
信頼性にはモデルのスケーリングだけでなくエンジニアリングの規律が求められる理由――数学、ベンチマーク、そして市場データが、本番環境で実際に機能するエージェント構築について示していること。
複数のステップを連鎖させるAIエージェントは、よく知られた数学的問題に直面します。固定されたステップごとの成功率を持ち、効果的な回復機構を持たない単純な逐次パイプラインでは、ステップが追加されるごとに信頼性が指数関数的に低下するのです。個々のステップが95%の確率で成功するシステムでも、20ステップを通じたエンドツーエンドの成功率はわずか36%にしかなりません。これはパッチで修正できるバグではなく、回復機構を持たない逐次システムの構造的特性であり、モデルレベルではなくアーキテクチャレベルの解決策を要求するものです。本稿が示すように、分解・投票・状態の外部化といったアーキテクチャ上の選択は減衰曲線を大きく変えうるものの、それは意図的にエンジニアリングされた場合に限ります。
企業がエージェント型AIに莫大な投資を注ぐ中、この複合信頼性問題――そしてその経済的な双子である複合コストスケーリング――を理解することが、この分野の中心的なエンジニアリング課題となっています。過去2年間でAIエージェントの能力は目覚ましい進歩を遂げました。コーディングエージェントのSWE-benchスコアは14%から80%超に跳ね上がりました。WebArenaのタスク完了率は14%から62%に上昇しました。しかし、本番環境へのデプロイは著しく異なる状況を示しています。調査手法の異なる複数の調査からの数値ではありますが、方向性としての全体像は一貫しています。Capgeminiは、AIエージェントのデプロイを完全にスケールさせた企業はわずか2%にすぎないと報告しています [1]。Menlo Venturesは、エンタープライズAIデプロイメントのうち「真のエージェント」に該当するものはわずか16%だとしています [2]。そしてGartnerは、2027年までにエージェント型AIプロジェクトの40%がデプロイ前にキャンセルされると予測しています [3]。これらは直接比較できる指標ではありませんが、総合すると、エージェント型AIの導入が依然として初期段階にあり脆弱であるという像が浮かび上がります。
ベンチマーク性能と本番環境の信頼性のギャップは頑固なまでに広く――以下で提示するエビデンスは、この二つの指標が根本的に異なるものを測定している可能性を示唆しています。本稿では、最近の実証研究、数学的分析、そして実際にエージェントシステムを構築した経験からのアーキテクチャの知見を踏まえ、その理由を検証します。
複合障害の数学は容赦ない
マルチステップエージェントシステムにおける信頼性の核心的な問題は、確率論から直接導かれます。パイプラインがn個の逐次ステップで構成され、各ステップの独立した成功確率がpである場合、エンドツーエンドの成功確率はpⁿとなります。この指数関数的な減衰は、複雑なエージェントワークフローにとって過酷な状況を生み出します:
| ステップごとの精度 | ステップ数 | エンドツーエンド成功率 |
|---|---|---|
| 99% | 10 | 90.4% |
| 95% | 10 | 59.9% |
| 95% | 20 | 35.8% |
| 90% | 10 | 34.9% |
| 99% | 100 | 36.6% |
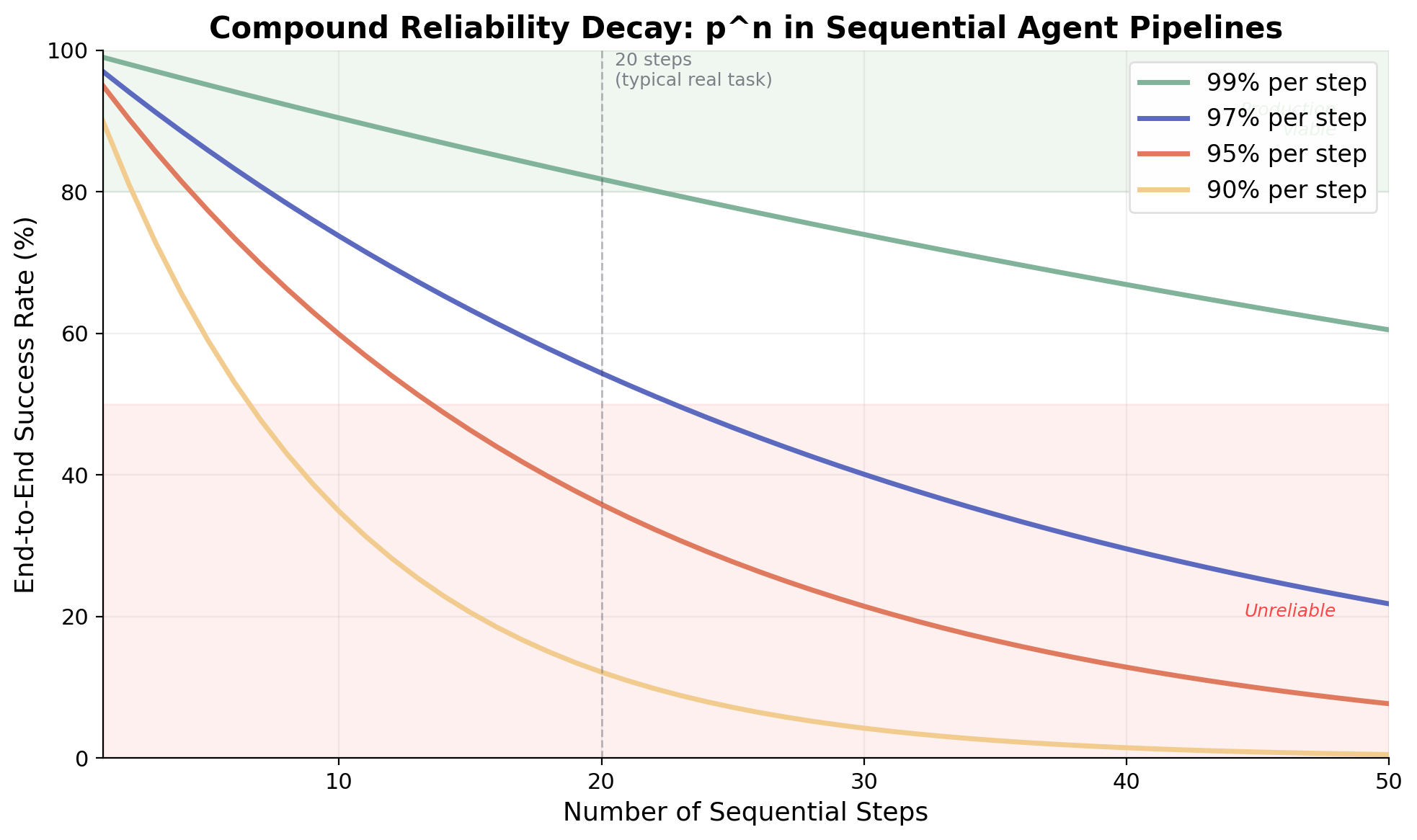
図1. さまざまなステップごとの信頼性レベルにおける、逐次ステップ数の関数としてのエンドツーエンド成功率。99%のステップごとの精度でも、50ステップではわずか60%の成功率にしかならない。
