
信頼性はモデル規模の拡大ではなくエンジニアリング上の規律によってもたらされること、そして本番環境で機能するエージェントを構築するうえで数学・ベンチマーク・市場データが何を語っているかを整理する。
複数のステップを連結するAIエージェントには、よく知られた数学的問題がある。ステップごとの成功率が固定で、有効な回復手段を持たない単純な逐次パイプラインでは、ステップを1つ追加するごとに信頼性は指数的に減衰していく。個々のステップが95%の確率で成功するシステムでも、20ステップを通したエンドツーエンドの成功率はわずか36%にとどまる。この減衰曲線は、回復機構を持たない逐次システムの構造的性質であり、パッチを当てて直せる類のバグではない。だからこそ、結果を実質的に変える対応(分解、投票、状態の外部化)は、意図的に設計し組み込んだときにのみ有効なアーキテクチャ上の選択となる。
コーディングやWebタスク向けエージェントのベンチマーク値は急速に伸びている一方、本番環境では事情は大きく異なる。エンタープライズにおけるAI導入の多くは依然としてエージェントではなくコパイロットにとどまり [1][2]、エージェント型AIプロジェクトの相当数が本番環境に到達していない [3]。本稿で扱うのは、このギャップの背後にある数理であり、特にエージェント型ビジョン(信頼性の欠如が「修正可能な段落」ではなく「運用上の帰結」として支払われる領域)への含意に焦点を当てる。
複合的な失敗の数理は容赦がない
パイプラインがそれぞれ独立した成功確率 p をもつ n 個の逐次ステップから構成されるとき、エンドツーエンドの成功確率は pⁿ で与えられる。この指数的減衰が描き出す光景は容赦ない。
| ステップごとの精度 | ステップ数 | エンドツーエンド成功率 |
|---|---|---|
| 99% | 10 | 90.4% |
| 95% | 10 | 59.9% |
| 95% | 20 | 35.8% |
| 90% | 10 | 34.9% |
| 99% | 100 | 36.6% |
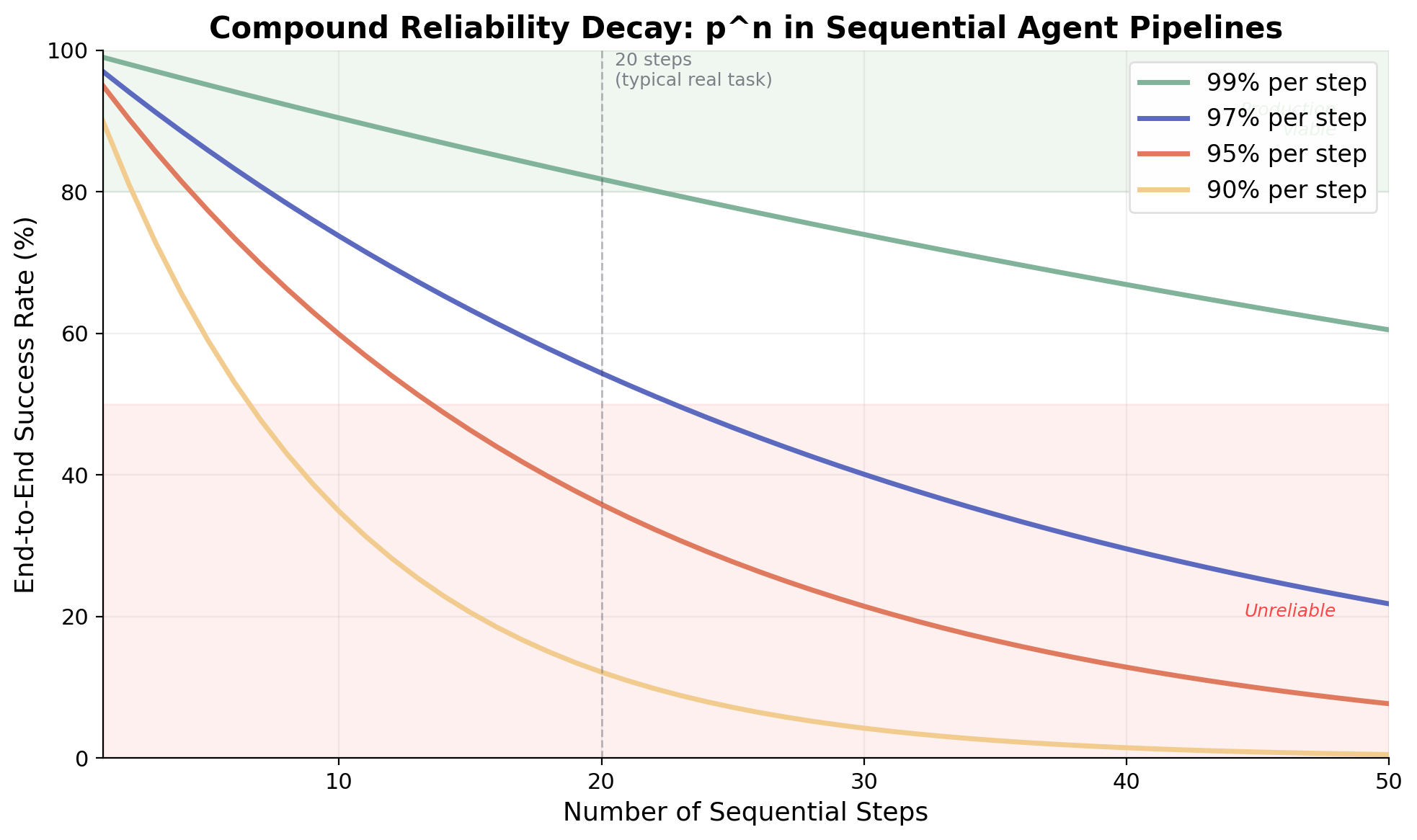 図1. さまざまなステップごとの信頼性水準について、逐次ステップ数を関数としたエンドツーエンドの成功率。ステップごとに99%の精度があったとしても、50ステップで成功率は60%に落ち込む。
図1. さまざまなステップごとの信頼性水準について、逐次ステップ数を関数としたエンドツーエンドの成功率。ステップごとに99%の精度があったとしても、50ステップで成功率は60%に落ち込む。
この単純なモデルは、実際の問題を過小評価している。エージェントのパイプラインにおけるステップは独立であることが稀であり、誤りは意味的に伝播して下流の文脈を汚染する。それは検出も回復も難しい。Pedderの言う**「失敗の粘着性(failure stickiness)」はこの現象を定式化したもので、誤りがパイプラインを不可視のまま伝播していく場合(Pedderはこれを「absorbing failures」と呼ぶ)、ステップごとの信頼性が95%で粘着性が高いシステムは、独立性仮定が予測する値よりも劇的に悪い性能を示す [4]。Pedderの分析によれば、誤りから回復する能力は、各ステップを2.7倍信頼性の高いものにする**ことと等価であり、これは信頼性の問題をステップごとの精度ではなく回復のアーキテクチャの問題として捉え直すものである。
