
Project PLATEAUの上に29都市分のデータを一気通貫で索引化した経験を踏まえ、公開された災害データセットが実運用に耐えるか否かを左右する、たった一つの列について論じる研究ノートである。索引化パイプラインはオープンソースのplateau-bridgeとして公開している。
PLATEAUを土台に作られた多くのパイプラインは、
river_flood_covered = trueかつriver_flood_depth_max = 0という行を「この建物はモデル化されたうえで安全と判定された」と読んでいる。この読み方は誤っており、実際のPLATEAU 2024データを使ってどの程度誤っているかを測定した。東京・杉並区だけを取っても、PLATEAUの洪水レイヤーが当該エリアのモデル化深度を一切持っていないにもかかわらず、約6万3,000棟が「調査済みで安全」として水増しされる。これらの建物に対する誠実な分類はcovered = false(つまり「分からない」)であり、その答えを返せない災害データセットは、保険、不動産デューデリジェンス、自治体の防災計画のいずれにも実運用には使えない。
災害テーブルにエンジニアが最初に加える列は、深度や「ゾーン内か否か」を表す値、すなわち「この建物にとって洪水はどれくらい深いか」である。この列は必要だが十分ではない。「深度0」という値は曖昧で、「モデルがこの地点を考慮し、浸水しないと判定した」という意味にもなれば、「モデルがそもそもこの地点を見ていない」という意味にもなる。この二つの状態を一つの行で同じように扱う災害データセットは構造的に不誠実であり、データを受け取る側は両者を後から区別することができない。
この区別を支えるために必ず置かなければならない列が、本稿で カバレッジ信頼度(coverage confidence) と呼ぶフィールドであり、実際のPLATEAU都市に対してそれを埋めようとしたときに見えてくる設計上の制約を以下で扱う。論点は三つに集約される。第一に、ソースメタデータが許容する素朴な既定値(declared_full_admin)は、本稿が対象とした都市群のほぼすべてでカバレッジを系統的に過大評価する。第二に、MLITのKSJポリゴンを照合するという一見明らかな修正は、多くの都市でかえって事態を悪化させる。PLATEAU同梱の洪水ポリゴンが、対応するKSJポリゴンを 逆に 内側に含んでしまう場合があるためである。第三に、この二つを踏まえてなお成立する設計が、新しい信頼度ティア inundation_bounded と、その昇格が安全か否かを判定する整合性チェックの組み合わせである。
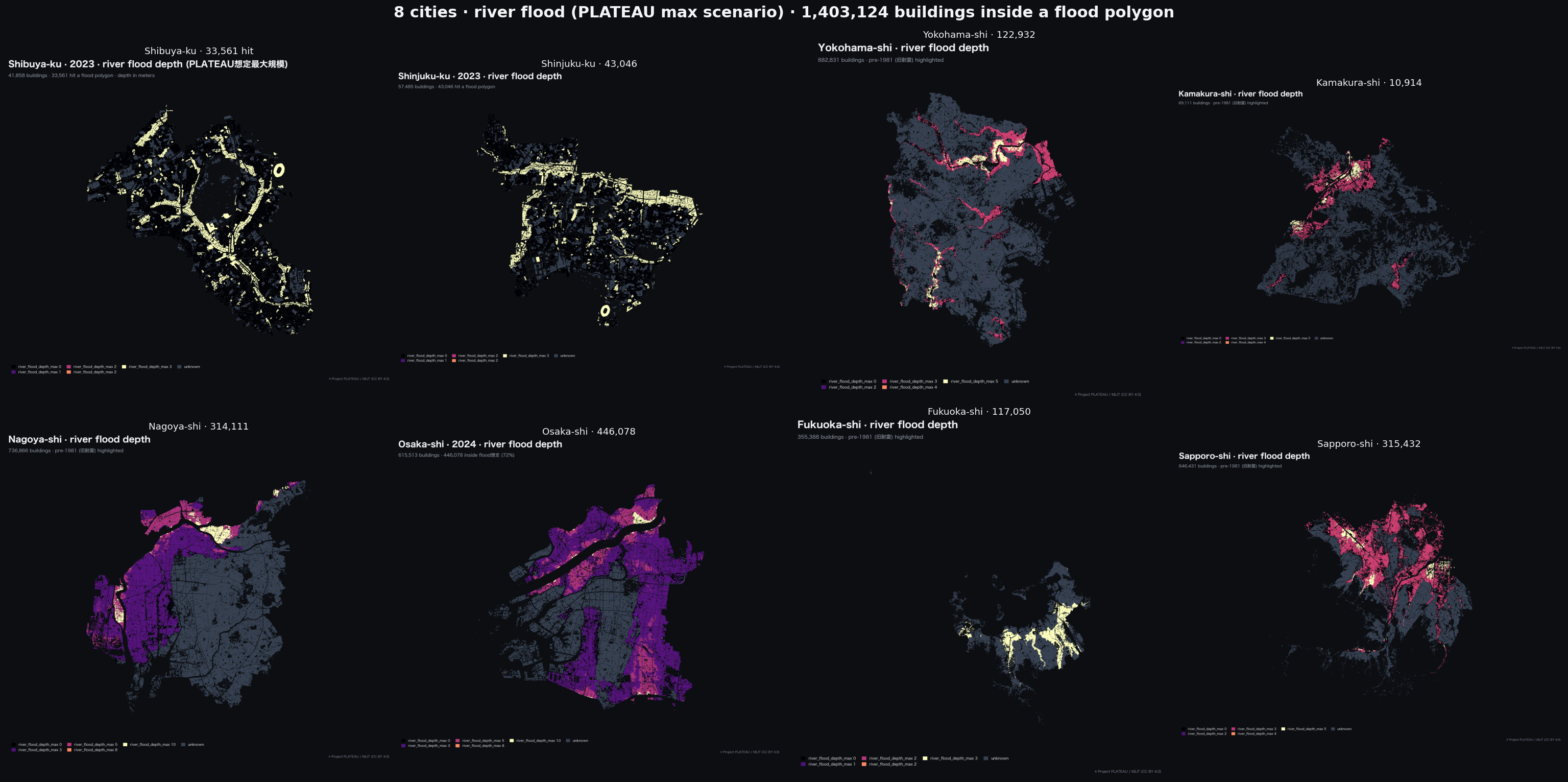
実証作業は29都市・5,258,094棟、つまり東京23特別区と6つの地方都市(横浜、鎌倉、名古屋、大阪、福岡、札幌)を対象とした。各都市を候補となる信頼度モデルごとに再構築し、行レベルの分類を突き合わせている。この結果を生み出した索引化パイプラインはplateau-bridge [1]としてオープンソースで公開しており、リゾルバが守るデータ整合性の不変量はコードベースから参照される別ドキュメントに記録してある [2]。リンクは結果の再現可能性のためのものであり、本稿はツールではなく発見そのものを扱う。
たった一つの列が、災害データセットの誠実さを決める
建物行に付された災害列は、その行の エピステミック状態、つまり「何が分かっていて何が分かっていないか」を記録する列と対になって初めて意味のある情報になる。最低限のスキーマは、災害種別ごとに次の5フィールドである。
{kind}_covered # この建物は調査範囲の内側にあったか
{kind}_coverage_source_ids # どの主体が調査したと主張しているか
{kind}_coverage_confidence # その「covered」の主張がどれだけ信頼できるか
{kind}_depth_max # 深度。covered = true のときのみ意味を持つ
