
学習データ不足という課題
自動運転、製造検査、その他のセーフティクリティカルな応用分野における深層学習モデルは、共通の課題を抱えています。最も重要なシナリオにおいて、最も性能が低下するという問題です。
カメラ画面全体を覆うほどの至近距離の車両。路上の想定外の障害物。生産ラインにおける希少な欠陥種別。これらは誤った予測が最も深刻な結果をもたらす状況であり、同時に学習データにおいて最も過小に表現されているものです。
これは主にデータのボトルネックであり、アルゴリズムの問題ではありません。
現実世界はロングテール分布である。 走行データセットにおいて、乗用車は数千回出現しますが、スクールバス、消防車、建設車両はごくわずかしか出現しません。多くの製造現場では、欠陥率は1パーセントを大きく下回ります。
コーナーケースは人為的に作れない。 学習データを収集するために交通事故を起こすことはできません。あらゆる欠陥タイプを意図的に製造することもできません。最も重要なシナリオは、オンデマンドで収集できないものです。
収集後のデータ処理には限界がある。 リサンプリング、クラス重み付け、従来のデータ拡張は、既存データの制約の中で動作するものであり、一度も撮影されなかった視覚的多様性を生み出すことは通常できません。
この学習データ不足は、セーフティクリティカルな産業全体における視覚認識の導入において、最も根強いボトルネックの一つです。Yodo Labs が合成データプラットフォームを開発した理由はここにあります。
合成データプラットフォーム
合成データプラットフォームは、Yodo Labs が自社開発した独自の画像生成モデルを基盤としています。創業者 Xiuxi Pan 博士のコンピュータビジョン研究に基づき構築されたこのモデルは、汎用的な生成モデルを学習データ生成に転用したものでも、既存の生成AIサービスのラッパーでもありません。認識モデルの性能を向上させる学習データの生成,,この一つの目的のために、ゼロから設計された専用モデルです。
主流の生成AI業界は、美しく面白い画像の生成を競っています,,人間の視覚的嗜好に最適化しているのです。私たちは意図的に逆の方向を選びました。私たちのモデルは機能的な正確性に最適化しています。合成データがモデル性能を実際に向上させるかどうかを決定する2つの特性,,既存の生成モデルではしばしば達成できない特性です。
位置の忠実性 , 生成されたオブジェクトは、アノテーションで指定された正確な位置に出現します。入力レイアウトがそのまま出力のアノテーションとなり、手動ラベリングは不要です。これは合成データを学習データとして使用可能にする本質的な特性であり、汎用的な生成モデルでは往々にして後回しにされるものです。
スタイルの一貫性 , 生成画像がターゲットとなる運用環境の視覚的特性と一致します。プラットフォームは極めて少量の参照画像で新しいカメラシステムや視覚ドメインに適応可能で、アノテーションは不要です。これにより合成データと実データ間のドメインギャップを縮小し、合成画像がモデル学習に貢献できるようにします。
生成できるもの
ロングテールのリバランス
既存シーン内の出現頻度の高い物体クラスを希少なクラスに置き換えます。シーンの構成は保持され、対象のオブジェクトのみが変更されます。新たなデータ収集なしに、クラス分布を直接リバランスできます。


インスタンス密度の向上
既存シーン内の合理的な位置に新しいオブジェクトインスタンスを追加し、1画像あたりのラベル付きオブジェクト数を増やします。


特定のコーナーケースを狙い撃ち
必要なシナリオを正確に定義します,,至近距離のトラック、特殊な空間配置、稀な構成,,そして、必要な数だけ多様な例を生成できます。


未知オブジェクトの生成
学習データに存在しなかったオブジェクト,,路上の落下物、想定外の障害物、動物など,,を新しい物体カテゴリとして、指定位置に正しいアノテーション付きで生成できます。実データの学習サンプルがゼロのクラスでも、新しいカテゴリを学習対象に含められます。