2025年のUCバークレーの論文 Why Do Multi-Agent LLM Systems Fail?(Cemri et al., NeurIPS 2025)[5] は、代表的な7つのマルチエージェントフレームワークにわたる1,600件超の実行トレースを注釈づけし、14の失敗モードを同定した。OpenHandsやMetaGPTなどのフレームワークでは、クロスアプリケーションのテストにおいて失敗率は**86.7%**に達した。役割記述の改善といった介入は不十分であり、著者らは「これらの失敗にはより複雑な解決策が必要である」と結論づけている。
より近年の枠組みとしては、プリンストンのRabanser, Kapoor, Narayananによる "Towards a Science of AI Agent Reliability"(2026)[6] が、エージェントの信頼性を一貫性・頑健性・予測可能性・安全性の4軸、計12個のメトリクスに分解している。彼らの中心的な発見は、18か月にわたる14のフロンティアモデルで能力は急速に向上したにもかかわらず、信頼性はほとんど変化していないというものだ。Pass@1メトリクスは真の信頼性を20〜40%過大評価しているとも報告されている。ここから引き出される解釈は、精度と信頼性は別個の性質であるということだ。モデルは問題を解く能力を劇的に高めながらも、ある実行でどの問題を解けるかについては相変わらず予測不能でありうる。
エージェント型ビジョンにおける見え方の違い
複合的な信頼性低下の問題は、あらゆる逐次的エージェントに当てはまる。ただし、ビジョン特有のいくつかの性質によって曲線の形は変化する。これは、そもそもどの緩和策が現実的な選択肢となるかを左右するため、明示的に述べておく価値がある。
視覚知覚の呼び出しは、価格帯が異なる。専門のCVモデルを1回呼び出すコストはテキストツールの1回の呼び出しよりも大きく、信頼性低下に対する素朴な対応(検出器を増やして投票させる)は、純粋なテキストでの同等手法に比べてコスト曲線がより急峻になる。
回復の様相も異なる。テキストの推論ステップが誤ったとき、同じプロンプトを同じ文脈に対して再実行しても、同じ失敗が再現されるか、再試行が比較的安価に済む程度のことが多い。ところがCVモデルが遮蔽されたフレームで誤分類した場合、是正手段は同じフレームに対してモデルを再実行することではない。別のフレーム、別のアングル、あるいは次回の走査を見ることである。ここでの回復は、エージェントのステップ間のみならず、エージェントとセンシング層のあいだの結合として現れる。
そして、出力の受け手はしばしば物理世界にある。ビジョンのパイプラインは、保守スケジュール、設備の移動、オペレータへの通知といった意思決定を駆動する。裏付けのない主張のコストは、ユーザが書き直せる一文では済まない。