{kind}_hit_source_ids # 実際にヒットした浸水ポリゴンはどれか

本稿が扱うのは三つ目のフィールドである。役割は「パイプラインがどのようにしてこの建物をカバーされていると判断したか」を残すことにある。この列がなければ、行はデータとしては技術的に正しいまま、解釈の段階で誤読を招く。慎重な調査の結果「安全」と結論したケースと、調査そのものが行われていないケースという、根本的に異なる二つのエピステミック状態が、下流のクエリにとっては区別できなくなるからである。
セマンティクスはISO 19115の系統・品質フレームワーク [3] を踏襲し、ただ一つの強い不変量で担保する。すなわち covered = false ⇒ depth = null である。調査されていない建物に深度値があってはならず、パイプラインは0ではなく null を書き込み、下流のUIはその null をはっきり区別された視覚状態として表示しなければならない。代表的なエッジケース(重心が浸水ポリゴン内にあるがカバレッジ範囲の外にある建物など)に対してこの不変量を固定するテストがコードベース側に置かれており、リグレッションを抑え込んでいる [2]。
設計上のインパクトは小さい。coverage_confidence を 第一級フィールド として追加するストレージコストは、深度フィールドそのものとおおむね同等で、災害ごと建物ごとに短いenum値が一つ増えるだけである。526万棟×5災害種別でおよそ2,500万個のenum値だが、ZSTD圧縮と辞書符号化を効かせたParquetでは、ディスク占有はバンドル全体の1%にも遠く及ばない。データセット全体の意味を支える区別を担う列を持つために必要なストレージは、実質的にゼロに近い。
素朴な既定値:declared_full_admin
最も自然な出発点は、ソースメタデータの記述をそのまま信用することであり、PLATEAU上に公開されている多くのパイプラインが明示的にであれ暗黙にであれそうしている。PLATEAUの metadata/udx_*_op.xml には、テーマごとに「全行政区域を対象として作成」のような自由記述が含まれる。この宣言があるとき、パイプラインは建物の重心が市区町村の行政ポリゴンと交差していれば covered = true を立てればよい。これが以下で declared_full_admin と呼ぶ信頼度ティアである。
しかし declared_full_admin は、本稿で扱った日本の都市のほぼすべてでカバレッジを過大に見積もる。差分は小さくない。仕組みは単純で、MLITは市区町村のすべての敷地を実際に調査しているわけではない。洪水想定は、河川沿い、海岸沿い、流域低地など、洪水のリスクが高い地域を対象に作成される。モデル化された水系から離れた高台に立つ建物は、公開されている洪水レイヤーが深度値を記録している領域の外側に位置する。誠実な分類は モデル化された深度の証拠がどちらにも存在しない であって、モデル化されて安全と判定された ではない。
PLATEAUメタデータの自由記述は、それが主張しているレベル(このデータセットが「全行政区域を対象として」作られている、というレベル)では技術的に正しい。一方で、下流の利用者が本当に知りたい問い、すなわち「この個別の建物は調査されたのか」という問いには答えていない。結果として、declared_full_admin の下で covered = true, depth = 0 というラベルが付いた行は、まさにカバレッジ信頼度フィールドが解消すべき意味で曖昧なまま残る。
