
産業検査におけるコーナーケース検出に関する研究ノート。インフラ検査チームとの実運用から得られた記録である。
インフラ検査において最も難しい場面は、ありふれたものではない。稀でかつ曖昧なものである。電柱に開いたキツツキの穴、風力タービンブレードに走るヘアラインクラック、当該資産種別では誰も見たことのない橋梁金具の腐食パターン。こうしたコーナーケースは出現頻度が低すぎてクローズドクラスの訓練セットを構成できず、しかし見逃せばそれこそが検査プログラムを動機づける失敗様態となる。
クローズドクラスの検出器は不確実性を示すことはできるが、訓練セットに一度も現れていない対象について「ここに何かおかしいものがある」と認識することはできない。この認識はオープンワールド推論であり、知覚パイプラインの上に異なる形のモデルを必要とする。
本ノートは、その層に対するひとつの設計を扱う。すなわち、vLLMを介して提供されるVLMベースの検出器であり、展開成熟度に対応した三段階で適応され、明らかな正常事例を高速な一次パスの検出器で先に除外した上でVLMが走るハイブリッドパイプラインに組み込まれる構成である。同時に、本当に難しい点と、未解決の問題が残る場所も記録する。
クローズドセット検出器がコーナーケースを解けない理由
根本的な不整合は、教師あり検出器のクローズドワールド前提と、実際のインフラ故障がもつオープンワールド性との間にある。
欠陥分布は本質的にロングテール状である。少数の一般的な型(表面クラック、軽微な腐食)がデータセットを占め、致命的な稀少異常は極めて少ない例数とともにテールに位置する。検査対象となった風力タービンのうち、35,000基中およそ8.5%にしかヘアラインクラックは見られなかったが、これは最も致命的でありながら最も検出しにくい欠陥型である [1]。実世界の大量検査における異常率は通常、全サンプルの1%未満に収まる [2]。人手による検査の誤り率は10〜20%に達し、特定の欠陥型に対する見逃し確率は25%にもなる [3]。
各インフラ領域は固有のコーナーケースを抱える。送電線検査ではキツツキの穴(1cm未満)、コロナ放電(紫外光のみ)、構造全体に比して極端に小さい金具の微細な素線ほつれを扱う必要がある [4]。橋梁検査は表面に現れない内部マイクロクラック、複数欠陥の重なり、土埃や植生による遮蔽欠陥に直面する。風力タービンブレード検査では、人の眼にもかろうじて見えるヘアラインクラック、雷誘起の浸食、表面下の層間剥離が問題となり、ブレード1枚の交換に30万ドル以上を要しうる。
10種類の欠陥クラスで訓練されたYOLO系検出器は、既知クラスにいくらデータを足しても11番目を検出することはない。この限界はデータセット規模の問題ではなく、クローズドセットパラダイムに構造的に内在するものである。正解が「ここに何かおかしいものがある」であるときに、検出器が出せる最強の出力が「訓練したどのクラスにも該当しない」であるという状況は、検査プログラムが許容できない失敗様態そのものである。
検討した二つのアプローチ
データ不足下でのオープンエンド検出に対して、一般に提案される手法群は大きく二つある。本稿の設計論の大半がこの選択に立脚するため、両者を順に見ていく価値がある。
オープンセット/ワンショット検出
T-Rex2 [5]、Grounding DINO [6]、DINO-X [7] のようなモデルは、テキストプロンプト、視覚プロンプト(例示バウンディングボックスや点)、あるいはその両方を用いて物体を位置特定する。T-Rex2は産業現場に直接関わる知見を提示した。すなわち、一般的な物体に対してはテキストプロンプトが視覚プロンプトを上回り、稀な物体(出現頻度で800〜1,200位)に対しては視覚プロンプトがテキストを大きく上回るというものである [5]。異常な欠陥パターンは言語化が難しい一方で、例示画像なら容易に示せる。