これらの性質は、複合的な信頼性低下を絶対的な意味で悪化させているわけではない。実用上どのアーキテクチャ上の対応が成立するかを変えているのであり、その対応を論じる前に明示しておくべき部分である。
エージェントの成功率はタスクの複雑さに対し指数的に減衰する
METRによる Measuring AI Ability to Complete Long Tasks(Kwa et al., 2025)[7] は、決定的な実証像を与えてくれる。研究者らは「50%タイムホライズン」、すなわちエージェントが半分の確率で成功するタスク長(人間換算時間)を測定した。Claude 3.7 Sonnetでは、この値はおおよそ50分であった。
Toby Ordのその後の分析 [8] は、ハザードレート一定の仮定(失敗確率がタスクの所要時間に対し一様であると単純化したモデル)のもとで、その含意を探っている。この枠組みでは、エージェントが50分のタスクで50%の成功率を達成するとき、90%の成功率を達成できるのは約7分のタスク、99%の成功率を達成できるのはおよそ43秒のタスクに限られる。99.9%の信頼性が要求される業務用途では、実用可能なタスク長は数秒のオーダーに崩壊する。これらは運用測定ではなく簡易な外挿だが、桁の感覚として重要なのはこの部分である。Ordはまた、同等のタスクにおける人間の生存曲線がこの一定ハザードモデルの予測よりも目に見えて良好であるとも指摘している。これは、現状のエージェントよりも人間のほうが回復に優れているという観察と整合する。
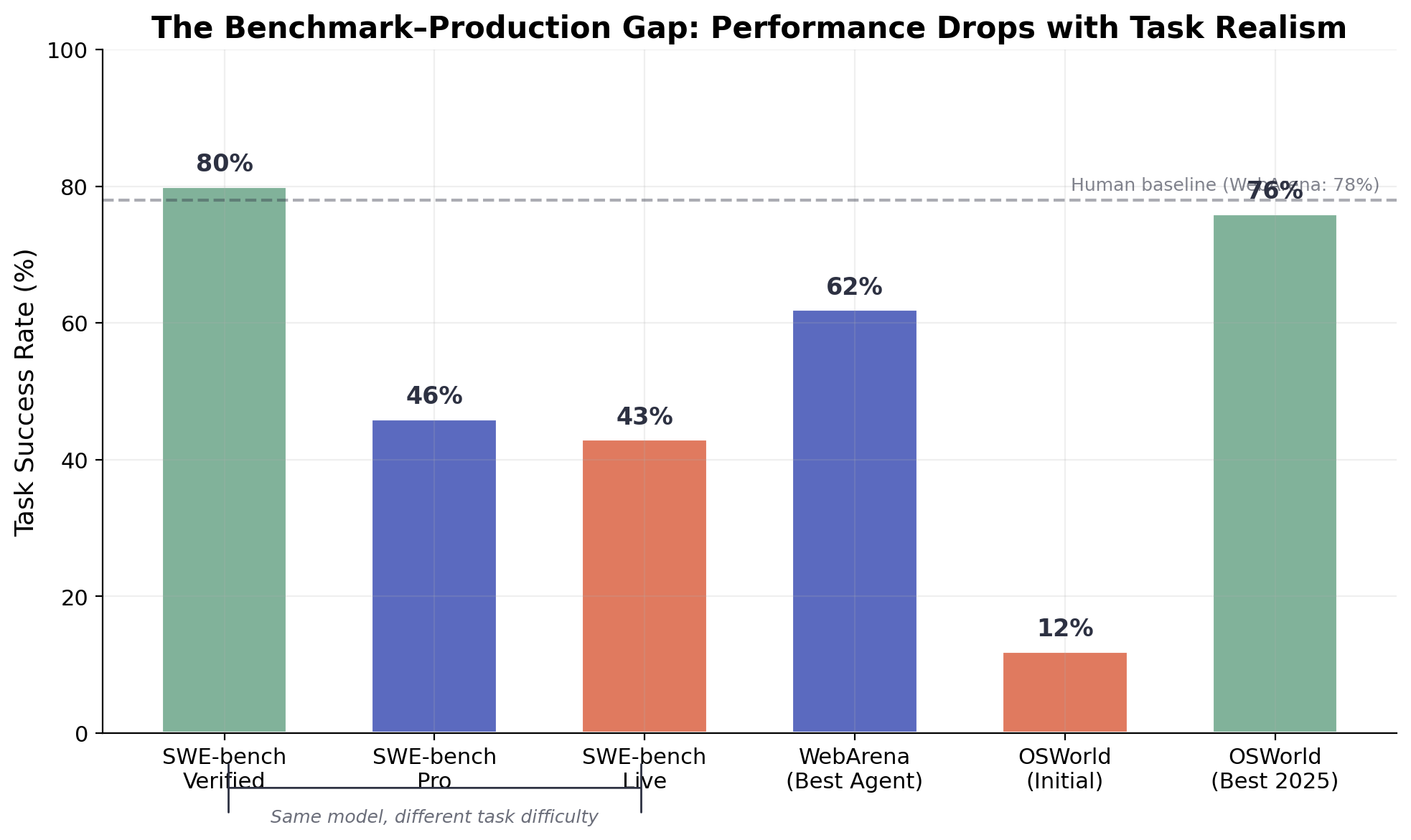 図2. ベンチマークと本番環境のギャップ。同じモデル構成でも、SWE-benchのバリアント(Verified → Pro → Live)、WebArena、OSWorldのあいだで成功率は劇的に異なる。統制されたベンチマークは実世界の能力を大幅に過大評価する。
図2. ベンチマークと本番環境のギャップ。同じモデル構成でも、SWE-benchのバリアント(Verified → Pro → Live)、WebArena、OSWorldのあいだで成功率は劇的に異なる。統制されたベンチマークは実世界の能力を大幅に過大評価する。
ベンチマークデータは、領域を超えてこの傾向を裏づける。SWE-bench Verifiedでは上位エージェントが80%超のスコアを示す。SWE-bench Proでは同じシステムが約46%まで落ち [10]、SWE-bench Liveでは**19〜43%**にとどまる [9]。WebArenaでは最良のシングルエージェントシステムが61.7%に到達し、人間ベースラインは78%である [11]。OSWorldのデスクトップタスクでは、当初12.24%だった最良モデルの成功率が一部の構成で76%まで上昇しているが、Epoch AIによれば、これらタスクの約45%は真のGUI推論を要さず単純なターミナルコマンドで完遂できるとされている [12]。