この問題を真剣に扱う価値があるのは、実証された規模ゆえである。東京の杉並区は、その大部分が内陸の起伏地で、市街地のかなりの面積がMLITのモデル化された河川洪水区域の外側にあるため、説明用の好例である。declared_full_admin の下では、杉並区のパイプライン出力は 142,660棟を covered = true と分類し、そのうち 79,912棟 が洪水想定(depth > 0)と交差し、残る 62,748棟 が depth = 0、すなわち「調査済みで安全」を含意するラベルで符号化される。PLATEAUがモデル化深度を記録している領域に絞り込む(その構成は次の二節で示す)と、これら「暗黙の安全」行のほぼすべてが unknown に再分類される。本稿後半の表は、新しいリゾルバの下で杉並区について 63,064棟 を unknown と記録する。内訳は単純で、covered = true のベースライン142,660棟が inundation_bounded の下で80,389棟に下がり、約62,000棟がそのまま 新規の unknown になる。63,064との差はベースラインの段階ですでに unknown だった建物(行政ポリゴンの縁から重心が外れたケース)を反映した小さな残差である。hit 列は両構成でほぼ動かず(79,912 → 80,389、1%未満の境界端の差)、ベースラインの「重心 vs ポリゴン」テストでは外れていた建物が、新しいリゾルバの下でモデル化深度ポリゴンと交差した分にすぎない。
一つの区でこれだけの再分類が起きるのは例外事象ではなく、典型例である。23特別区と6つの地方都市にわたって、各都市の地形に応じた違いはありつつも、同程度の規模が観察された。パターンは一貫していて、declared_full_admin は実用的な既定値ではあるが、無条件のラベルとして出荷できるものではない。
一見明らかな修正が機能しない理由
declared_full_admin が過大評価だと分かったあとに自然に出てくる次の一手は、行政境界をクリップするための 権威ある調査範囲ポリゴン を持ってくることである。MLITはそうしたポリゴンを国土数値情報(KSJ)カタログ [4] で別途公開している。関連シリーズは A31(洪水浸水想定区域)である。各PLATEAUソース文書に対応するA31ポリゴンを引き、行政境界と交差させ、その結果を明示的な範囲として用いる。これが教科書的な答えである。
このアプローチに対応するリゾルバを実際に組んだ。PLATEAUのメタデータXMLからソース文書名(各災害レイヤーを供給する洪水想定文書を指す、自由記述の日本語文字列)を取り出すパーサ、各ソース文書名をKSJのダウンロードURLに対応付ける coverage_sources.json、KSJポリゴンを取得して統合し単一の CoverageExtent にまとめるダウンローダから成る。実験用のマッピングテーブルには、東京・神奈川・大阪を対象とするA31都道府県エントリ39件を入れた。このパイプラインを杉並区に対して走らせ、出力を確認すると、設計が抱え込まなければならない失敗モードが姿を現す。KSJを explicit_polygon とする構成では、杉並区の分類は次のように変わる。
| 信頼度ティア | covered = true 棟数 |
うち depth > 0 |
|---|---|---|
declared_full_admin(ベースライン) |
142,660 | 79,912 |
explicit_polygon(KSJ A31のみ) |
10,786 | 10,764 |
「カバーされた」棟数は約143,000から約11,000へ、ヒット棟数も約80,000から約11,000へと連動して落ちた。この急減には二つの解釈がありうる。一つ目は、declared_full_admin が大きくカバレッジを過大評価していて、KSJポリゴンこそが本当の調査範囲を明らかにしているという解釈。もう一つは、こちらが不完全なポリゴンに対してクリップした結果、今度は大きくカバレッジを過小評価しているという解釈である。
