
A VLM-centered approach to the long-tail defect problem, deployed through vLLM
Have you ever tried to teach a computer to spot something it has never seen before? In infrastructure inspection, this is not a hypothetical—it is the central problem. The rarest defects are often the most dangerous: a woodpecker hole in a utility pole, a hairline crack on a wind turbine blade, an unusual pattern of corrosion on a bridge fitting. These corner cases appear too infrequently to populate a training set, yet missing even one can have serious safety consequences.
Traditional supervised detectors—YOLO and its variants—excel when defect classes are well-defined and training data is abundant. But corner-case inspection breaks these assumptions. Targets may be open-ended ("anything abnormal"), new failure modes emerge over time, and the most critical anomalies occupy the extreme tail of the data distribution. When we partnered with an infrastructure inspection team to address this problem, we found that Vision-Language Models (VLMs), served efficiently through vLLM, offered a fundamentally different and more practical path forward.
This post describes the technical foundations behind our approach: why VLMs offer practical advantages over open-set detectors for ambiguous, explanation-heavy corner-case workflows, how vLLM makes production deployment feasible, and the three adaptation strategies—in-context learning, few-shot fine-tuning, and retrieval-augmented generation—that bridge the gap between a general-purpose model and a domain-ready inspection system.
Why conventional detectors fail at corner cases
The fundamental challenge in infrastructure inspection is the mismatch between the closed-world assumptions of supervised learning and the open-world nature of real infrastructure failures.
Defect distributions are inherently long-tailed. A few common types (surface cracks, minor corrosion) dominate datasets, while critical rare anomalies occupy the tail with vanishingly few examples. Among inspected wind turbines, only approximately 8.5% of 35,000 units showed hairline cracks—the most critical yet hardest-to-detect defect type [1]. Anomaly rates in real-world mass inspection typically fall under 1% of all samples [2]. Human manual inspection error rates reach 10–20%, with the probability of overlooking specific defect types as high as 25% [3].
Each infrastructure domain presents unique corner cases. Power line inspection must handle woodpecker holes (sub-centimeter), corona discharge (UV-only), and subtle conductor fraying on fittings that are extremely small relative to the overall transmission line structure [4]. Bridge inspection confronts internal micro-cracks invisible on the surface, multi-defect overlap, and defects occluded by dirt and vegetation. Wind turbine blade inspection faces hairline cracks barely visible to the human eye, lightning-induced erosion, and subsurface delamination—where a single blade replacement can cost over $300,000 according to industry estimates.
A YOLO-style detector trained on ten defect classes will never flag an eleventh. This is not a limitation that can be solved with more data for the known classes; it is a structural property of the closed-set paradigm.
Two technical directions: open-set detection vs. VLMs
We explored two approaches commonly proposed for open-ended detection with minimal data.
Open-set / one-shot detection
Models like T-Rex2 [5], Grounding DINO [6], and DINO-X [7] aim to localize objects using text prompts, visual prompts (example bounding boxes or points), or both. T-Rex2 introduced a key insight relevant to infrastructure inspection: for common objects, text prompts outperform visual prompts, but for rare objects (ranked 800–1,200 by frequency), visual prompts significantly outperform text [5]. This complementarity is directly relevant to industrial settings, where unusual defect patterns are difficult to describe verbally but easy to demonstrate with an example image.