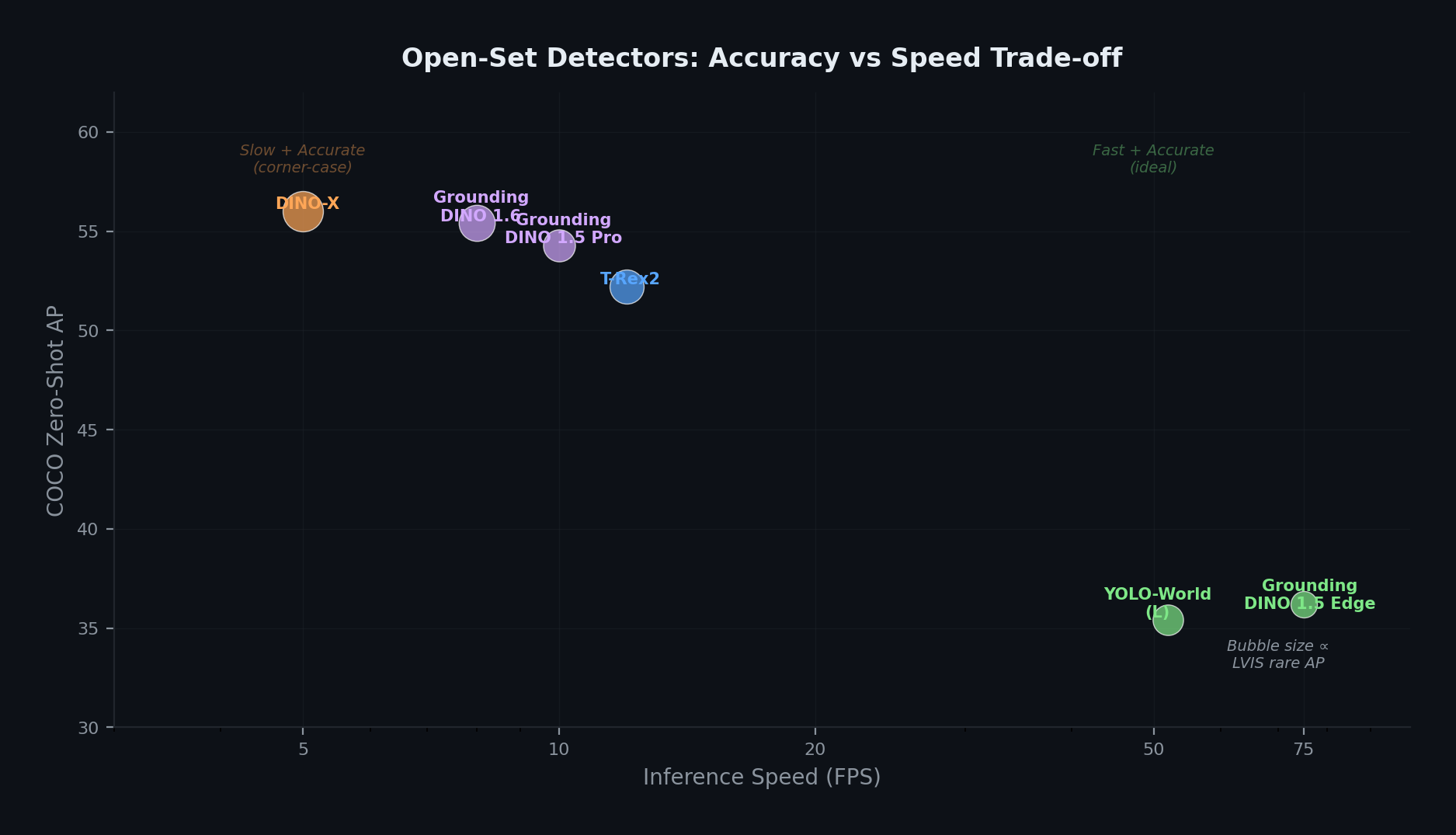 オープンセット検出モデルは精度と速度の明確なトレードオフ上に並ぶ。調査したモデルのうち、DINO-XはCOCOおよびLVIS稀少クラスの両方で最も高いゼロショットAPを報告しており、YOLO-Worldは一次パスのスクリーニングに適したリアルタイム性能を提供する。バブルサイズはコーナーケース検出に最も関連の深い指標であるLVIS稀少クラスAPに比例している。
オープンセット検出モデルは精度と速度の明確なトレードオフ上に並ぶ。調査したモデルのうち、DINO-XはCOCOおよびLVIS稀少クラスの両方で最も高いゼロショットAPを報告しており、YOLO-Worldは一次パスのスクリーニングに適したリアルタイム性能を提供する。バブルサイズはコーナーケース検出に最も関連の深い指標であるLVIS稀少クラスAPに比例している。
DINO-Xは強いゼロショット結果を報告している。すなわちCOCOで56.0 AP、LVIS稀少クラスで63.3 APであり、同論文中で引用された従来最良値に対して5.8 APの向上である [7]。YOLO-Worldは52 FPSで35.4 APを報告しており、Grounding DINO系列より桁違いに高速である [8]。
ただしコーナーケース業務に限れば、オープンセット検出器には実務的な限界がある。本運用では対象がしばしばあまりに一般的または曖昧であり、プロンプト接地型の検出では確実に扱えなかった。「構造的に異常な何か」「予期せぬ変形」といった概念はテキストプロンプトに素直に写像せず、視覚プロンプトに必要な参照ボックスは環境条件をまたいで汎化しないことがある。
VLMベースの推論
Qwen2-VL [9]、InternVL [10]、LLaVA-OneVision [11] といった視覚言語モデル(VLM)は根本的に異なるアプローチをとる。プロンプトからバウンディングボックスを生成するのではなく、自然言語で画像を推論する。VLMには「この電柱に何か異常はあるか」と尋ねることができ、異常の構造化された記述、推定原因、おおよその位置を返すことができる。
産業異常検出向けVLMの進化は急速である。AnomalyGPT(AAAI 2024)は、単一の正常参照画像があれば、VLMが産業異常の標準ベンチマークであるMVTec-AD上で86.1%の精度と94.1%の画像レベルAUCに達することを示し、同時に多ターンの診断対話を支えた [12]。LogicAD(AAAI 2025)は論理的異常(部品の欠落、配置の誤り)に取り組み、MVTec LOCO AD上で86.0% AUROCを報告した。これは同論文で引用された従来手法に対して18.1%の向上である [13]。InfraGPT(2025)は都市インフラの欠陥検出と管理を扱うエンドツーエンドのVLMベース枠組みを提示した [14]。
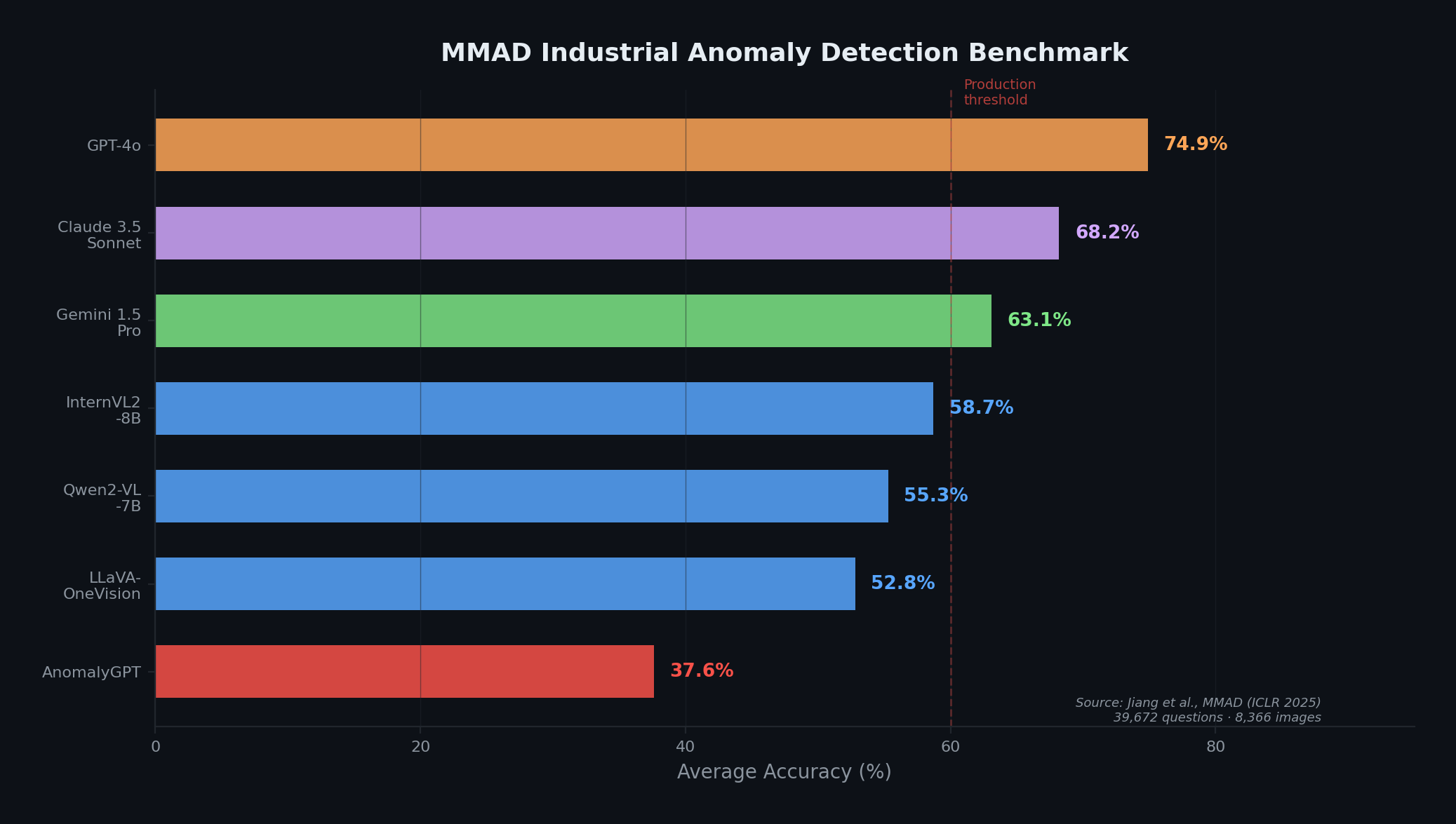 MMADベンチマーク(ICLR 2025)は産業異常検出向けVLM評価の中でも包括的な部類に入り、最先端のフロンティアモデルにも有意な伸びしろがあることを示す。フロンティアAPIモデルとオープンウェイトモデルの差は、ドメイン特化の適応を動機づける。データはJiang et al. [15] による。
MMADベンチマーク(ICLR 2025)は産業異常検出向けVLM評価の中でも包括的な部類に入り、最先端のフロンティアモデルにも有意な伸びしろがあることを示す。フロンティアAPIモデルとオープンウェイトモデルの差は、ドメイン特化の適応を動機づける。データはJiang et al. [15] による。