杉並区の洪水レイヤーに関するPLATEAU自身の公開メタデータを追っていくと、正しいのは二つ目だと判明する。杉並区のPLATEAU 2024 udx/fld/ データは、荒川水系の支川(荒川水系神田川・善福寺川・妙正寺川 など。一部はKSJ A31の都道府県管轄ファイルに収載されている)に対する都道府県河川の浸水想定に加え、東京都の流域浸水予想区域図シリーズ(神田川流域 ほか)からも供給されている。後者はKSJ A31には収載されていない、独立した東京都の市街地洪水想定である。都のシリーズは、国のA31シリーズがカバーしない都市型水害(小流域への集中豪雨など)のシナリオまで含む。
ずれを最もはっきり見るには、各ソースが杉並区において何をカバーしているかを並べてみればよい。KSJ A31-21_13(東京都)は41,051個のポリゴンを含み、そのうち2,087個が杉並区の行政ポリゴンと交差し、区の土地面積の約10.2%をカバーする。これに対しPLATEAU同梱の洪水ポリゴンは、declared_full_admin の下で区の142,660棟のうち79,912棟(建物重心で約56%)に当たる。KSJポリゴンはPLATEAUがモデル化深度を記録している範囲の厳密な部分集合であって、上位集合ではない。
この結果、KSJ A31を explicit_polygon の範囲として使うことは、PLATEAUがすでに保持しているデータを能動的に 覆い隠す 操作になる。立地が東京都の流域浸水予想区域図シリーズによってモデル化され、PLATEAUの洪水ポリゴンから非ゼロの深度値が割り当てられている建物は、素朴に「KSJを範囲とする」構成の下では、その立地がKSJ A31の境界の外側にあるという理由で covered = false と分類されてしまう。パイプラインは、すでに計算済みの深度値を持つ建物について depth = null を上書きすることになる。これは二つの誤りのうちはるかに深刻な側である。declared_full_admin の過大評価は少なくとも下流の利用者が解釈できる深度値そのものは残すが、KSJに誘発された誤りは、既知の深度値を null で消して基礎データそのものを破壊する。
「教科書的」な明らかな修正こそが、設計が踏み越えてはいけない失敗モードである、というのが結論である。
導入するティア:inundation_bounded
このプロジェクトの設計の中心には、コードベースのHONESTYドキュメントに明記したデータ整合性ルール [2] がある。「カバレッジ範囲を浸水ポリゴンからリバースエンジニアリングしてはならない」。意図は、既知の洪水ポリゴンをバッファや膨張で広げ、その周辺に「調査済みで安全」なゾーンを捏造する合成的な操作を禁じることにある。「モデルは河川がここで氾濫すると考えている。ゆえに洪水の周囲100mバッファは surveyed-safe である」というのは災害カバレッジに対する典型的な嘘で、調査が行われていない場所について調査が行われたと言い切る点で間違っている。ルールはそうした移動を封じるためにこそ書いてある。
KSJ単独ではPLATEAUがモデル化深度を記録している範囲を完全に過小評価する、という発見はこのルールの読み直しを要求する。浸水ポリゴンをバッファや膨張で広げる操作は、ソースデータが主張していない境界を合成しており、禁じるのが妥当である。一方、PLATEAU同梱の洪水ポリゴンを その境界のまま、膨張なしで 統合する操作はまったく性質が違う。合成的な主張を一切行っていないからである。そこから生まれる境界は、PLATEAU同梱のモデル化深度ポリゴンの境界そのものであり、こちらが報告するのもまさにそれである。パイプラインは洪水のまわりにバッファを引いて安全を主張しているのではなく、モデル化されていない領域について モデルが存在しないこと を主張している。