この単純なモデルは、実際の問題を過小評価しています。エージェントパイプラインのステップは独立していることが稀であり、エラーは意味的に伝播し、検出や回復が困難な形で下流のコンテキストを汚染します。Chris Pedderの「障害の粘着性(failure stickiness)」という概念はこれを形式化しています。エラーがパイプラインを通じて不可視に伝播する場合(Pedderが「吸収的障害(absorbing failures)」と呼ぶもの)、ステップごとの信頼性が95%で障害の粘着性が高いシステムは、独立性の仮定が予測するよりも劇的に悪い性能を示します [4]。彼の分析は、エラーから回復する能力が各ステップを2.7倍信頼性の高いものにすることと同等であることを示しており、この発見は信頼性の問題をステップレベルの精度ではなく、回復アーキテクチャの問題として根本的に再定義するものです。
UC Berkeleyの2025年の論文「Why Do Multi-Agent LLM Systems Fail?」(Cemri et al., NeurIPS 2025)は、現時点で最も包括的な実証分析を提供しています [5]。研究者らは7つの主要なマルチエージェントフレームワークにわたる1,600件以上の実行トレースにアノテーションを付け、14の異なる障害モードを特定しました。OpenHandsやMetaGPTなどの人気フレームワークでは、クロスアプリケーションテストで障害率が86.7%に達しました。おそらく最も厳しい事実として、ロール仕様の改善やオーケストレーションの強化といった提案された介入策は不十分であることが判明し、著者らは特定された障害は「より複雑な解決策を必要とする」と結論づけました。
最も厳密な信頼性フレームワークは、Princetonの研究者Rabanser、Kapoor、Narayananによる「Towards a Science of AI Agent Reliability」(2026年)[6]から提供されています。彼らはエージェントの信頼性を4つの次元――一貫性、堅牢性、予測可能性、安全性――にわたる12の指標に分解しました。その中心的な発見は強調に値します。14のフロンティアモデルにおける18か月間の急速な能力向上にもかかわらず、信頼性はほとんど向上していませんでした。 標準的なpass@1指標は、真の信頼性を20〜40%過大評価していることが判明しました。
重要な洞察: 精度と信頼性は根本的に異なる性質です。モデルは問題を解く能力を劇的に向上させつつ、どの問題を解くかについては同じくらい予測不能なままでいられるのです。
エージェントの成功率はタスクの複雑さに応じて指数関数的に低下する
METRのランドマーク研究「Measuring AI Ability to Complete Long Tasks」(Kwa et al., 2025)[7]は、タスクの複雑さに応じてエージェントの性能がどのように低下するかについて、決定的な実証的描像を提供しています。研究者らは「50%タイムホライズン」――エージェントが半分の確率で成功するタスクの長さ(人間換算時間)――を測定しました。Claude 3.7 Sonnetの場合、このホライズンは約50分でした。
Toby Ordのその後の分析 [8]は、一定ハザードレートの仮定――障害確率がタスク全体にわたって均一であるとする簡略化モデル――の下での含意を探りました。このフレーミングでは、エージェントが50分のタスクで50%の成功率を達成する場合、90%の成功率を達成できるのは約7分のタスクに限られ、99%の成功率は約43秒のタスクでしか達成できません。99.9%の信頼性を必要とするエンタープライズアプリケーションでは、使用可能なタスク長はわずか数秒にまで崩壊します。これらは概算的な外挿であり、運用上の測定値ではありませんが、複合信頼性問題の深刻さを端的に示しています。重要なことに、Ordは人間の生存曲線がこの一定ハザードレートモデルよりも明らかに優れていることを発見しました。これは、人間が現在のエージェントよりも効果的にミスから回復していることを示唆しています。