ベンチマーク性能と本番環境の信頼性は別物を測っている。 前者は統制された条件下でのピーク能力を捉えるのに対し、後者は実世界のロングテールにわたる安定した性能を要求する。
トークンの経済学が複合的なコスト危機を生む
信頼性の問題には、経済面でも対をなすもう一つの問題が現れる。各ステップが膨らんでいく会話履歴全体を再処理する素朴な反復型エージェントループでは、トークンコストは線形ではなく二次的に累積する。SWE-benchのリーダーボードの分析によれば、高性能なエージェントはシングルショット手法に比べてタスクあたり10〜50倍のトークンを消費する [13]。
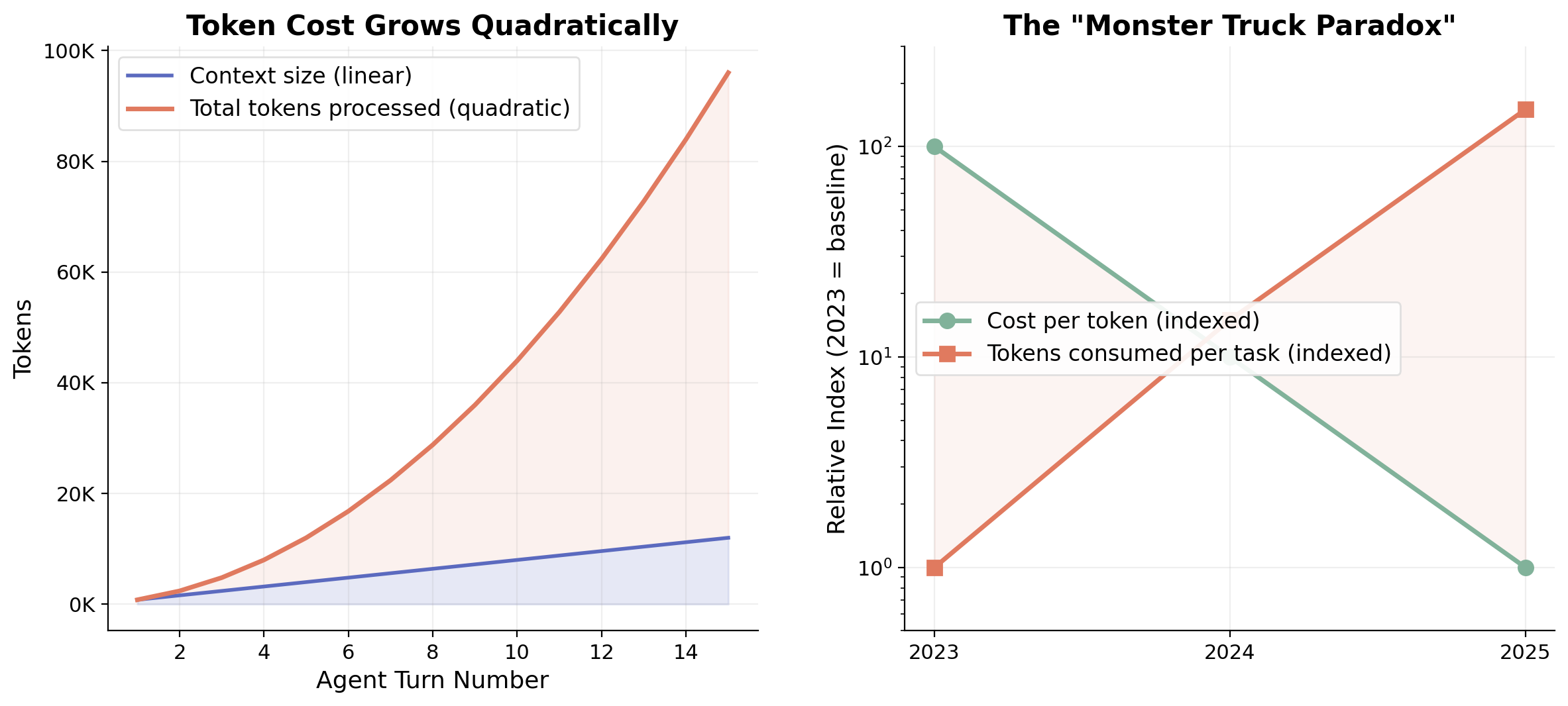 図3. 左: 各エージェントターンで先行する文脈をすべて再処理するため、トークンコストは二次的に増加する。右: 「モンスタートラック・パラドックス」。トークンあたりのコストは年あたり約10倍下落するが、タスクあたりの消費量はそれを上回る速さで増加しており、その駆動要因はエージェント型ワークロードである。
図3. 左: 各エージェントターンで先行する文脈をすべて再処理するため、トークンコストは二次的に増加する。右: 「モンスタートラック・パラドックス」。トークンあたりのコストは年あたり約10倍下落するが、タスクあたりの消費量はそれを上回る速さで増加しており、その駆動要因はエージェント型ワークロードである。
その規模は注目に値する。チャットからエージェントへの進化により、セッションあたりのトークン消費は桁単位で増大し、個人のヘビーユーザでさえ月あたり数十億トークンを消費していると報告されている [14]。トークンあたりのコストは2023年以来年あたり約10倍下落しているが、タスクあたりの消費量はそれより速く伸びている。
本番環境では、経済的な制約は緩むのではなく締まる方向に作用する。トークン単価は下がる一方でタスクあたりの消費が速く伸び、ステージングと本番のギャップは縮まるどころか広がる傾向にある [3][15]。文脈の圧縮(プロンプトキャッシュ、階層的要約、選択的注意)は文献中で最もROIの高い最適化として報告されており、5〜20倍の削減、70〜94%の節約が報告されている。ただし、これらの緩和策は症状への対処にとどまる。
可能であれば、最もレバレッジが効く対策はステートレス設計である。すなわち、個々のモデル呼び出しを、明確な指示を受け取り、結果を返して終了する、専門化された単一用途の操作として扱う。状態を保持しなければならないときには、それを会話の中で持ち回るのではなく、データベースまたは文脈ストアへ外部化する。この組み合わせがあって初めて、システムは経済的にスケールし、かつ下流の検証層によって監査可能であり続ける。
実際に信頼性を改善するアーキテクチャパターン