この区別が新しい信頼度ティア inundation_bounded の根拠となる。コード上のルールは次のとおり。災害テーマについてPLATEAUが建物単位の洪水深度ポリゴンを同梱している場合、それらのポリゴンの和集合を(バッファなし、膨張なし、平滑化なしで)カバレッジ範囲とする。和集合の内側では covered = true とし、深度値は交差するポリゴンからコピーする。和集合の外側では covered = false, depth = null とする。このティアは declared_full_admin より厳しい(暗黙の安全捏造を排除する)一方、KSJ単独に対する explicit_polygon より広い(PLATEAUが持つがKSJに載っていない都道府県・東京都のソースを取り込める)。
リゾルバは信頼度の高い順に、四つのティアを順番に当てる。
explicit_polygon. カタログに名指しで載っている、もしくはKSJから自動解決された、別途公開済みの想定区域・調査範囲ポリゴン。公開ポリゴンは調査主体自身が「ここを調査した」と主張する境界であり、最も強い信号となる。inundation_bounded. PLATEAUが建物単位の洪水ポリゴンを同梱している場合に、その和集合を範囲とする。データの文字通りの内容、すなわち和集合の内側は深度値を持つモデル化済み、外側はモデル化されていない、をそのまま記述する。declared_full_admin. ソースメタデータが全行政区域カバレッジを主張し、かつステップ2が適用できない場合に、行政ポリゴンと交差を取る。PLATEAU同梱が建物単位のポリゴンを持たない災害テーマのために残している。unknown. どれにも当てはまらない。covered = false,depth = null。下流のUIはこの状態を別個に表示する必要がある。

このリゾルバの実装は、GeoPandasを使ったPythonでおよそ250行に、メタデータXMLパーサとKSJダウンローダを加えた程度に収まる。実装そのものは平凡で、設計を支えているのは上記の順序付けと、次節の整合性チェックである。
整合性チェック:KSJマッピング不完全による失敗を抑え込む
上記の四ティアリゾルバは単独では正しいが、特有のリグレッションを抱えうる。coverage_sources.json のマッピングテーブルが流域について埋まったとたん(つまり当該災害について explicit_polygon がKSJポリゴンに解決されるようになった瞬間)、ステップ1がステップ2に優先する。KSJポリゴンが、PLATEAUが実際にモデル化している領域に対して不完全な場合、まさに上述の杉並/東京都流域浸水予想区域図シリーズの構図のように、explicit_polygon への昇格はPLATEAUに深度値が存在する建物について null を書き込む結果になる。カバレッジ信頼度を 改善 するはずの昇格が、データを破壊する操作そのものに化けてしまう。
防御策はリゾルバ内部の整合性チェックで、ステップ1とステップ2のあいだに挟む。KSJから候補の explicit_polygon を計算したあと、リゾルバはその候補とPLATEAU同梱の浸水ポリゴンの交差を取り、面積比、すなわち 候補に含まれるPLATEAUの災害ポリゴン面積の割合 を求める。この比率が閾値(現状0.95、95%)を下回るときは、その候補を棄却し、リゾルバは inundation_bounded にフォールスルーする。閾値は意図的に保守的に設定している。ほぼ完全なKSJマッピングを inundation_bounded に降格させてしまうリスクのほうが、実深度データを覆い隠してしまうリスクより、はるかに許容しやすいからである。
この挙動はコードベースの二つのテストで固定されている。
test_resolver_falls_back_when_ksj_insufficient_vs_hazard
test_resolver_accepts_ksj_when_it_dominates_hazard
一つ目は杉並型のケースを固定する。KSJポリゴンがPLATEAUの災害領域の15.5%しかカバーせず閾値を大きく下回るときは、inundation_bounded にフォールスルーしなければならない。二つ目はその裏側のケースを固定する。KSJポリゴンがPLATEAUの災害領域の95%以上を含むときは受理され、都市の信頼度ティアは explicit_polygon に上がる。この二つのテストが設計意図を固定している。昇格が安全なときは昇格し、昇格がデータを覆い隠す恐れがあるときは、どちらの主体が「より信頼できるはずか」とは関係なく昇格を拒む、ということである。