MMADベンチマーク(ICLR 2025)は8,366枚の産業画像にわたる39,672問を含み、GPT-4oでさえ平均精度は74.9%にとどまると報告している [15]。これは現実を直視させる、示唆に富む結果である。素のVLM能力では不十分であり、本番運用にはドメイン特化の適応が不可欠である。一方、補って余りある性質として、VLMはなぜ異常であるかをネイティブに説明できる。これはクローズドセット検出器には全く備わっていない能力であり、検出結果に基づいて行動するための下流レビュープロセスが必要とするものである。
適応スタック
この評価をふまえ、三つの適応モードを備えたVLMベース検出器に落ち着いた。各モードは独立に動作し、また組み合わせて構成できるように設計されている(たとえばLoRAでファインチューニングしたモデルに対して、推論時にさらにRAGを重ねるなど)。三つのモードは展開成熟度の異なる段階に対応し、段階的に採用できる。
 三つの適応モードは異なる展開成熟度の段階に対応する。インコンテキスト学習は初日からの運用を可能にし、LoRAファインチューニングは本番運用の安定性をもたらし、ビジュアルRAGは再学習なしにドメイン知識を加える。
三つの適応モードは異なる展開成熟度の段階に対応する。インコンテキスト学習は初日からの運用を可能にし、LoRAファインチューニングは本番運用の安定性をもたらし、ビジュアルRAGは再学習なしにドメイン知識を加える。
インコンテキスト学習:即時展開
新たなコーナーケースが特定された際、インコンテキスト学習を使えば同日のうちにモデルへ組み込める。参照画像(正常および欠陥)を指示テンプレートとともにVLMプロンプトに直接配置する。Ueno et al.(2025)は、シングルショットICLでファインチューニングされたViP-LLaVAがMVTec-AD上でMCC 0.804、F1 0.950を達成し、特化モデルと競合することを示した [16]。ユークリッド距離による事例選択がコサイン類似度に基づくRICESを上回るという同論文の知見は、検索設計に対して実務的な含意をもつ。
トレードオフは機械的である。すなわちICLは学習計算量を要しないが、高解像度の検査画像は1枚あたり2,000〜4,000の視覚トークンを消費し、コンテキストウィンドウを急速に埋める。性能は参照画像4〜8枚あたりで頭打ちになる。
Few-shot LoRAファインチューニング:本番運用の安定性
安定かつ再現性のある挙動が必要な反復的検査運用に対しては、LoRA [17] がTransformerのアテンション層に小さな分解行列を導入し、ベース重みを凍結したまま全パラメータの0.1〜0.5%のみを学習する。QLoRAはベースモデルをさらに4-bit NF4に量子化する。Qwen2.5-VL-7Bは、約16〜24 GBのVRAMをもつ単一GPU上でrank 8のQLoRAファインチューニングが可能である。
データ要件は意外なほど控えめである。PLG-DINO(2025)は、LoRAでファインチューニングしたGrounding DINOが低リソース下の産業欠陥シナリオで全YOLO亜種を上回ることを示した [18]。ただしこの結果はVLMではなくオープンセット検出器に対するものである。当方のVLM実験では、500〜2,000のラベル付き例でゼロショットベースラインに対して有意な改善が得られ、5,000例を超えると収穫逓減が見られた。生成されるアダプタは200〜400 MBであり、フルモデル重みの14 GB超に対して大幅に小さい。これにより案件ごとのバージョン管理とA/Bテストが容易になり、各エンゲージメントごとに小さく監査可能な成果物が得られる。
ビジュアルRAG:ドメイン知識への接地
顧客が内部知識(欠陥カタログ、設計ガイドライン、過去の類似事例)を保有している場合、検索拡張生成は推論時に動的にこの文脈を注入する。既知の欠陥画像はCLIPまたはDINOv2の埋め込みでベクトルデータベースに索引化され、各クエリに対して視覚的に類似した上位k件が取得されてVLMプロンプトに注入される。