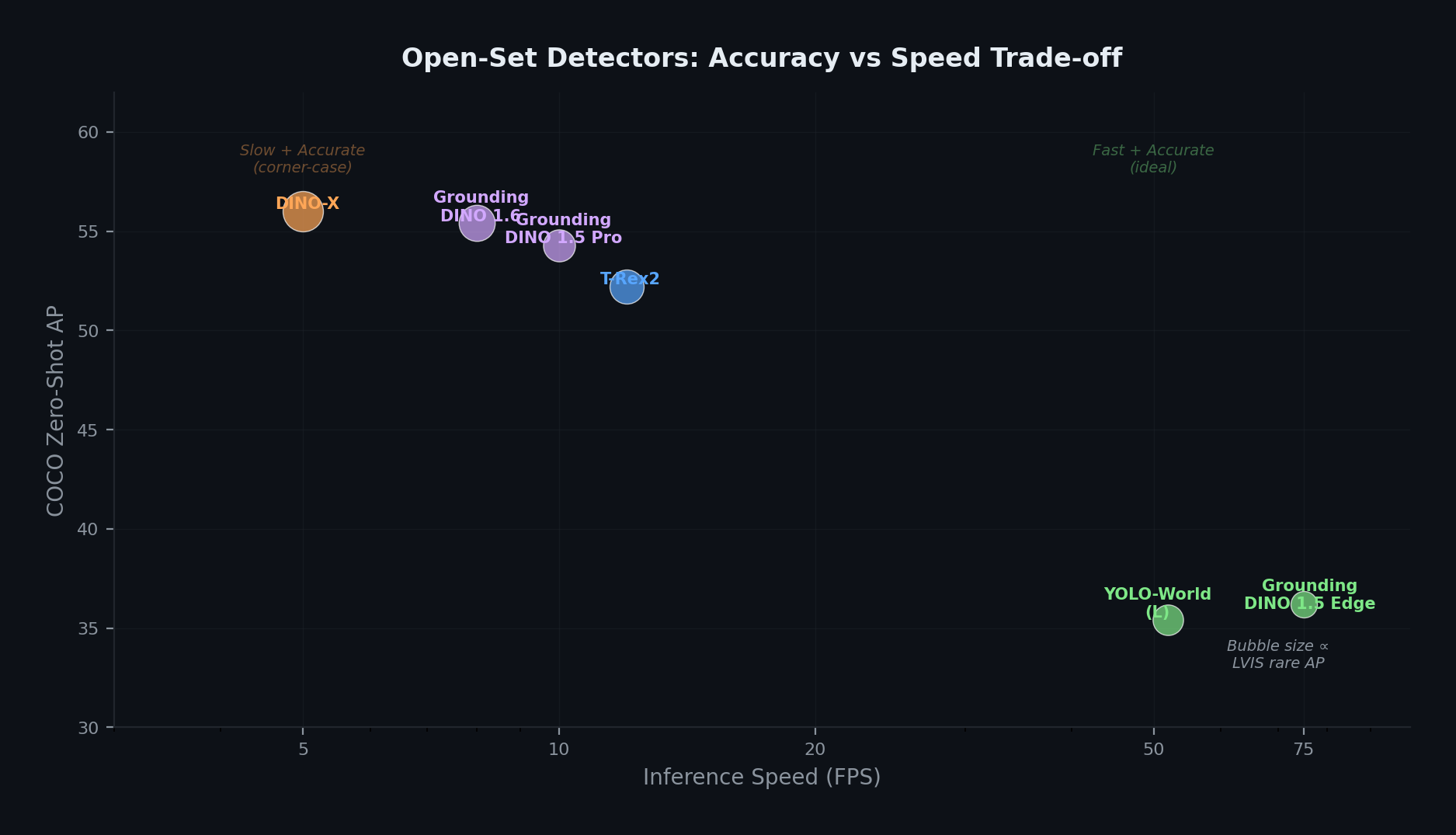 Open-set detection models present a clear accuracy–speed trade-off. DINO-X achieves the highest zero-shot AP on both COCO and LVIS rare classes, while YOLO-World offers real-time performance suitable for first-pass screening. Bubble size is proportional to LVIS rare-class AP—the metric most relevant to corner-case detection.
Open-set detection models present a clear accuracy–speed trade-off. DINO-X achieves the highest zero-shot AP on both COCO and LVIS rare classes, while YOLO-World offers real-time performance suitable for first-pass screening. Bubble size is proportional to LVIS rare-class AP—the metric most relevant to corner-case detection.