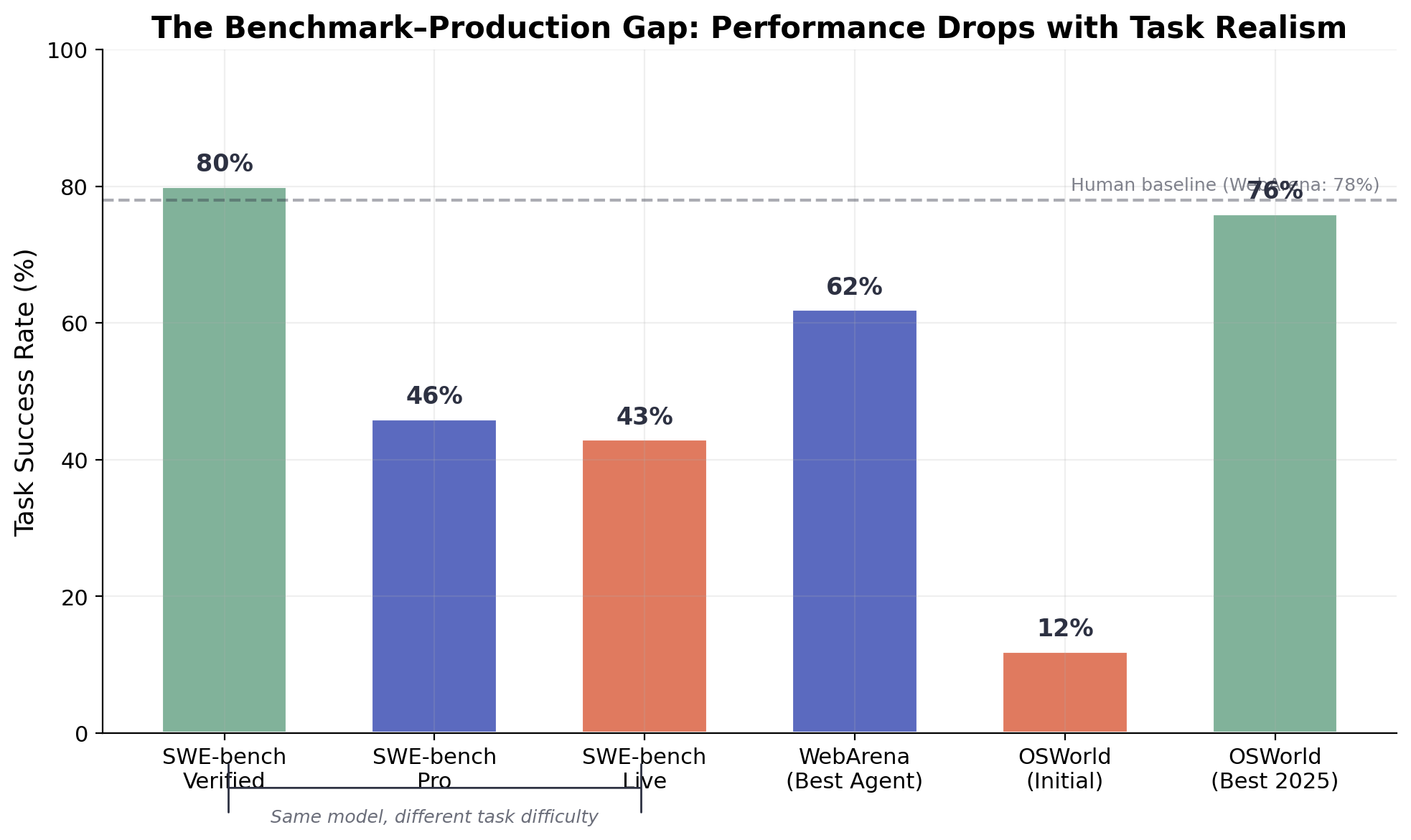
図2. ベンチマークと本番環境のギャップ。同じモデル構成が、SWE-benchのバリアント(Verified → Pro → Live)、WebArena、OSWorldにわたって劇的に異なる成功率を示している。管理されたベンチマークは、実世界の能力を大幅に過大評価している。
ベンチマークデータはこのパターンをさまざまなドメインにわたって裏付けています。SWE-bench Verifiedでは、トップエージェントは80%以上をスコアします。しかし、SWE-bench Proでは同じシステムが約46%に低下し [10]、SWE-bench Liveでは19〜43%を示します [9]。WebArenaでは、最良の単一エージェントシステムが人間のベースライン78%に対して61.7%に到達します [11]。OSWorldのデスクトップタスクでは、初期のベストモデル成功率12.24%が一部の構成で76%にまで上昇しましたが、Epoch AIは、それらのタスクの約45%が真のGUI推論ではなく単純なターミナルコマンドで完了できることを指摘しています [12]。
全体的なパターンは明確です。ベンチマーク性能と本番環境の信頼性は、異なるものを測定しています。 前者は管理された条件下でのピーク能力を捉え、後者は実世界のバリエーションのロングテールにわたる一貫した性能を要求します。
トークンエコノミクスは複合的なコスト危機を生み出す
信頼性の問題には経済的な双子があります。各ステップが増大する会話履歴全体を再処理するナイーブな反復型エージェントループでは、トークンコストは線形ではなく二次的に蓄積されます。SWE-benchリーダーボードの分析では、高性能エージェントがシングルショットアプローチと比較してタスクあたり10〜50倍のトークンを消費することが示されています [13]。
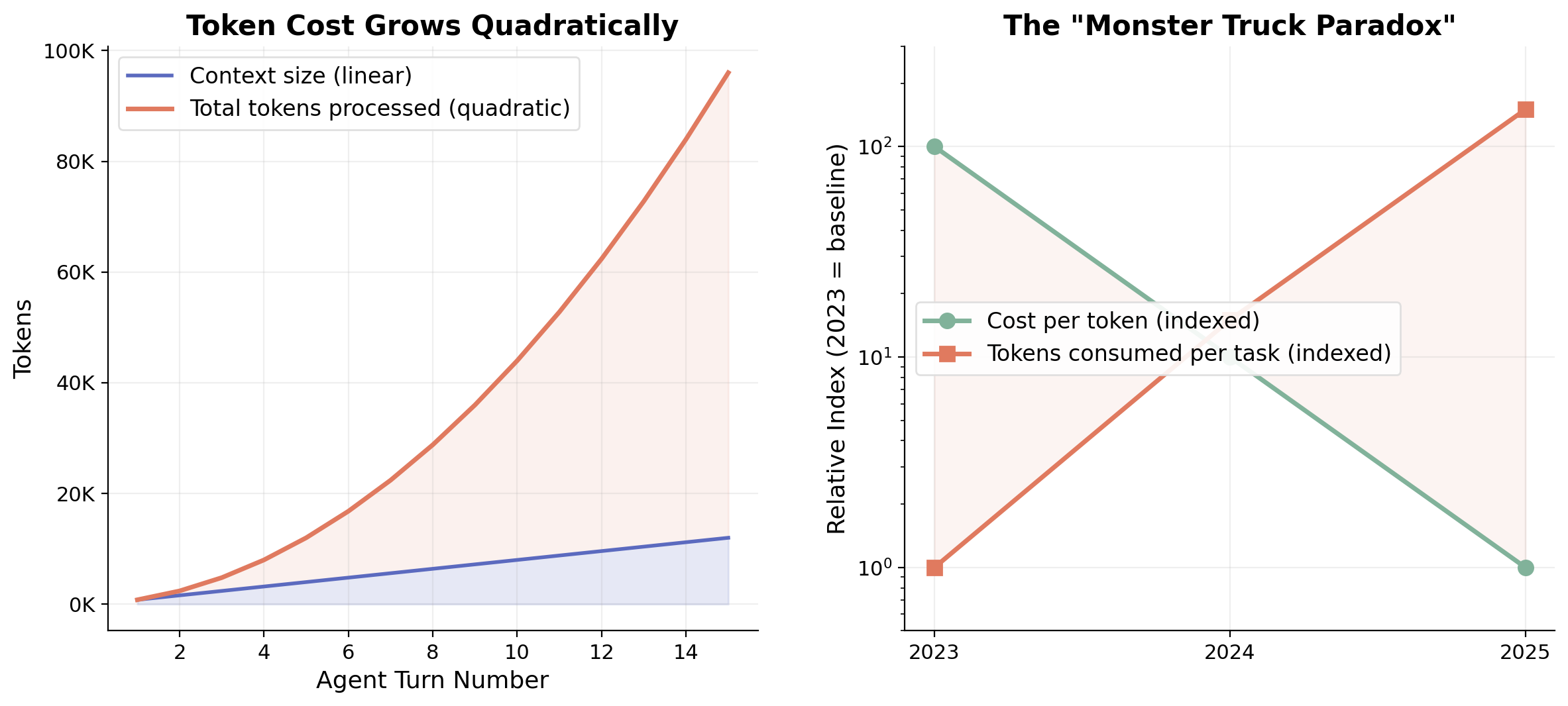
図3. 左:各エージェントターンがすべての先行コンテキストを再処理するため、トークンコストは二次的に増大する。右:「Monster Truck Paradox」――トークン単価は年間約10倍低下するが、エージェントワークロードに駆動されてタスクあたりの消費量がそれ以上の速度で増加する。
消費の規模は注目に値します。チャットベースからエージェントベースへのインタラクションへの進化は、セッションあたりのトークン消費量を桁違いに増加させており、一部のパワーユーザーは月間で数十億トークンを消費していると報告しています [14]。トークン単価は劇的に低下しています――2023年以降、年間約10倍――しかし、タスクあたりの消費量はコストの低下よりも速く増大しています。
本番環境のデプロイメントにとって、経済性は厳しいものです。中規模のエージェントデプロイメントでは、500万〜1,000万トークンで月額1,000〜5,000ドルのコストがかかります。Claude Codeの実行は平均して1日あたり開発者1人あたり6ドルです [15]。エンタープライズのプロトタイプでは、ステージングから本番環境への移行時に月額5,000ドルから月額50,000ドルへのコスト急増がしばしば見られます [3]。コンテキスト圧縮――プロンプトキャッシング、階層的要約、選択的アテンションによる5〜20倍の削減――は最も投資対効果の高い最適化を提供し、70〜94%のコスト削減が報告されています。しかし、これらの緩和策は根本的なアーキテクチャの課題ではなく、症状に対処するものです。