VisRAGは文書を画像として直接埋め込むことで、テキストベースのRAGに対してエンドツーエンドで20〜40%の向上を示した [19]。Wallace et al. のInspectVLM(2025)は対照的な警告を提供する。すなわち、ドメイン特化の慎重な適応を欠いた統一VLMアーキテクチャは、検査ドメインが変わると有意に劣化するというものである [20]。
この層におけるRAGの際立った利点は、すべての出力を取得した具体的な証拠と紐付けられる点にある。これが下流のレビューを追跡可能にする。追跡可能性は厳密な監査可能性と同じではない。VLMの最終出力は取得証拠に忠実であることを保証されない。しかし追跡可能性は、人間のレビュアーがモデルの出力に対して反論するために必要な性質であり、クローズドセット分類器が提供できない性質である。
vLLM:これを成立させる推論エンジン
VLMベースの検出器が本番で成立するのは、推論が十分に高速かつメモリ効率に優れる場合に限られる。vLLMはPagedAttentionと連続バッチングを通じてこれを可能にする [21][22]。
PagedAttentionによるKVキャッシュのボトルネック解消
自己回帰生成の間、モデルは過去のすべてのトークンに対するキー行列とバリュー行列(KVキャッシュ)を保持する。高解像度画像を処理するVLMにとって、これは特に要求が大きい。Qwen2-VL-7Bのプロファイリング(FP16のKVキャッシュ、28層、KVヘッド4のGQA、ヘッド次元128)に基づくと、トークン1個あたり約0.03 MBのKVキャッシュを生成し、1024×1024画像1枚で約4,096の視覚トークンを生み出す場合、KVキャッシュだけで100 MB以上を消費しうる。
従来の推論サーバはシーケンスごとに連続したメモリブロックを事前確保するため、断片化と過剰予約によりKVキャッシュメモリの60〜80%を浪費する [21]。
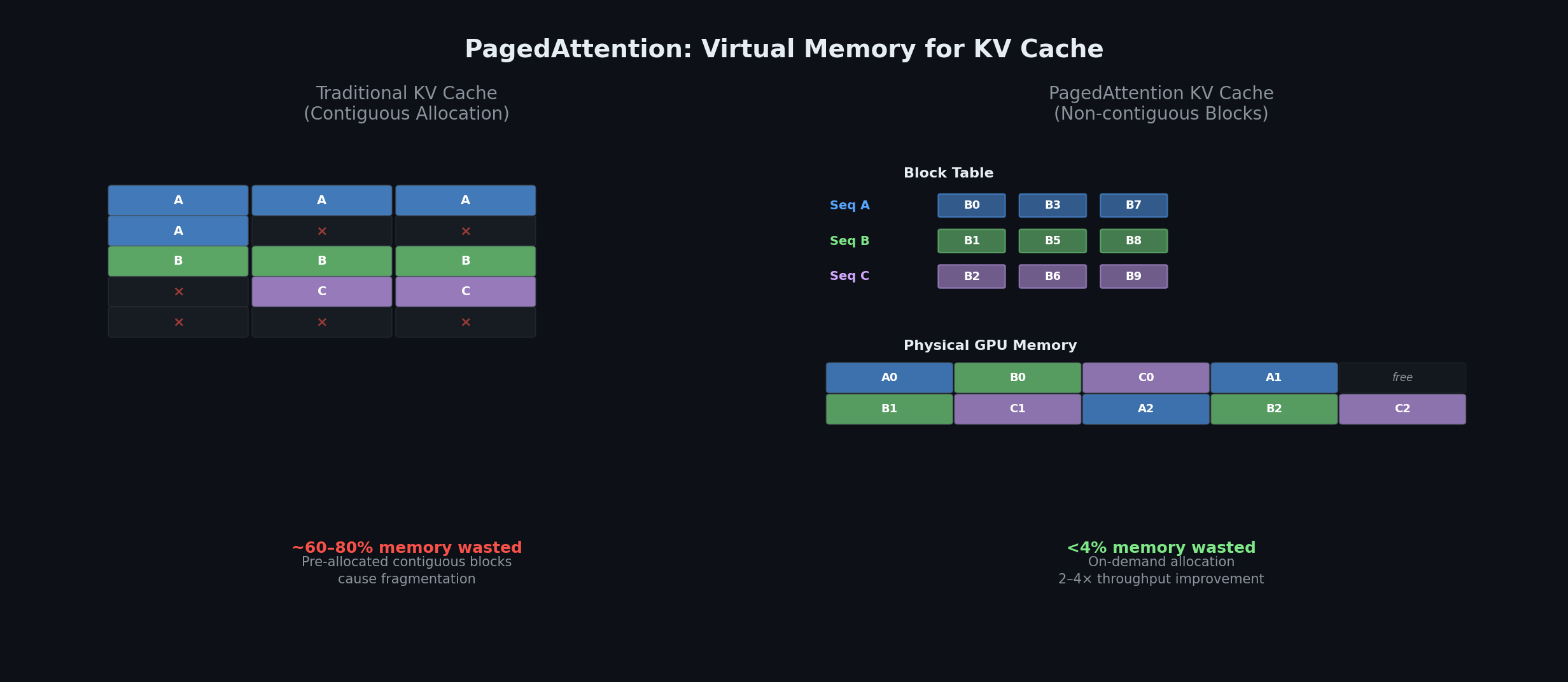 PagedAttentionはオペレーティングシステムの仮想メモリの概念を借用する。KVキャッシュブロックは非連続な物理メモリに格納され、ブロック表を通じて写像される。メモリの無駄は60〜80%から4%未満へと減り、2〜4倍のスループット向上を可能にする [21]。
PagedAttentionはオペレーティングシステムの仮想メモリの概念を借用する。KVキャッシュブロックは非連続な物理メモリに格納され、ブロック表を通じて写像される。メモリの無駄は60〜80%から4%未満へと減り、2〜4倍のスループット向上を可能にする [21]。
PagedAttentionはKVキャッシュを固定サイズのブロック(通常16トークン)に分割してGPUメモリ上に非連続に格納し、各シーケンスはOSのページテーブルに相当するブロック表を保持する。物理ブロックはオンデマンドで割り当てられ、共通プレフィックスについてはcopy-on-writeで共有される。結果として、メモリ浪費は4%未満となり、スループットは2〜4倍に向上する [21]。
連続バッチングによるGPU稼働率の最大化
静的バッチングはバッチ内のすべてのリクエストに最遅シーケンスを待たせる。vLLMの連続バッチングはイテレーション単位で動作する。各デコードステップでスケジューラが完了したシーケンスを取り除き、待機中のものを挿入する。ベンチマークではHuggingFace Transformersに対し14〜24倍、Text Generation Inferenceに対し2.2〜3.5倍のスループットを示す [21]。
vLLM V1におけるVLM固有の最適化