DINO-X currently represents the state-of-the-art, achieving 56.0 AP on COCO zero-shot and 63.3 AP on LVIS rare classes—the latter an improvement of 5.8 AP over the previous best [7]. YOLO-World takes a different approach, building open-vocabulary capability on top of YOLOv8, achieving 35.4 AP at 52 FPS—orders of magnitude faster than the Grounding DINO family [8].
However, these models face a practical limitation for our use case. Our client's corner-case targets were often too general or ambiguous for prompt-grounded detectors to reliably localize. Concepts like "anything structurally abnormal" or "unexpected deformation" do not map cleanly to text prompts, and visual prompts require carefully chosen reference boxes that may not generalize across environmental conditions.
VLM-based inspection
Vision-language models—Qwen2-VL [9], InternVL [10], LLaVA-OneVision [11]—take a fundamentally different approach. Rather than producing bounding boxes from prompts, they reason over images through natural language. You can ask a VLM "Is there anything unusual about this utility pole?" and receive a structured response describing the anomaly, its likely cause, and its approximate location.
The evolution of VLMs for industrial anomaly detection has been rapid. AnomalyGPT (AAAI 2024) demonstrated that with a single normal reference image, a VLM could achieve 86.1% accuracy and 94.1% image-level AUC on MVTec-AD—the standard industrial anomaly benchmark—while supporting multi-turn diagnostic dialogues [12]. LogicAD (AAAI 2025) tackled logical anomalies (missing components, wrong arrangements), achieving 86.0% AUROC on MVTec LOCO AD, an 18.1% improvement over prior methods [13]. InfraGPT (2025) demonstrated an end-to-end VLM-based framework for urban infrastructure defect detection and management [14].
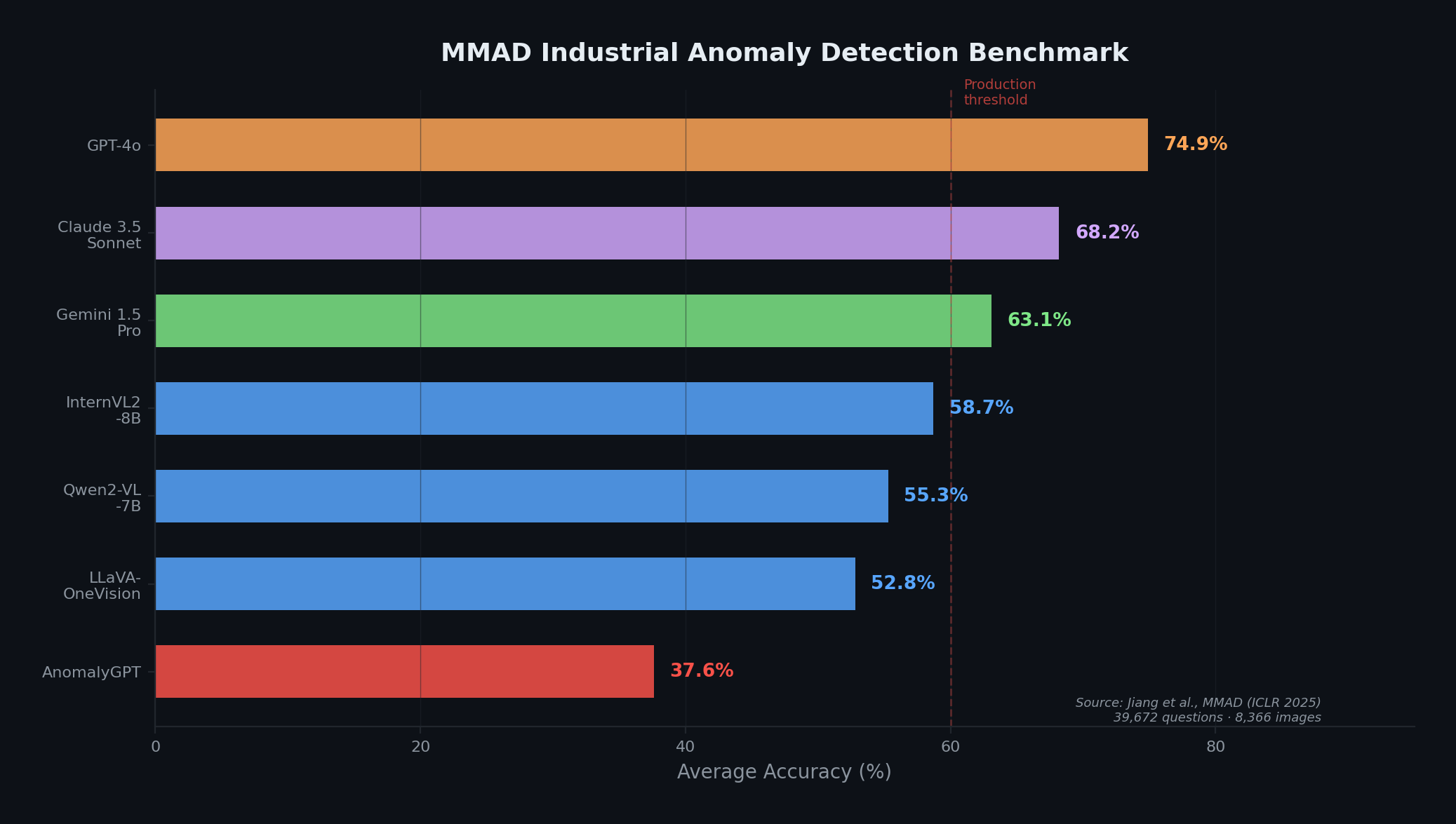 The MMAD benchmark (ICLR 2025)—the most comprehensive VLM evaluation for industrial anomaly detection—reveals that even the best models have significant room for improvement. The gap between frontier API models and open-weight models motivates domain-specific adaptation. Data from Jiang et al. [15].
The MMAD benchmark (ICLR 2025)—the most comprehensive VLM evaluation for industrial anomaly detection—reveals that even the best models have significant room for improvement. The gap between frontier API models and open-weight models motivates domain-specific adaptation. Data from Jiang et al. [15].