整合性チェックはビルド時に都市・災害ごとに一回走る。コストは災害ごとに一つのshapely unionと一つの交差面積計算で、他の処理に比べて無視できる規模である。チェックがトリガされるたびにログ行が出るので、新しいKSJマッピングを追加したキュレータは、そのマッピングが不完全だった場合でも、ビルド出力のなかで「どの都市が inundation_bounded に降格し、なぜそうなったか」を直接確認できる。データ整合性の失敗はクエリ時に静かに通すのではなく、ビルド時に目立つ形で表に出すべきものである。
29都市にわたる実証結果
四ティアリゾルバで29都市のカタログ全体を再構築し、行レベルの分類を declared_full_admin ベースラインと並べると、集計上の効果はきれいに出る。526万棟のうち、declared_full_admin の下で covered = true, depth = 0 だった約 174万棟 が、inundation_bounded の下では covered = false, depth = null に再分類される。これらは先に説明した「暗黙の安全」行であり、新しいリゾルバの下ではモデル化深度ポリゴンの外側に位置するため、データセットは深度値ではなく「モデル化深度の証拠がない」ことを記録する。
杉並区に絞ると次のとおりである。
| 信頼度ティア | covered = true |
depth > 0(ヒット) |
depth = 0(暗黙の安全) |
|---|---|---|---|
declared_full_admin(ベースライン) |
142,660 | 79,912 | 62,748 |
inundation_bounded(修正後) |
80,389 | 80,389 | 0 |
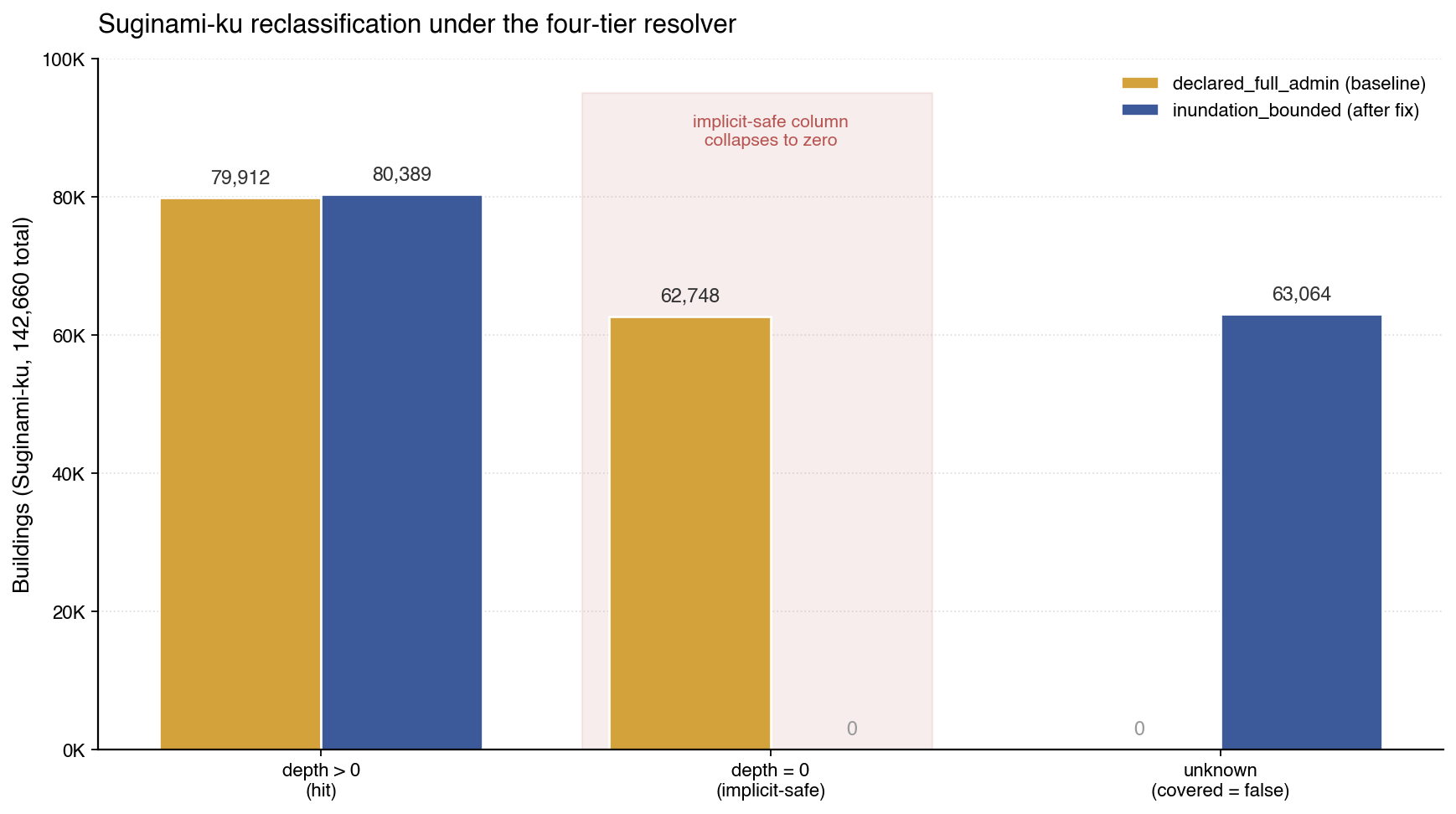
暗黙の安全列は構造上ゼロになる。inundation_bounded の下で covered = true となる行は、範囲そのものがモデル化深度ポリゴンであるため、必ず深度値を持つからである。モデル化領域の外側にある建物は「調査済みで安全」ではなく unknown に分類される。杉並区における63,064棟の unknown という値は、「この区の建物のうちPLATEAUにモデル化された洪水深度が存在しないものは何棟か」という問いに対する誠実な答えである。hit 列は両構成のあいだでほぼ動いておらず(79,912 → 80,389、1%未満の境界端の差)、これは設計が満たそうとしていた性質、つまり再分類が「以前は暗黙の安全だった列」にだけ起こり、「モデル化されかつ浸水する列」では起こらない、ことを示している。パイプラインはデータを隠しているのではなく、「不明なのに安全として記録されていた」建物をラベルだけ付け直しているだけである。
各都市の具体的な数値は地形に依存する。市街地が大きく内陸に広がる区(杉並、世田谷、中野、および地方の福岡、名古屋)が covered 棟数の絶対値で最大の減少を示し、主要河川に隣接する区(江戸川、足立)はPLATEAU同梱の洪水ポリゴンに市街地の多くが収まるため、相対的な減少幅が小さくなる。四ティアリゾルバがベースラインに対して追加する実行時オーバーヘッドは、災害ごと都市ごとに一回の shapely.union_all で済み、最大の都市でも20秒未満で走り切る。
下流に与える意味