検証:自動運転パイロット
大手自動車メーカーのR&D部門と共に、プラットフォームの検証を行いました。同社の自動運転チームは、広角レンズと魚眼レンズを含むマルチカメラセンサースイートを運用しています。本パイロットでは、クライアントがより大規模な本番データセットから24,000枚のアノテーション付き画像をサブセットとして学習用に提供し、別途ホールドアウトのテストセットも用意されました。この学習サブセット内でもロングテールの不均衡は顕著で、特定の重要なコーナーケースはわずか233例しか含まれていませんでした。
プラットフォームをクライアントの各カメラ構成に適応させ、合成学習データを生成し、物体検出パイプラインへの影響を測定しました。
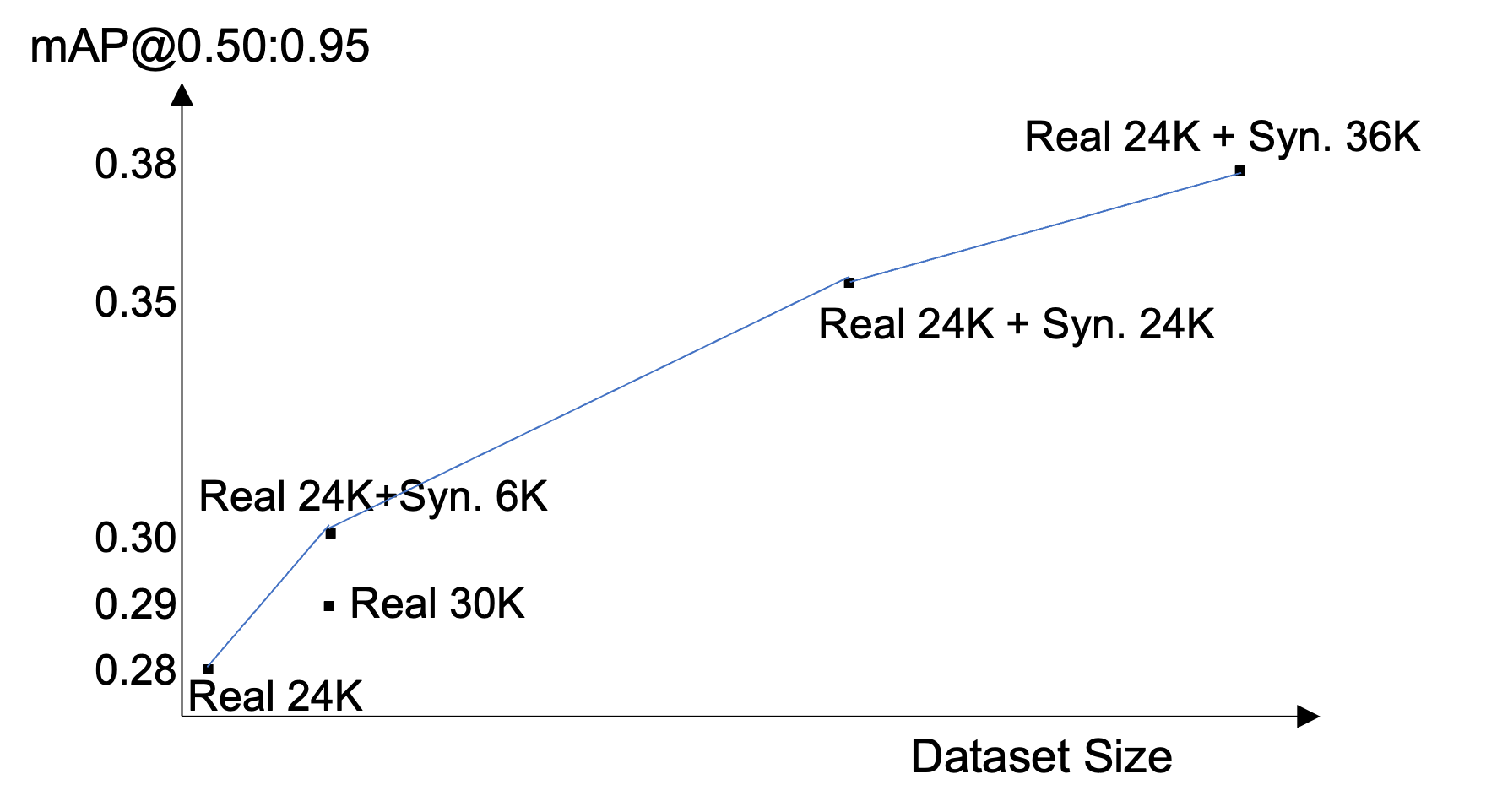
mAP が 0.279 から 0.378 に向上。 24,000枚の学習セットに約36,000枚の合成画像を追加することで、mAP は絶対値で +0.099(相対値で +35.5%)改善しました。検証した最大の合成データ追加量において性能曲線は頭打ちになっていませんでしたが、合成データと実データの比率がさらに増加すると限界的な効果は逓減する可能性があります。
本データ比率において合成データが実データを上回る。 この特定の比較において、実データ24,000枚+合成データ6,000枚は、実データ30,000枚よりも高い mAP を達成しました。追加生成戦略により生成された合成画像は1画像あたりのアノテーション付きインスタンス数が多く、より密な学習シグナルを提供します。
233枚の画像で重要なコーナーケースが改善。 至近距離で切れた大型トラック,,学習セットにわずか233例、テストセットに503例,,に対して、233枚の合成画像を追加生成することで、このシナリオにおける検出が改善されました。


応用分野
合成データプラットフォームは以下の分野で活用されています:
- 自動運転 , コーナーケースのカバレッジ、ロングテールのリバランス、未知障害物の検出、マルチカメラ適応
- 製造品質検査 , 希少欠陥の増強、欠陥データが存在しない新製品ラインに対するコールドスタート学習
最も重要なシナリオの事例が不足するという根本的な課題は、セーフティクリティカルな条件下で視覚認識が運用されるあらゆるドメインに共通しています。
お問い合わせ
コーナーケース、希少クラス、新しい展開シナリオにおける学習データ不足の課題をお持ちでしたら、ぜひご相談ください。