Yet the MMAD benchmark (ICLR 2025)—the most rigorous evaluation to date, with 39,672 questions across 8,366 industrial images—revealed that even GPT-4o reaches only 74.9% average accuracy across MMAD's question-answering tasks [15]. This is sobering, but also instructive: it tells us that raw VLM capability is insufficient, and that domain-specific adaptation is essential for production use. More importantly, VLMs natively provide natural-language explanations of why something is anomalous—a capability that open-set detectors do not offer by themselves, and one that is critical for human-in-the-loop inspection workflows.
The VLM-centered solution stack
Based on our research phase, we designed a VLM-centered inspection stack with three adaptation modes. Each can be deployed independently, but they are also designed to be combined: for example, a LoRA-fine-tuned model can be further augmented with RAG at inference time. The three modes map to different stages of deployment maturity and can be adopted progressively.
 The three adaptation modes map to different stages of deployment maturity. In-context learning enables day-one operation; LoRA fine-tuning provides production stability; Visual RAG adds domain knowledge without retraining.
The three adaptation modes map to different stages of deployment maturity. In-context learning enables day-one operation; LoRA fine-tuning provides production stability; Visual RAG adds domain knowledge without retraining.
In-context learning: immediate deployment
When a new corner case is identified—say, a previously unseen type of insulator damage—in-context learning allows the system to incorporate it immediately. Reference images (normal and defective) are placed directly in the VLM prompt alongside carefully designed instruction templates. Ueno et al. (2025) demonstrated that fine-tuned ViP-LLaVA using single-shot ICL achieved MCC 0.804 and F1-score 0.950 on MVTec-AD, competitive with specialized models [16]. Their finding that Euclidean-distance-based example selection outperforms cosine-similarity-based RICES has practical implications for retrieval system design.
The trade-off is clear: ICL requires zero training compute, but each high-resolution inspection image consumes 2,000–4,000 visual tokens, rapidly filling context windows. Performance typically plateaus around 4–8 reference images.