vLLM V1(2025)は重要なマルチモーダル機能を導入した [23]。エンコーダキャッシュは計算済みの視覚埋め込みをGPU上に保持し、類似プロンプト間で視覚エンコーダを冗長に再実行することを排除する。メタデータ拡張プレフィックスキャッシングは単なるトークンIDではなく画像内容のハッシュを用いるため、同じ<image>プレースホルダを共有する別画像同士のキャッシュ衝突を防ぐ。ハイブリッド並列化フラグ(--mm-encoder-tp-mode data)は、視覚エンコーダをデータ並列で走らせつつ言語モデルにはテンソル並列を用いる構成であり、視覚エンコード中のall-reduce通信を削減する。
Red Hatの開発チームはMolmo-72Bを4×H100 GPU上で動かした際、V0比でおよそ40%のスループット向上を報告した [23]。AMDのROCmチームは独立に、データ並列の視覚エンコードを有効化することで画像が支配的な作業負荷に対して有意な高速化が得られることを確認している [24]。
本番展開:ハードウェア、タイリング、ハイブリッドパイプライン
GPUメモリとハードウェア選定
VLMはテキスト専用モデルを上回るVRAMを消費する。視覚エンコーダの重み、視覚トークン埋め込み、クロスモーダルアテンションがその要因である。具体的な要件(当方の見積もり)は次のとおりである。Qwen2-VL-7BはFP16で約16〜17 GBを要し(L40S 1枚にKVキャッシュ分の余地を残して収まる)、INT8では8〜9 GBに下がる。Qwen2-VL-72BはFP16で約144 GBを要するが、FP8であれば4×A100-80GBに収まる。min_pixels/max_pixelsを制約せずに高解像度画像を処理すると、24 GB GPU上でOOMが発生するという報告がある [9]。
本運用では、NVIDIA L40S(48 GB GDDR6)がメモリ、スループット、取得コストの実用的な均衡をもたらし、7B VLMをフル精度で動かしつつKVキャッシュの余地も確保できた。1日あたり1,000枚程度の画像という作業負荷に対しては、L40S 1枚で十分であった。
高解像度検査画像の扱い
産業用カメラは4K以上で撮影するが、VLMの入力制限のために賢いタイリングが必要となる。Qwen2-VLの675Mパラメータ ViTは画像をネイティブ解像度のまま可変トークン数に処理し、min_pixelsとmax_pixelsで制御される [9]。InternVLは画像を448×448タイル(1〜40タイル、4Kまで対応)に分割し、pixel shuffleにより各タイルを256視覚トークンと全体サムネイル1枚に縮約する [10]。
4K検査画像に対する実務的な手順は次のようなものである。長辺を2048〜4096 pxに抑えるよう事前にリサイズし、欠陥位置特定にスライディングウィンドウクロップを用い、グローバル文脈のため低解像度で全体を処理しつつ関心領域は高解像度クロップで処理し、タイル横断の結果はnon-maximum suppressionで集約する。
ハイブリッドパイプライン
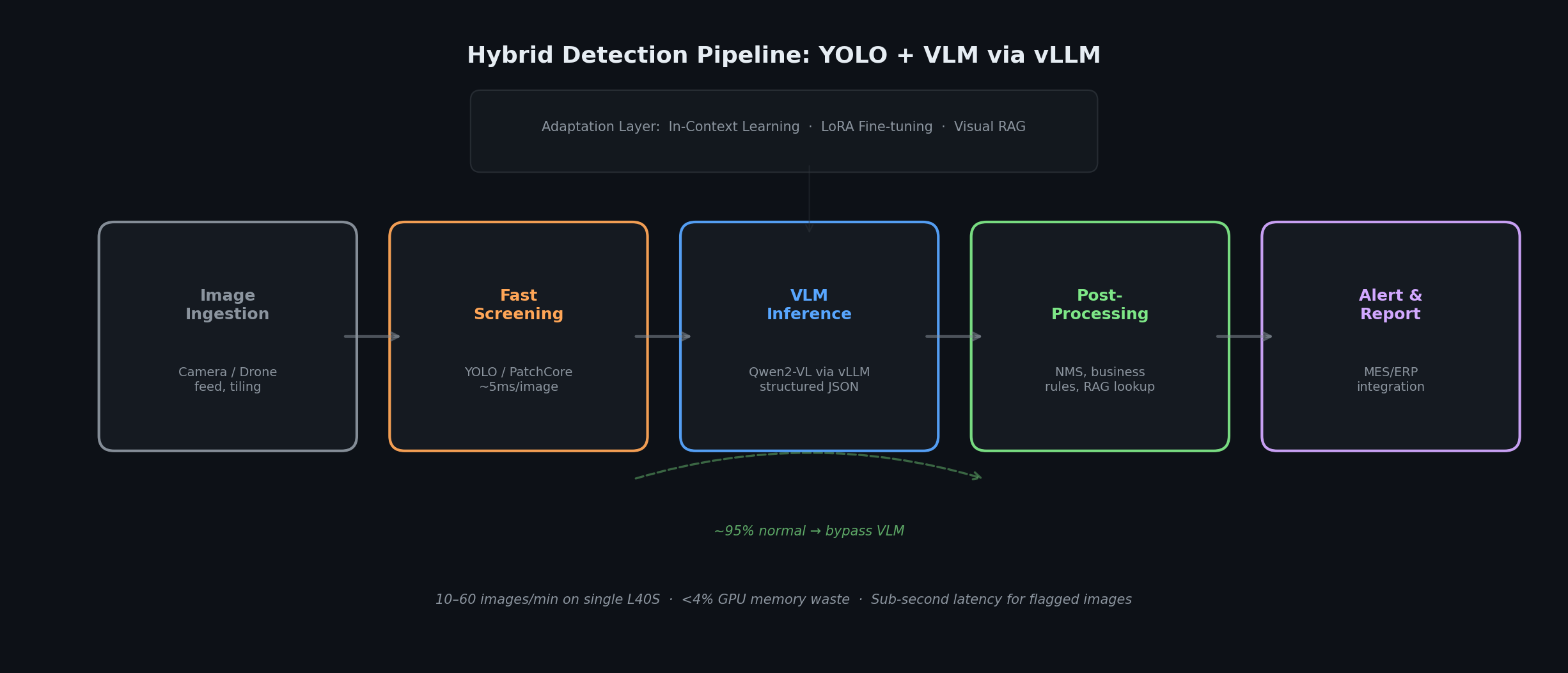 本番パイプラインは高速な一次パスの検出器とVLMを組み合わせる。本運用では画像の約85〜95%が一次パスの検出器によって除外され、VLM推論量は7〜20分の1に削減された。
本番パイプラインは高速な一次パスの検出器とVLMを組み合わせる。本運用では画像の約85〜95%が一次パスの検出器によって除外され、VLM推論量は7〜20分の1に削減された。