実現可能な場合、ステートレス設計こそが最もレバレッジの高い対策となることが多いです。可能な限り、マルチターンの会話を完全に避けることです。エージェントを専門化された単一目的のツールとして扱います。明確な指示を与え、結果を受け取り、セッションを終了する。これにより、コンテキストの蓄積を根本から排除できます――増大するプロンプトも、暴走するトークンコストもありません。状態を保持する必要がある場合は、外部化します。会話コンテキストで持ち運ぶのではなく、中間結果をデータベースやファイルシステムに書き込みます。呼び出し間で何も記憶しないエージェントこそが、スケールするエージェントです。
信頼性を実際に向上させるアーキテクチャパターン
最近の最も心強い成果は、CognizantのAI Labから得られたものです。Meyerson et al.(「Solving a Million-Step LLM Task with Zero Errors」, 2025)[16]は、MAKERフレームワークが100万回以上の逐次LLMステップをエラーゼロで完了することを実証しました。MAKERは3つの原則によりこれを達成しています。ステートレスな「マイクロエージェント」が処理するアトミックなサブタスクへの徹底的な分解、ギャンブラーの破産問題の一般化に基づくマルチエージェント投票、そして構文エラーがロジックエラーを示すシグナルとなり修復ではなく破棄される「レッドフラグ」方式です。最も驚くべきことに、より小さな非推論モデルがコストあたり最高の信頼性を提供しました。
ただし重要な留意点があります。MAKERの100万ステップという結果は、高度に構造化され、完全に検証可能で、極めて分解しやすいタスク(決定論的検証を伴う高度に構造化された組み合わせタスク(ハノイの塔))で達成されたものです。このため、分解とローカル検証の力を示す説得力のある原理実証ではありますが、曖昧な目標、非構造化データ、検証不能な中間ステップを含むことの多い一般的なエンタープライズエージェントワークフローが同様の信頼性を達成できるという直接的な証拠にはなりません。アーキテクチャ原則(分解、投票、ステートレスなマイクロエージェント)は幅広く適用可能ですが、エラーゼロという特定の結果はその領域を超えて外挿すべきではありません。
この発見は、主要なAIラボ間で形成されつつあるコンセンサスと一致しています。Anthropicの影響力のあるガイド「Building Effective Agents」(Schluntz and Zhang, 2024)[17]は明確な階層を確立しました。シンプルなパターンから始め、必要性が実証された場合にのみ複雑さを追加し、エージェントシステムはタスクパフォーマンスのためにレイテンシーとコストをトレードオフすることを認識する、というものです。その後のツール設計に関する研究では、同社がモデルの変更ではなくツールの説明の慎重な改善を一因としてSWE-benchの最先端の結果を達成したことが実証されました。これは、インフラストラクチャ設計がモデルの能力よりも重要になりうることの具体的な実証です。
OpenAIの「Practical Guide to Building Agents」(2025年)も独立して同様の結論に達し、マルチエージェントの複雑さを導入する前にまず単一エージェントの能力を最大化することを推奨しています [18]。競合するラボが同じ原則――シンプルさ、限定的なスコープ、慎重なツール設計――について収束したガイダンスを提供していること自体が、重要な証拠です。