近年の結果のうち最も心強いのは、Cognizant AI Labからのものだ。Meyerson et al.("Solving a Million-Step LLM Task with Zero Errors", 2025)[16] は、MAKERフレームワークが100万を超える逐次LLMステップをエラーゼロで完了したことを示した。MAKERはこれを3つの原理によって達成している。ステートレスな「マイクロエージェント」が扱う原子的サブタスクへの極端な分解、ギャンブラーの破産問題の一般化に基づくマルチエージェント投票、そして構文エラーを論理エラーのシグナルとみなして修復ではなく破棄する「red-flagging」である。さらに驚くべきことに、コストあたりの信頼性で最も優れていたのはより小型で推論モデルではないモデルであった。
ただし重要な留保がある。MAKERの100万ステップという結果は、決定論的な検証が可能な高度に構造化されたタスク(ハノイの塔)で達成されたものだ。アーキテクチャ上の原理(分解、投票、ステートレスなマイクロエージェント)は広範に適用可能だが、ゼロエラーという具体的な結果を曖昧なエンタープライズワークフローへ外挿すべきではない。
これは主要な研究機関のあいだで形成されつつある合意とも整合する。Anthropicの Building Effective Agents(Schluntz and Zhang, 2024)[17] は明確な序列を打ち出している。すなわち、シンプルに始め、必要性が示されたときにのみ複雑さを足し、エージェント型システムはレイテンシとコストをタスク性能と引き換えにすることを認識せよ、というものだ。Anthropicはその後、SWE-benchで最先端の結果を達成したが、その一部はモデル変更ではなくツール記述の入念な改良によるものであり、インフラ設計がモデル能力以上に効きうることを具体的に示した。
OpenAIの Practical Guide to Building Agents(2025)も独立に同様の結論に到達しており、マルチエージェントの複雑性を導入する前にまず単一エージェントの能力を最大化せよと助言している [18]。競合関係にある研究機関のガイダンスが同じ原理(シンプルさ、狭いスコープ、ツール設計への入念な配慮)に収束していること自体、有力な証拠と言える。
DSPy(Khattab et al., NeurIPS 2023)[19] が切り拓いたプログラマティックなアプローチも、別の答えを提示する。プロンプトを人手で作り込むのではなく、LLMパイプラインを最適化可能なプログラムとして扱う。特定のタスク構成ではGPT-3.5のパイプライン品質を**33%から82%**まで向上させたとされるが、この数値はあくまで特定のベンチマーク断面で得られたものだ。それでもより一般的な要点は揺らがない。DSPyは、基盤モデルへの変更ではなく、パイプライン構造の体系的な最適化によって実質的な改善を達成している。
基盤となるアーキテクチャ群(接地のためのReAct [20]、失敗からの学習のためのReflexion [21]、階層的な合成のためのVoyager [22])はそれぞれ、複合的システムにおける異なる失敗モードに対応する。単独でこの問題への答えになるものはない。実務で持ちこたえているパターンは、タスクが実際に持つ信頼性予算に対して適切な組み合わせを構成することにある。
エージェント型ビジョンにおけるアーキテクチャ上の対応の姿