カバレッジ信頼度は接合面、つまり別のシステムが建物単位の災害行を受け取って何らかの行動を起こす場所に表れる。ポートフォリオをテーブルに結合する保険引受モデルは、テーブルが covered = false を返してきたときの挙動を決めなければならない。自治体の防災計画ダッシュボードは、建物を 安全、リスクあり、不明 のいずれとして表示するかを決めなければならない。曝露人口の統計を集計する研究パイプラインは、covered = false の行を分母に含めるかどうかを決めなければならない。「安全」既定値は、証拠がないことをもって不在の証拠とみなし、「慎重」既定値は、モデルがないことは危険がないことと同じではないという立場でエスカレーションする。どちらが正しいかは利用者側の判断だが、データセットはその 判断を可能にする ために、行レベルで 安全 と 不明 を別個に符号化しておかなければならない。MLITが一度もモデル化していない建物について surveyed-safe を捏造するデータセットは、その判断の余地そのものを奪う。集計値は「暗黙の安全」行に平均がゼロ側へ引きずられてリスクを過小評価し、UIはデータがこの区別を持たないために unknown を表示できない。
論点はPLATEAU固有のものではない。カバレッジ信頼度フィールドを持たないまま建物単位の深度値を公開するあらゆる公共災害データセットは同じ混同を抱え、下流のあらゆるパイプラインがそれを推移的に引き継ぐ。直すべき場所はソース側である。フィールドがスキーマに最初から存在し、パイプラインがそれを誠実に埋める、というかたちでしか直せない。事後に足そうとすれば、取り込み時に捨てられた情報を復元することになるが、それは通常できない。
残された課題
マッピングテーブルの拡充。 PLATEAUのソース文書名からKSJ URLへの coverage_sources.json マッピングは、もともとコミュニティによる手作業の運用を前提に設計してある。対象は全国でおおよそ150の異なる洪水想定文書で、それぞれ一件ずつ手で照合する。現在のテーブルは東京、神奈川、大阪を対象とする39件のA31都道府県エントリを含む。国の地方整備局のA31ファイル(関東、近畿)と、残る44都道府県への拡張は機械的な作業ではあるが、量はそれなりに大きい。
ソース間の統合。 KSJ単独の修正を失敗させた東京都の流域浸水予想区域図シリーズは、配布形態がPDFレポート中心で、東京都オープンデータを通じて深度・標高に関する機械可読な派生データの一部は手に入るものの、ポリゴン範囲そのものを単一のシェープファイルで公開しているものは見当たらない。PLATEAUのパイプラインはこれらをどこかから取り込んでいるが、リゾルバが直接消費可能な形でポリゴン範囲を取り出すところが、残された一番の課題である。
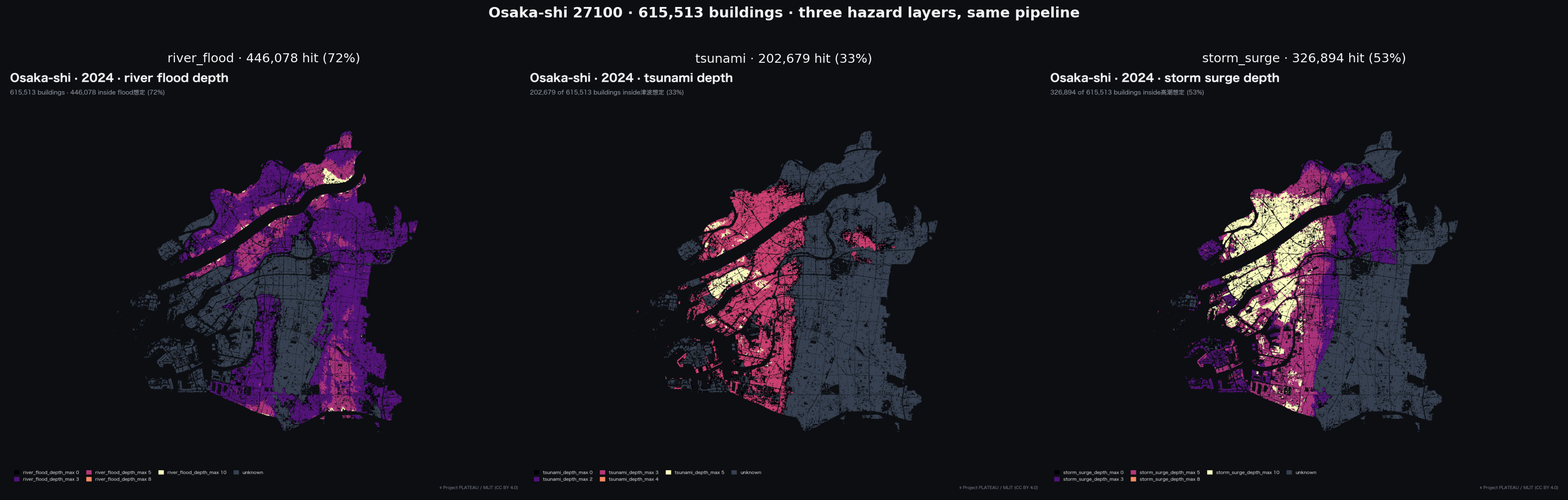
時間軸での結合と、洪水以外のテーマ。 coverage_sources.json の published フィールドはKSJソースの発行年を記録しているが、リゾルバはそれを使って古い explicit_polygon マッチを自動降格する仕組み(A31-2017のポリゴンをPLATEAU 2024の浸水データに当てるようなケースを弾く仕組み)にはまだ結びつけていない。四ティア設計自体は river_flood, inland_flood, tsunami, landslide, storm_surge に対して一様に実装してあるが、本稿の実証結果は洪水に限られる。津波(KSJ A40)、土砂災害(A33)、高潮(A49)でも declared_full_admin の過大評価が同様に発生している可能性は高いが、これらに対する大規模な評価はまだ走らせていない。
References
- plateau-bridge. Open-source pipeline indexing 29 Japanese cities (~5.26 M buildings) from PLATEAU CityGML into queryable Parquet. github.com/pixelx-jp/plateau-bridge, 2026.