これらの発見は、実践者が一貫して再発見するパターンを指し示しています。本番環境のエージェントシステムにおいて、AIモデルは全体的な性能の支配的要因ではないことが多いのです。私たち自身の経験と現場のチームとの対話に基づけば、ツール設計、オーケストレーション、エラーハンドリングはモデル選択よりも重要であることが多い――ただし正確な比率はアプリケーションによって異なります。システムは最小限のトークンでモデルに成功をどう伝えるのか?ツール呼び出しが失敗したとき、エラーと次のステップをどう簡潔に表現するのか?これらが、エージェントが本番環境で機能するかどうかを決定する問いであり、モデルの知能だけでは解決できません。
DSPy(Khattab et al., NeurIPS 2023)[19]が開拓したプログラマティックアプローチは、別のアーキテクチャ上の応答を提供します。手作業でプロンプトを作成するのではなく、DSPyはLLMパイプラインを最適化可能なプログラムとして扱います。特定のタスク構成において、このフレームワークはGPT-3.5でパイプラインの品質を33%から82%に向上させました――ただしこの数値は特定のベンチマークスライスからのものであり、結果はタスクによって異なります。しかしより広い論点は変わりません。DSPyは、基礎となるモデルの変更ではなく、パイプライン構造の体系的な最適化によって大幅な改善を達成しています。
重要な洞察: 基盤的なアーキテクチャ――グラウンディングのためのReAct [20]、失敗からの学習のためのReflexion [21]、階層的構成のためのVoyager [22]――は、それぞれ複合システムの異なる障害モードに対処しています。勝利パターンはどれか一つを選ぶことではなく、タスクの信頼性要件に適した組み合わせを構成することです。
エンタープライズの支出は低自律性のAI製品を選好している
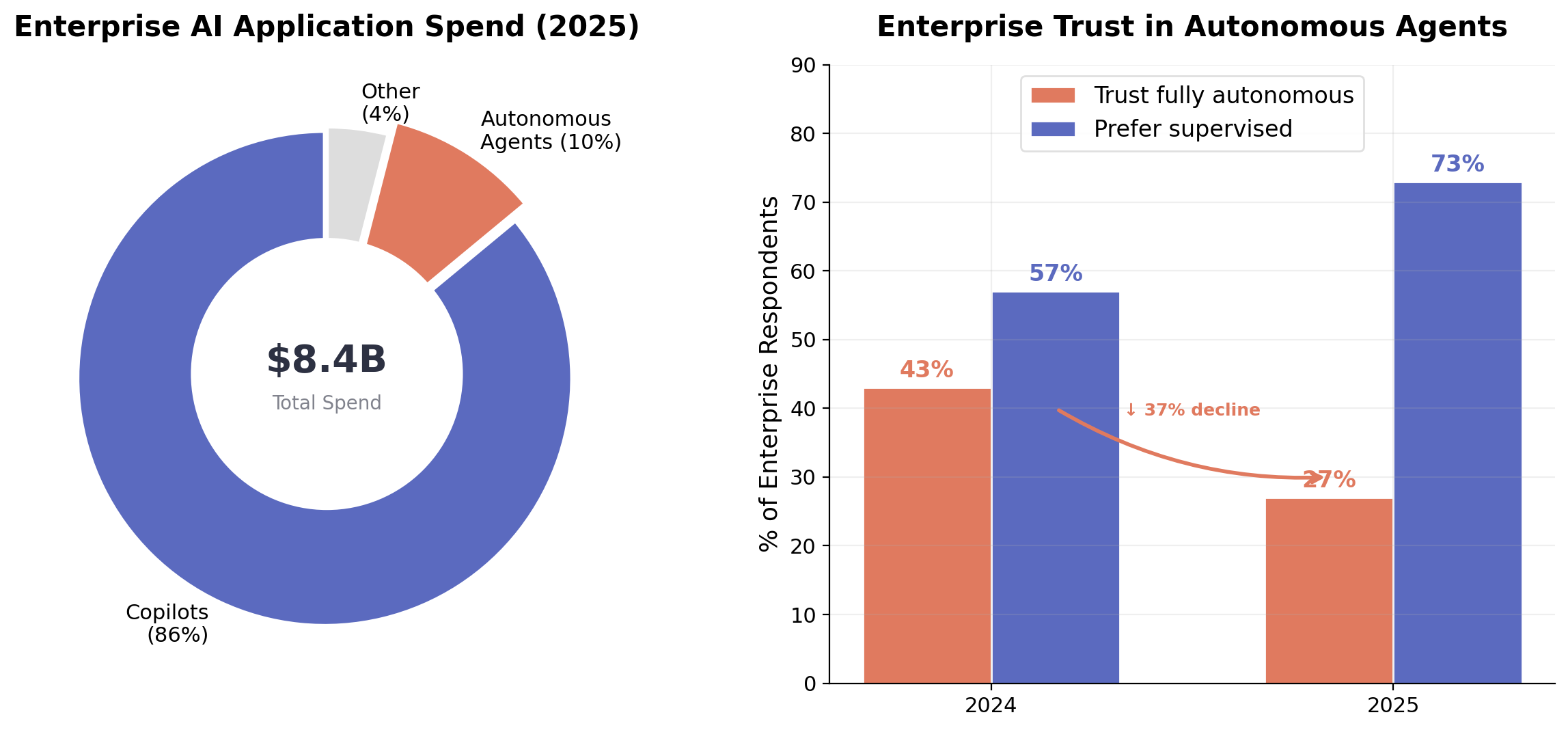
図4. 左:2025年のエンタープライズAIアプリケーション支出は、自律型エージェント(10%)ではなくコパイロット(86%)に圧倒的に集中している。出典:Menlo Ventures 2025 Enterprise Survey [23]。右:完全自律型エージェントへの信頼は前年比で43%から27%に低下。出典:Capgemini 2025 Agentic AI Report [1]。
適切な自律性のテーゼを裏付ける最も説得力のある証拠は、市場データから得られます。Menlo Venturesの2025年エンタープライズ調査では、コパイロットが水平型AIアプリケーション支出の86%(72億ドル)を占め、自律型エージェントはわずか10%であること、そしてエンタープライズAIデプロイメントのうち「真のエージェント」に該当するものは16%にすぎないことが判明しました [23]。別途、Capgeminiの2025年のエージェント型AIに関する調査では、完全自律型エージェントへの信頼は実際に低下しており、前年比で43%から27%になったことが報告されています [1]。
実世界のデプロイメントデータも同じストーリーを語ります。Answer.AIは20の多様なタスクでDevinをテストし、成功3件、失敗14件、判定不能3件という結果を得ました [24]。Cognition Labs自身のパフォーマンスレビューでも、Devinは明確で事前に定義された要件があれば優れているが、曖昧なプロジェクトをエンドツーエンドで独立して遂行することはできないと認めています [25]。
Feng, Morris, Mitchell(「Levels of Autonomy for AI Agents」, 2025)[26]はこれを5段階の自律性フレームワークとして形式化しました。彼らの主要な議論は次の通りです。自律性は能力とは分離可能な、意図的な設計上の決定です。 高い能力を持つエージェントは、低い自律性レベルで運用できるし、多くの場合そうすべきです。Zaharia et al.(BAIR, 2024)[27]が表明したcompound AIシステムのパラダイムは理論的な基盤を提供しています。最先端の結果は、モノリシックな自律型エージェントではなく、複数のコンポーネントが相互作用するエンジニアリングされたシステムからますます生まれています。