上述の一般原理は、モダリティがビジョンであり展開先が産業用検査である場合に、より具体的な形に翻訳される。本番で機能しているシステムには、いくつかの設計上の動きが繰り返し現れる。
第一は、責務による分解である。単一のモデルに知覚・解釈・判断を一度にこなさせるのではなく、知覚(検出、セグメンテーション、OCR、深度、追跡)を担う狭いCVモデル群、解釈を担う推論層、検証を担う一貫性層へと作業を分割する。各層の狭いタスクであるからこそ、各層のステップごとの信頼性は高くなる。推論層は生のフレームを直接扱わない。検証層は自由形式の文章を扱わない。層と層の界面は型付けされている。
第二は、関連するが同一ではない論点として、回復をフォールバックではなくファーストクラスの構成要素として扱うことだ。Pedderの言う回復インフラによる2.7倍の等価ゲイン [4] は、専用の検証パスがおおよそ捉えようとしているものに相当する。知覚層の構造化された出力から再構成できない主張は、文章で取り繕われるのではなくブロックされる。ビジョンの世界では、これがテキストの場合よりもなお重要になる。新しい証拠が得られるまで、ある所見が次回の検査機会や次のクリーニング窓を待たねばならないとき、裏付けのない主張の出荷を拒む検証層の有無は、使えるレポートと不確実性を黙って隠したレポートとの差になる。
第三は、状態を外部化することである。ドメイン知識(図面、SOP、履歴)と蓄積されたパターンは、いずれの単一エージェントの会話ウィンドウの外に置かれ、各モデル呼び出しは自らの狭いタスクに関連する文脈の断片のみを参照する。トークンの二次増加問題 [13] はそうすると発生しない。プロンプトが履歴で膨張しないためだ。
第四は、自律性を能力から自然に立ち上がるものではなく、意図的な設計選択として扱うことである。Feng, Morris, Mitchell の Levels of Autonomy for AI Agents(2025)[23] はこの区別を形式化している。エージェントの出力が物理的な動作を駆動する場面では、自律性は知覚層で高く(検出器は見たものをフラグする)、行動層では強く制約される(オペレータが行動前に確認する)のが、最も有用な配置となる。誤った自律的行動のコストは、編集可能な段落ではなく運用上の帰結として支払われる。
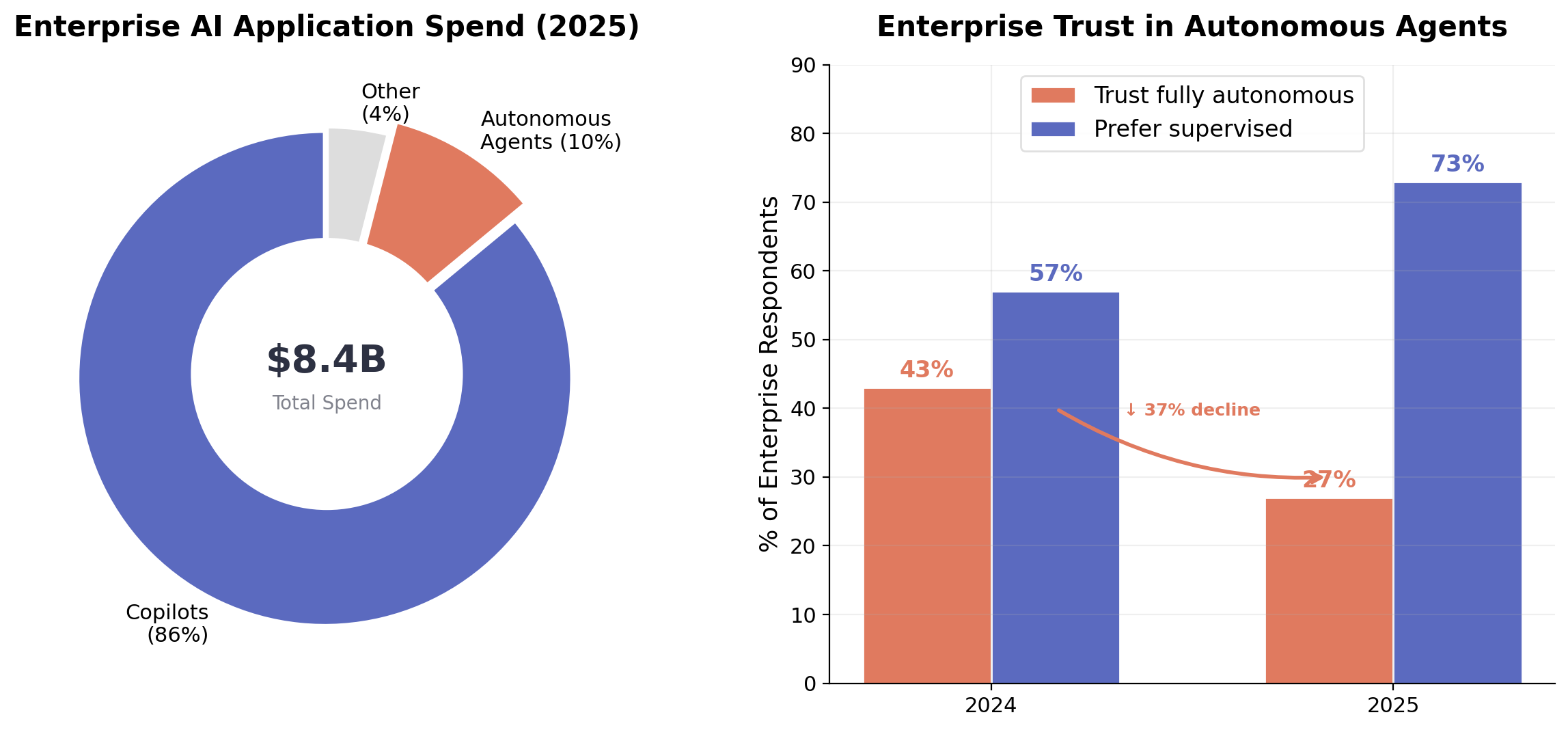 図4. 左: 2025年のエンタープライズAIアプリケーション支出。コパイロットと自律エージェントの比較 [2]。右: 完全自律型エージェントへの調査ベースの信頼度は前年比で低下した [1]。
図4. 左: 2025年のエンタープライズAIアプリケーション支出。コパイロットと自律エージェントの比較 [2]。右: 完全自律型エージェントへの調査ベースの信頼度は前年比で低下した [1]。
市場データは、信頼性インフラの現状がどこにあるかを映し出しており、ここで述べたアーキテクチャ上の対応はその姿と整合的である。