Few-shot fine-tuning: production stability
For recurring inspection operations that require stable, repeatable behavior, LoRA fine-tuning (Low-Rank Adaptation) introduces small decomposition matrices into transformer attention layers, training only 0.1–0.5% of total parameters while keeping base weights frozen [17]. QLoRA further quantizes the base model to 4-bit NF4 format, reducing VRAM requirements dramatically—Qwen2.5-VL-7B can be fine-tuned with QLoRA rank 8 on a single GPU requiring approximately 16–24 GB VRAM.
The data requirements are surprisingly modest. As indirect evidence for the effectiveness of LoRA in low-resource industrial settings, PLG-DINO (2025) demonstrated that LoRA-fine-tuned Grounding DINO outperforms all YOLO variants in low-resource industrial defect scenarios [18]—though this result is for an open-set detector, not a VLM, and the transfer of this finding to VLM fine-tuning should not be assumed without direct validation. In our own VLM experiments, 500–2,000 labeled examples yielded significant improvement over zero-shot baselines, with diminishing returns beyond 5,000 examples. The resulting adapter weighs just 200–400 MB versus 14+ GB for full model weights, making version management and A/B testing straightforward.
RAG: grounding in domain knowledge
When the client maintains internal knowledge—defect catalogs, engineering guidelines, prior similar cases—retrieval-augmented generation injects this context dynamically at inference time. Known defect images are indexed in a vector database using CLIP or DINOv2 embeddings; for each query image, the top-k visually similar examples are retrieved and injected into the VLM prompt. VisRAG demonstrated 20–40% end-to-end performance gains over text-based RAG by embedding documents as images directly [19]. However, Wallace et al.'s InspectVLM study (2025) offers a cautionary counterpoint: while unified VLM architectures are appealing in theory, their reliability degrades significantly across varying inspection domains without careful domain-specific adaptation [20]. A separate study on RAG-enhanced VLMs for wind turbine blade inspection (2025) found that retrieval grounding substantially improved classification accuracy on cases where the base model without retrieval performed poorly [21].
RAG's distinguishing advantage is improved traceability: every output can be linked to specific retrieved evidence, which aids human review in regulated inspection contexts. However, traceability is not the same as strict auditability—the VLM's final output is not guaranteed to be faithful to the retrieved evidence, and the retrieved examples may not fully constrain the model's reasoning. In practice, RAG significantly improves reviewability and provides a useful evidence trail, but it does not eliminate the need for human judgment on critical decisions.
vLLM: the serving engine that makes this practical
A VLM-centered inspection stack is only viable if inference is fast enough and memory-efficient enough for production workloads. vLLM, through two core innovations—PagedAttention and continuous batching—makes this possible [22][23].
PagedAttention eliminates the KV cache bottleneck
During autoregressive generation, the model must store key and value matrices for all previous tokens (the KV cache). For a VLM processing high-resolution images, this is particularly demanding: Based on our profiling of Qwen2-VL-7B (FP16 KV cache, 28 layers, GQA with 4 KV heads, 128-dim head), each token generates on the order of 0.03 MB of KV cache, meaning a single 1024×1024 image producing ~4,096 visual tokens can consume roughly 100+ MB of KV cache alone.
Traditional serving systems pre-allocate contiguous memory blocks for each sequence, wasting 60–80% of KV cache memory through fragmentation and over-reservation [22].