では、なぜ現在のデプロイメントにおいて、低い自律性が高い信頼性と相関する傾向にあるのでしょうか?それはスコープが狭いこと自体が本質的に信頼性が高いからではなく、低自律性の設計の方が、人間によるレビュー、ステップレベルの検証、ロールバック機構――すなわち、前述のとおりステップごとの信頼性を掛け算するのと同等の効果を持つ、まさにその回復アーキテクチャ――を挿入しやすいからです。市場のシグナルは、自律型エージェントが行き止まりであるということではなく、現在の技術水準では、高い自律性を支えるために必要な信頼性インフラストラクチャが、ほとんどのエンタープライズユースケースではまだ整っていないということなのです。
現在地:エンジニアリングの規律はモデルのスケーリングと少なくとも同等に重要である
証拠は、この分野がなかなか内面化できずにいる結論に収束しています。本番環境の信頼性にとって、エンジニアリングの規律はさらなるモデル能力の向上と少なくとも同等に――そして多くの現行デプロイメントでは、それ以上に――重要です。 Princetonの発見(18か月間の能力向上が信頼性を変えなかったこと)、Cognizantの実証(高度に構造化された領域において、適切なアーキテクチャを持つ小型モデルがコストあたりの信頼性で大型モデルに匹敵またはそれを上回ること)、Anthropicの達成(ツールの説明の改善を一因としたSWE-benchの最先端)――これらはすべて同じ方向を指しています。
これが実践においてどのようなものかは、対比によって最もよく示されます。すべての受信チケットをエンドツーエンドで解決するように設計された自律型カスタマーサポートエージェントを考えてみましょう。苦情を読み、社内システムを照会し、返金を処理し、人間の介入なく最終的な応答を作成するものです。これはステージ上でデモ映えするビジョンです。本番環境では、このようなシステムはエッジケースを誤分類し、不正確な返金を行い、フラストレーションを抱えた顧客をさらにエスカレートさせる応答を生成することになります。はるかに価値のあるシステムは、トリアージとドラフティングのアシスタントです。緊急度別にチケットを分類し、関連する注文履歴を取得し、人間のレビュー用に応答のドラフトを作成し、エスカレーションが必要なケースにフラグを立てるものです。後者は限定的で、各ステップで検証可能であり、結果に影響する判断は人間がコントロールしつつ、アナリストのスループットを大幅に向上させることができます。
あるいは、生のファイリングから完全な投資メモを作成する自律的なデューデリジェンスエージェントを考えてみましょう――変革的に聞こえるエンドツーエンドのワークフローです。実際には、収益数値の一つのハルシネーションやリスクファクターの見落としが、メモ全体の信頼性を損ないます。よりデプロイしやすいバージョンは、SECファイリングを24時間体制で監視し、主要な財務指標を抽出し、過去のベースラインに対する異常を検出し、アナリストが行動すべきタイムセンシティブなインサイトを浮上させるリサーチアシスタントです。アナリストの判断を代替するのではなく、アナリストが眠っている間にもシグナルが見逃されないことを保証するのです。