この全体の底に流れる未解決の問いは、アーキテクチャそのものを人手で設計するのではなく学習可能にできるかどうかである。推論モデルのツール選択ポリシーを、それが呼び出す専門モデル群と共同で訓練し、ステップの妥当性ではなく成果の質を最適化対象とする方向は、現在活発に研究されている。これは、プリンストンの「18か月の能力向上が信頼性をほぼ変化させなかった」という発見 [6] に対する一つの答えになりうる。すなわち、信頼性は単一モデルに閉じた性質ではなく、より良い単一モデルを待っているだけでは生まれない。
残された地点
証拠は一点に収束する。本番環境の信頼性に関する限り、今のところさらなるモデル能力の向上よりも、エンジニアリング上の規律のほうがギャップの大きい部分を担っている。プリンストンの「18か月の能力向上が信頼性をほぼ変化させなかった」という発見。Cognizantが示した、構造の整った領域では適切なアーキテクチャを備えた小型モデルが、コストあたりの信頼性で大型モデルに匹敵あるいは凌駕しうるという結果。Anthropicがツール記述の改良を一部の理由としてSWE-benchの最先端を達成した事例。
複合的な信頼性低下の問題は、次世代モデルで克服される一時的な制約ではない。それは逐次システムの構造的性質であり、機能する対応もまた構造的だ。すなわち、分解、検証、回復、そして信頼性インフラが支えうる範囲に限定された自律性である。これらが人手で取り付けられるか、いずれエンドツーエンドで学習されるかは、いまだ未解決の問いである。
References
- Capgemini, "Trust and Human-AI Collaboration Set to Define the Next Era of Agentic AI." 2025. capgemini.com
- Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
- Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." June 2025. gartner.com
- C. Pedder, "When agents fail: compounding errors in organisational systems." Substack, 2025
- M. Cemri, X. Pan, et al., "Why Do Multi-Agent LLM Systems Fail?" NeurIPS 2025. arXiv:2503.13657
- S. Rabanser, S. Kapoor, A. Narayanan, "Towards a Science of AI Agent Reliability." 2026. arXiv:2602.16666
- T. Kwa et al., "Measuring AI Ability to Complete Long Tasks." METR, 2025. arXiv:2503.14499
- T. Ord, "Is there a Half-Life for the Success Rates of AI Agents?" tobyord.com, 2025