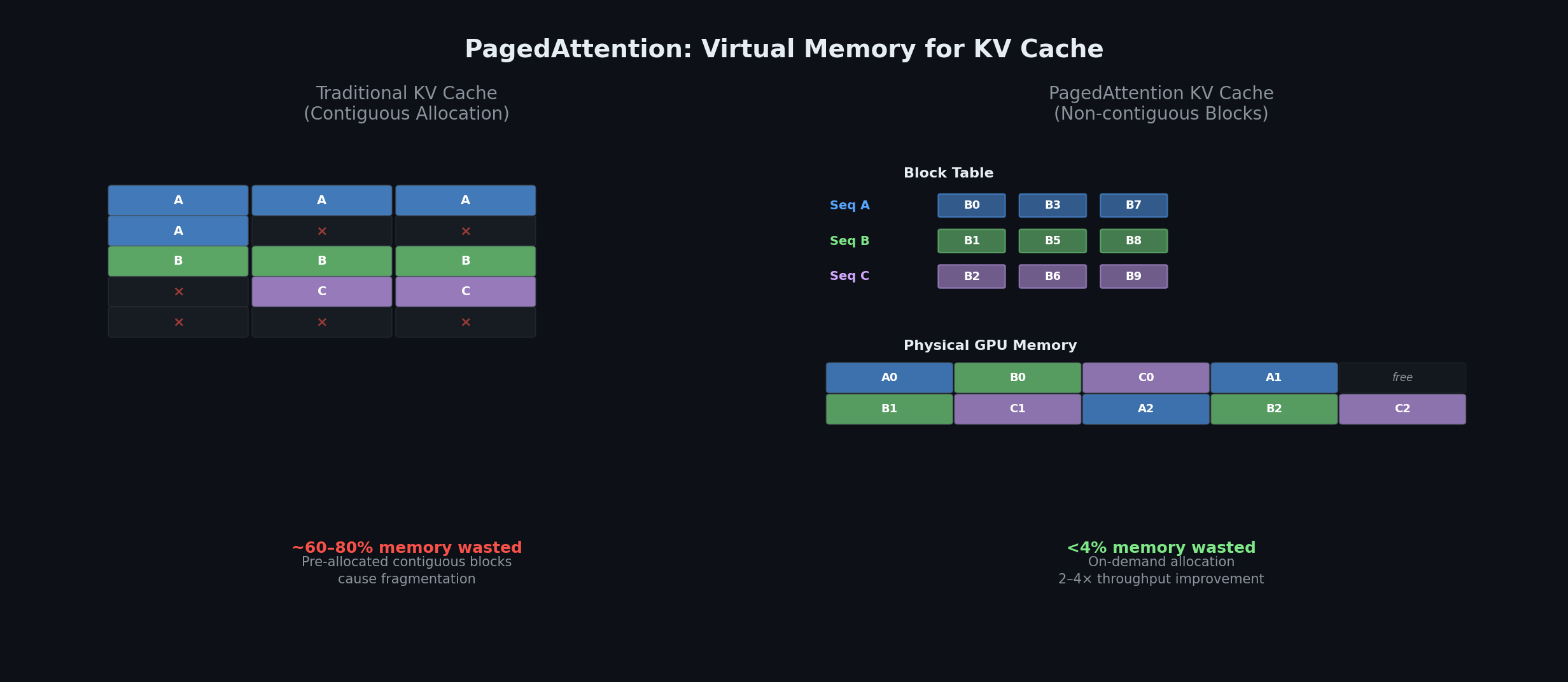 PagedAttention borrows virtual memory concepts from operating systems. Instead of pre-allocating contiguous memory, KV cache blocks are stored in non-contiguous physical memory and mapped through block tables. This reduces memory waste from 60–80% to under 4%, enabling 2–4× throughput improvement [22].
PagedAttention borrows virtual memory concepts from operating systems. Instead of pre-allocating contiguous memory, KV cache blocks are stored in non-contiguous physical memory and mapped through block tables. This reduces memory waste from 60–80% to under 4%, enabling 2–4× throughput improvement [22].
PagedAttention divides the KV cache into fixed-size blocks (typically 16 tokens each) that can be stored non-contiguously in GPU memory. Each sequence maintains a block table mapping logical blocks to physical blocks—analogous to a page table in OS virtual memory. Physical blocks are allocated on demand, with copy-on-write sharing for common prefixes. The result: under 4% memory waste and 2–4× throughput improvement over prior systems [22].