エージェントシステムを構築するチームへの実践的な示唆は明確です。第一に、複合信頼性をファーストクラスの設計制約として扱うこと。pⁿの減衰は、20ステップのパイプラインが80%のエンドツーエンド成功率を達成するためだけでも99%以上のステップごとの信頼性を必要とすることを意味しますが、これは現在のモデルがアーキテクチャのサポートなしには滅多にクリアできない水準です。第二に、予防よりも回復メカニズムに投資すること。Pedderの分析は、エラーを検出し回復する能力がシステム信頼性に与える効果は、各ステップを2.7倍信頼性の高いものにすることと同等であることを示しています――回復アーキテクチャの優先を強く裏付ける論拠です。第三に、エージェントの自律性を信頼性要件に合わせてスコーピングすること。Ordによる一定ハザードレートの仮定に基づくMETRデータの外挿では、99%の信頼性を達成するには、タスク長を50%信頼性ホライズンの約1/70に制限する必要があります――信頼性要件が上がるにつれて使用可能なタスクスコープがいかに急激に収縮するかを示す、桁レベルの目安です。
経済的なケースはアーキテクチャのケースを裏付けます。ナイーブな反復ループにおける二次的なトークンスケーリング、高いコスト変動性、Monster Truck Paradoxは、アーキテクチャ上の緩和策なしに制約のないエージェント自律性を追求することが、信頼性に欠けるだけでなく、経済的にも持続不可能であることを意味します。AIエージェントで成功している企業は、汎用的な自律ワーカーとしてではなく、精密に設計されたシステム内に配置された精密機器としてエージェントを扱っている企業です。
AIエージェントの分野は急速に進歩しています――METRの50%タイムホライズンは7か月ごとに倍増し、ベンチマークスコアは上昇を続けています。しかし、能力と信頼性のギャップは持続しており、それを埋めるにはこれらのシステムについての考え方を変える必要があります。複合信頼性の問題は、次のモデル世代で克服される一時的な限界ではありません。それは、分解、検証、回復、そして適切な自律性という構造的な解決策を要求する逐次システムの構造的特性です。この洞察を内面化した組織――限定的で信頼性が高く、十分に計装されたエージェントを構築し、信頼性インフラストラクチャがそれを支えられる場合にのみ自律性を拡大していく組織――が、エージェント時代から真の価値を獲得することになるでしょう。
参考文献
Capgemini, "Trust and Human-AI Collaboration Set to Define the Next Era of Agentic AI." 2025. capgemini.com
Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." Press release, June 2025. gartner.com
C. Pedder, "When agents fail: compounding errors in organisational systems." Substack, 2025
M. Cemri, X. Pan, et al., "Why Do Multi-Agent LLM Systems Fail?" NeurIPS 2025. arXiv:2503.13657
S. Rabanser, S. Kapoor, A. Narayanan, "Towards a Science of AI Agent Reliability." 2026. arXiv:2602.16666
T. Kwa et al., "Measuring AI Ability to Complete Long Tasks." METR, 2025. arXiv:2503.14499
T. Ord, "Is there a Half-Life for the Success Rates of AI Agents?" tobyord.com, 2025
J. Yang et al., "SWE-bench Goes Live!" arXiv:2505.23419
