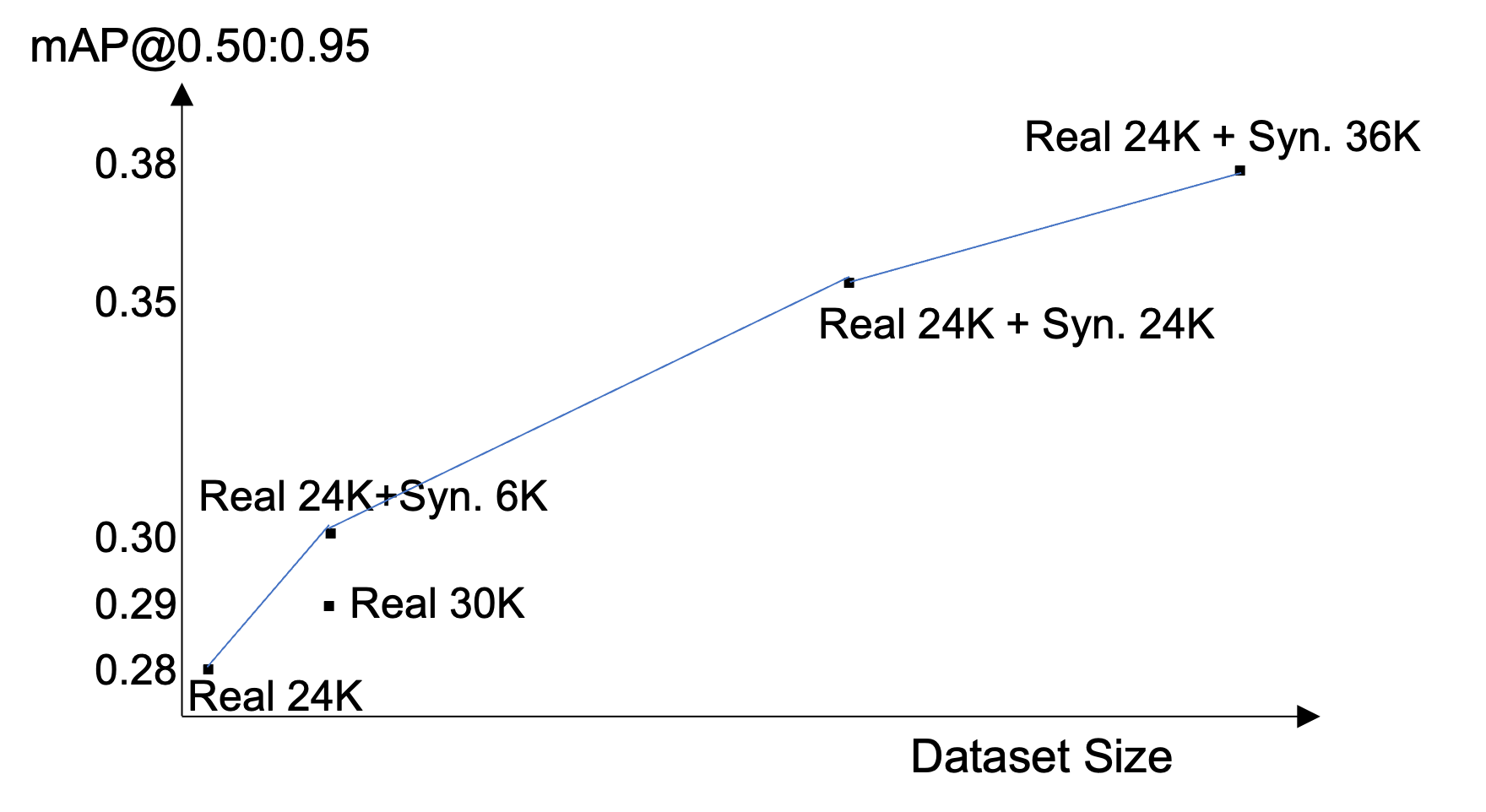
mAPは0.279から0.378へ。 約36,000枚の合成画像を追加することで、mAPは絶対値で+0.099(相対で+35.5%)向上した。検証した最大量においても曲線は飽和していなかったが、合成と実の比がさらに大きくなるにつれて限界効用は低減すると見られる。
当該データ比率では合成データが実データを上回った
統制された比較において、実24,000+合成6,000枚は実30,000枚よりも高いmAPを達成した。これは、合成データが普遍的に実データより優れているという主張ではない。当該の量、当該のドメインにおいて、追加戦略で生成された合成画像はフレームあたりのアノテーション付きインスタンス数が多く、画像あたりのより密な教師信号が、限界での実画像の追加効用を上回ったという主張である。
これは位置忠実性とスタイル整合性の双方が成立して初めて得られる類の所見である。位置忠実性がなければ合成アノテーションが誤りとなり、スタイル整合性がなければ合成画像が独自のドメインを形成し、検出器はそれらを無視するように学習してしまうためである。
233枚の合成事例が最重要コーナーケースを改善した
最も鮮明な結果は、単一の最難関コーナーケース、すなわちフレーム外にはみ出すほど近接して部分的にしか写らないトラックに対して得られた。訓練セットには当該事例が233件、テストセットには503件存在した。当該コーナーケースに整合する233件の狙い撃ち合成事例を生成し、訓練セットに追加した。この状況に対する検出性能は向上した。


ここで意味があるのは件数の同等性である。実233件、合成233件、合成側がそれまで閉集合検出器が取りこぼしていたシナリオに対する実効的な教師信号を倍化した。件数を増やしていった場合に合成と実の同等性が維持され続けるかは、未解決の問いである。
未解決の問題
上記の設計は完成された体系ではない。本研究の経験上、最も重要な未解決の問いは以下である。
- 限界効用の逓減。 OEM検証におけるmAP曲線は、検証した合成対実の比率60%でも飽和に達していなかった。ただし、それを超える比率では追加合成データの限界寄与が明確に逓減する。所与のドメインにおいて漸近線がどこにあるかについては、十分なモデルが得られていない。
- 合成と実の同等性は単一のデータ点に過ぎない。 233+233が特定のコーナーケースを解消したことは励みになる結果である。しかし、より難しく構成的なコーナーケースにおいて、合成1,000件が実1,000件の代替となりうるかは次の問いであり、決定的な回答はまだ得られていない。
- データセット間のドメイン転移。 ある魚眼系に向けて調整されたスタイル整合性適応は、異なる広角ピンホール系へそのまま転移できるわけではない。ここで望ましいのは、データセットごとのエンジニアリング作業ではなく、ラベルなしの少数の参照フレームから新しいセンサ構成へ学習時に適応する手順である。
合成データの問いをどう位置付けるか
本検証から汲み取る価値があるより広い主張は、数値的というより構造的なものである。ロングテール視覚タスクにとって、合成データの正しい目的は視覚的魅力ではなく位置忠実性とスタイル整合性であり、この目的は主流の生成AIの評価が報酬を与えているものと正面から対立している。OEMでの結果は、運用者が他の手段では収集できないデータにおいて、この目的が最適化対象として正しいことを示す1つのデータ点である。同様の結果が、より高い合成対実の比率、より構成的なコーナーケース、異なるセンサ構成にまたがって成立するかどうかは、見出しのmAP数値よりも興味深い未解決の問いの集合であると考える。