Continuous batching maximizes GPU utilization
Traditional static batching forces all requests in a batch to wait for the slowest sequence, wasting GPU cycles. vLLM's continuous batching operates at iteration-level granularity: at every decode step, the scheduler removes completed sequences and immediately inserts waiting requests. Benchmarks show 14–24× higher throughput versus HuggingFace Transformers and 2.2–3.5× improvement over Text Generation Inference [22].
VLM-specific optimizations in vLLM V1
vLLM V1 (2025) introduced critical multimodal capabilities [24]. An encoder cache stores computed vision embeddings on GPU, eliminating redundant re-execution of the vision encoder across similar prompts. According to the vLLM V1 documentation, metadata-enhanced prefix caching uses image content hashes rather than just token IDs, preventing cache collisions between different images sharing the same <image> placeholder. The hybrid parallelism flag (--mm-encoder-tp-mode data) runs the vision encoder with data parallelism while the language model uses tensor parallelism, reducing all-reduce communication during vision encoding.
In benchmarks reported by Red Hat's developer team on Molmo-72B across 4×H100 GPUs, V1 delivered approximately 40% throughput improvement over V0 [24]. AMD's ROCm team independently confirmed that enabling data-parallel vision encoding provides significant speedups for image-heavy inference workloads [25].
Production deployment: from GPU selection to pipeline architecture
The final phase of our engagement focused on operationalizing the approach for on-premises deployment under real resource constraints.
GPU memory and hardware selection
VLMs consume additional VRAM beyond text-only models due to vision encoder weights, visual token embeddings, and cross-modal attention. Concrete requirements (our estimates): Qwen2-VL-7B needs approximately 16–17 GB at FP16 (fits a single L40S with room for KV cache), dropping to 8–9 GB at INT8. Qwen2-VL-72B demands approximately 144 GB at FP16; at FP8 quantization, this fits on 4×A100-80GB. Users report out-of-memory errors on 24 GB GPUs when processing high-resolution images without constraining the min_pixels/max_pixels parameters [9].
For our industrial inspection workload, the NVIDIA L40S (48 GB GDDR6) offered a favorable balance of memory capacity, inference throughput, and acquisition cost for our workload, handling a 7B VLM at full precision with ample room for KV cache. For a workload of approximately 1,000 images per day, a single L40S sufficed in our configuration; based on our cost modeling, hardware purchase breaks even versus equivalent cloud costs in roughly 7–10 months, though this varies significantly by cloud pricing region and utilization patterns.
Handling high-resolution inspection imagery
Industrial cameras capture at 4K+ resolution, but VLM input limits require intelligent tiling. Qwen2-VL's 675M-parameter ViT processes images at native resolution into variable token counts, controlled via min_pixels and max_pixels [9]. InternVL divides images into 448×448 tiles (1–40 tiles, supporting up to 4K), with pixel shuffle reducing each tile to 256 visual tokens plus a global thumbnail for context [10].
Our recommended approach for 4K inspection images: pre-resize to a bounded resolution (longest edge 2048–4096 px), use sliding-window crops for defect localization, process the full image at low resolution for global context alongside high-resolution crops of regions of interest, and aggregate results across tiles with non-maximum suppression.