SWE-bench Pro Leaderboard. swebench.com
S. Zhou et al., "WebArena: A Realistic Web Environment for Building Autonomous Agents." arXiv:2307.13854
Epoch AI, "What does OSWorld tell us about AI's ability to use computers?" epoch.ai, 2025; T. Xie et al., "OSWorld: Benchmarking Multimodal Agents." arXiv:2404.07972
"How Do Coding Agents Spend Your Money? Analyzing and Predicting Token Consumptions in Agentic Coding Tasks." ICLR 2026 submission. OpenReview
IKANGAI, "The LLM Cost Paradox: How 'Cheaper' AI Models Are Breaking Budgets." ikangai.com
Anthropic, "Manage costs effectively — Claude Code Docs." code.claude.com
E. Meyerson et al., "Solving a Million-Step LLM Task with Zero Errors." Cognizant AI Lab, 2025. arXiv:2511.09030
E. Schluntz, B. Zhang, "Building effective agents." Anthropic, Dec 2024. anthropic.com
OpenAI, "A Practical Guide to Building Agents." 2025. openai.com
O. Khattab et al., "DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines." NeurIPS 2023. arXiv:2310.03714
S. Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. arXiv:2210.03629
N. Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. arXiv:2303.11366
G. Wang et al., "Voyager: An Open-Ended Embodied Agent with Large Language Models." TMLR 2024. voyager.minedojo.org
Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
J. Howard, Answer.AI, "Testing Devin: 20 diverse tasks." 2024.
Cognition Labs, "Devin's 2025 Performance Review." cognition.ai
G. Feng, M. Morris, K. Mitchell, "Levels of Autonomy for AI Agents." 2025. arXiv:2506.12469
M. Zaharia et al., "The Shift from Models to Compound AI Systems." BAIR Blog, Feb 2024. bair.berkeley.edu