ハイブリッドアーキテクチャは速度と深さを併せもつ。カメラやドローンの画像取り込みは前処理サービス(リサイズ、正規化、タイリング)へ流れる。軽量な一次パスの検出器(YOLOなどの物体検出器、PatchCoreのような異常検出手法、SigLIPなどの視覚言語エンコーダ)が明らかに正常な事例を除外する。**重要なのは、この一次パスの検出器を高精度ではなく高再現率に振ることである。**その役割は、明らかに正常な画像のみを自信を持って除外しつつ、不確かであったり境界線上にあるものはすべてVLMへ回すことにある。精度に振った第一段は、まさしくVLMで拾うべきコーナーケースを濾し落としてしまい、そもそも下流にVLMを置く意義を損なう。
本運用では、一次パスの検出器の動作点は意図的に低めの閾値を超える異常スコアをもつ画像すべてを残し、加えて設定可能な割合の「不確か」サンプルを通過させる構成とした。OpenAI互換APIを介してvLLMで提供されるVLMは、フラグの立った画像のみを構造化システムプロンプトで処理し、欠陥種別、位置座標、深刻度、自然言語の根拠を含むJSONを返す。後処理は複数タイル結果の集約、業務ルールの適用、顧客の欠陥カタログとの突合を担う。アラートは既存のMES/ERPシステムと統合される。
主要なvLLM設定は次のとおりである。KVキャッシュを最大化するための--gpu-memory-utilization 0.9、繰り返されるシステムプロンプトに対するプレフィックスキャッシングの有効化、リクエストあたりメモリを制限する--limit-mm-per-prompt "image=5"、長い画像プロンプトがデコードを塞がないためのchunked prefill。
動作条件付きの性能指標。 スループットとレイテンシは異なる動作点をもつ別個の指標であり、単一の数値でシステムを特徴づけられるという含意を避けるため、各々を測定条件とともに報告する。
- VLM段スループット。 L40S 1枚にQwen2.5-VL-7BをFP16で載せ、長辺1024〜2048 pxの画像入力と60〜200の出力トークンによる構造化出力プロンプト、プレフィックスキャッシング有効化のvLLM V1、バッチ並列度4〜8の条件で、設定点に応じて毎分10〜60枚を計測した。これは1日分の検査画像に対するキャパシティ計画に関連する数値である。
- 単一のフラグ立て画像レイテンシ(P50)。 同じハードウェアとモデル。システムプロンプトをプレフィックスキャッシュ済み、視覚エンコーダを事前ウォームアップ済み、バッチ並列なしの条件で、フラグの立った画像1枚は構造化応答全体をおおよそ1〜4秒で返す。これはオペレータが特定の検出結果を待つ場面における数値である。
- ハイブリッドパイプラインのオペレータ視点レイテンシ。 ハイブリッド構成では、画像のうち一次パスの検出器でフラグの立つのは5〜15%のみであり、これだけがVLMに到達する。一次パスが除外する85〜95%については、オペレータ視点のレイテンシは一次パスのフレームレート(数十ミリ秒)に支配される。したがって日常的な大多数についてはエンドツーエンドで1秒未満の応答が通常となり、フラグ立てされたコーナーケースは上記の画像あたりレイテンシに従う。
- レイテンシ工学上の目標値。 当方のレイテンシ工学ノートで論じる「エンドツーエンドで1秒未満」という目標値は、まったく別の動作領域を指す。より小さなモデル、軽量なプロンプト、ストリーミング出力、完全な応答前に部分結果を提示するUXである。その領域は、ここで述べる構造化JSONの挙動と同一ではない。
これらの数値の一部だけを切り取って引用するのは誤解を招く。本稿では極力それを避けた。
学びと、未解決の作業領域
一連の作業を通じて、三点が際立つ。
ハイブリッドアーキテクチャは本案件において最も強い設計となった。このパターンは、異常率の低い画像主体の検査作業負荷であれば類似のものに適用しうると見られるが、単一案件の主張にとどまる。ミリ秒のレイテンシで動作する一次パスの検出器が正常画像の大多数(当方が観察した条件では85〜95%)を濾し、VLMはクローズドセット検出器が構造的に扱えないコーナーケースに必要な推論深度を供給した。