- J. Yang et al., "SWE-bench Goes Live!" arXiv:2505.23419
- SWE-bench Pro Leaderboard. swebench.com
- S. Zhou et al., "WebArena: A Realistic Web Environment for Building Autonomous Agents." arXiv:2307.13854
- Epoch AI, "What does OSWorld tell us about AI's ability to use computers?" epoch.ai, 2025; T. Xie et al., "OSWorld: Benchmarking Multimodal Agents." arXiv:2404.07972
- "How Do Coding Agents Spend Your Money?" ICLR 2026 submission. OpenReview
- IKANGAI, "The LLM Cost Paradox: How 'Cheaper' AI Models Are Breaking Budgets." ikangai.com
- Anthropic, "Manage costs effectively, Claude Code Docs." code.claude.com
- E. Meyerson et al., "Solving a Million-Step LLM Task with Zero Errors." Cognizant AI Lab, 2025. arXiv:2511.09030
- E. Schluntz, B. Zhang, "Building effective agents." Anthropic, Dec 2024. anthropic.com
- OpenAI, "A Practical Guide to Building Agents." 2025. openai.com
- O. Khattab et al., "DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines." NeurIPS 2023. arXiv:2310.03714
- S. Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. arXiv:2210.03629
- N. Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. arXiv:2303.11366
- G. Wang et al., "Voyager: An Open-Ended Embodied Agent with Large Language Models." TMLR 2024. voyager.minedojo.org
- G. Feng, M. Morris, K. Mitchell, "Levels of Autonomy for AI Agents." 2025. arXiv:2506.12469