- plateau-bridge HONESTY.md. The data-integrity invariants the pipeline enforces, including the
covered = false ⇒ depth = nullrule and the "never reverse-engineer extent from inundation polygons" rule. github.com/pixelx-jp/plateau-bridge/blob/main/docs/HONESTY.md, 2026. - ISO 19115-1:2014, Geographic information: Metadata, Part 1: Fundamentals. The international standard on geographic metadata, including the lineage and quality elements that underlie coverage-confidence semantics. International Organization for Standardization, 2014.
- 国土数値情報ダウンロードサイト (KSJ). MLITの全国地理情報カタログ。本稿に関係するA31(洪水浸水想定区域)シリーズを含む。nlftp.mlit.go.jp/ksj/.
- Project PLATEAU. MLITによるオープンな3D都市モデル整備事業。mlit.go.jp/plateau/.
- OGC CityGML 2.0 specification. PLATEAUのCityGMLファイルが準拠する基礎データモデル。Open Geospatial Consortium, 2012. PLATEAUはさらに日本のi-UR(i-都市再生)Application Domain Extensionを用いており、リゾルバが読み取る建物属性・災害属性のフィールドはこのADEで追加されている。
- M. F. Goodchild, "Citizens as sensors: the world of volunteered geography." GeoJournal 69(4), 211–221, 2007. ユーザー生成の地理情報の品質に関する基礎論文。観測が「そもそも行われたか」を問うカバレッジ信頼度の問題は、ボランタリー地理情報でも類似の形で繰り返し現れる。
- P. Mooney and M. Minghini, "A review of OpenStreetMap data." In Mapping and the Citizen Sensor, Ubiquity Press, 2017. OSMのデータ品質に関するレビュー。
coverage_confidenceに対応する、カバレッジと完全性の指標について論じている。 - G. B. M. Heuvelink, Error Propagation in Environmental Modelling. Taylor & Francis, 1998. データ品質フィールドが結合・集計を通じて伝播するメカニズムの古典的教科書。
inundation_bounded設計の背後にある原理を扱う。 - Apache Parquet. 都市ごとの建物テーブルに用いている列指向ストレージフォーマット。parquet.apache.org.
- MIERUNE plateau-gis-converter (nusamai). PLATEAUのi-UR CityGML拡張に対応するRust製コンバータ。パイプラインはCityGML → GeoJSON 変換をnusamaiにシェルアウトしている。github.com/MIERUNE/plateau-gis-converter.
- DuckDB. 都市別Parquet出力に対するSQL例とベンチマークに用いているインプロセス解析データベース。duckdb.org.