適応スタックはベースモデル以上に効いた。7B VLMにLoRAでおよそ1,000例のドメイン特化データを学習させ、ビジュアルRAGを重ねた構成は、対象検査タスクにおいて素のフロンティアモデルを大きく上回った。これは単一案件の観察であり、統制下のベンチマークではない。段階的経路(数日でゼロショット、数週でLoRA、数ヶ月でドメイン特化)は、本番精度を積み上げつつ即時の価値を提供した。
このような画像主体の作業負荷に対しては、vLLM V1のマルチモーダル最適化も、旧来の推論サーバ構成では実現しなかった経済性をもたらした。エンコーダキャッシュ、ハイブリッド並列化、メタデータ拡張プレフィックスキャッシングは、画像主体推論のメモリとスループットのボトルネックを的確に狙う。
残る課題は精度である。最良のVLMでもMMADでは74.9%にとどまり [15]、現行手法の限界を炙り出すよう設計されたMVTec AD 2データセットでは、主要手法でも平均AU-PROが60%を下回ると報告されている [25]。この差を埋める作業は活発な研究領域である。すなわち、ドメイン特化のファインチューニング、検査フィードバックからの強化学習(EMIT [26] のような取り組み)、そしてVLMのツール選択方策と呼び出される専門モデルを共同最適化する、ツール使用が学習可能な視覚モデルである。
References
- Shihavuddin et al. "Barely-Visible Surface Crack Detection for Wind Turbine Sustainability." arXiv:2407.07186, 2024.
- Baitieva et al. "Supervised Anomaly Detection for Complex Industrial Images." CVPR 2024.
- Li et al. "Surface Defect Detection Methods for Industrial Products with Imbalanced Samples: A Review of Progress in the 2020s." Knowledge-Based Systems, 2024.
- Zhang et al. "Deep Learning in Automated Power Line Inspection: A Review." arXiv:2502.07826, 2025.
- Jiang et al. "T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy." ECCV 2024. arXiv:2403.14610.
- Liu et al. "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection." ECCV 2024. arXiv:2303.05499.
- Ren et al. "DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding." arXiv:2411.14347, 2024.
- Cheng et al. "YOLO-World: Real-Time Open-Vocabulary Object Detection." CVPR 2024. arXiv:2401.17270.
- Wang et al. "Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution." arXiv:2409.12191, 2024.
- Chen et al. "InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks." CVPR 2024.
- Li et al. "LLaVA-OneVision: Easy Visual Task Transfer." arXiv:2408.03326, 2024.
- Gu et al. "AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models." AAAI 2024 (Oral). arXiv:2308.15366.
- Kim et al. "LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction." AAAI 2025.
- Alani et al. "InfraGPT Smart Infrastructure: An End-to-End VLM-Based Framework for Detecting and Managing Urban Defects." arXiv:2510.16017, 2025.
- Jiang et al. "MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection." ICLR 2025. arXiv:2410.09453.
- Ueno et al. "Vision-Language In-Context Learning Driven Few-Shot Visual Inspection Model." arXiv:2502.09057, 2025.
- Hu et al. "LoRA: Low-Rank Adaptation of Large Language Models." ICLR 2022. arXiv:2106.09685.
- Chen et al. "PLG-DINO: Industrial Defect Detection via Prompt-Learning Grounding DINO." OpenReview, 2025.
- Yu et al. "VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents." arXiv:2410.10594, 2024.
- Wallace et al. "InspectVLM: Unified in Theory, Unreliable in Practice." ICCV 2025 Workshop.
- Kwon et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP 2023. arXiv:2309.06180.
- vLLM Project. github.com/vllm-project/vllm
- Red Hat Developer. "vLLM V1: Accelerating Multimodal Inference for Large Language Models." 2025.
- AMD ROCm Blogs. "Accelerating Multimodal Inference in vLLM: The One-Line Optimization for Large Multimodal Models." 2025.
- Bergmann et al. "The MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection." arXiv:2503.21622, 2025.
- Li et al. "EMIT: Enhancing MLLMs for Industrial Anomaly Detection via Difficulty-Aware GRPO." arXiv:2507.21619, 2025.