The hybrid pipeline
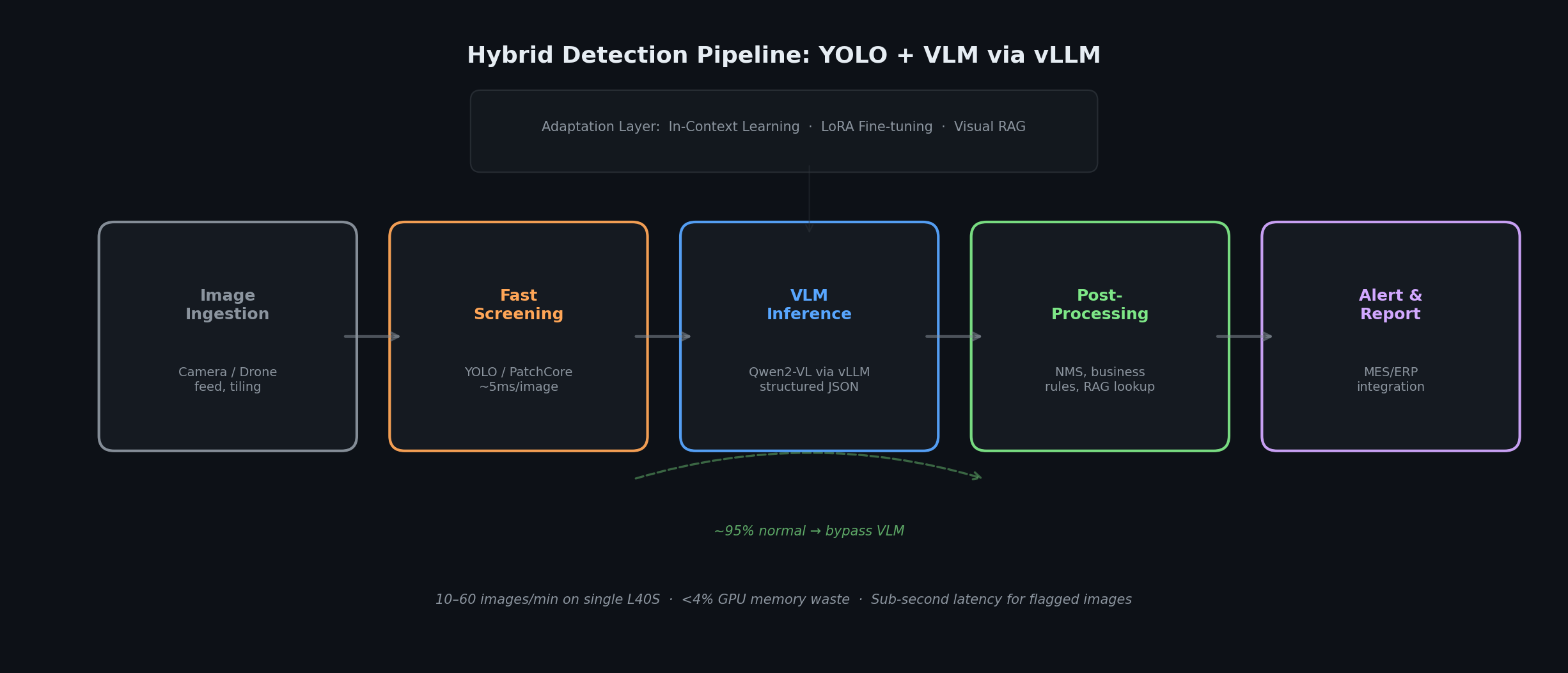 The production pipeline combines a fast first-pass screener with VLM reasoning. In our deployment, roughly 85–95% of images were filtered by the first-pass screener (depending on domain and anomaly rate), yielding a 7–20× reduction in VLM inference volume. The actual ratio depends on the proportion of uncertain or borderline cases routed to the VLM alongside flagged anomalies.
The production pipeline combines a fast first-pass screener with VLM reasoning. In our deployment, roughly 85–95% of images were filtered by the first-pass screener (depending on domain and anomaly rate), yielding a 7–20× reduction in VLM inference volume. The actual ratio depends on the proportion of uncertain or borderline cases routed to the VLM alongside flagged anomalies.
The optimal production architecture combines speed with depth. Image ingestion from camera or drone feeds flows into a preprocessing service that handles resizing, normalization, and tiling. A lightweight first-pass screener (object detectors like YOLO, anomaly detection methods like PatchCore, or vision-language encoders like SigLIP) filters obvious normal cases. Critically, this screener must be tuned for high recall, not high precision: its job is to confidently exclude only clearly normal images, while routing anything uncertain or borderline to the VLM. If the first stage is tuned aggressively for precision, it risks filtering out the very corner cases the VLM is designed to catch—defeating the purpose of the hybrid architecture. In our deployment, the screener's operating point was set to retain all images with anomaly scores above a deliberately low threshold, plus a configurable fraction of "uncertain" samples. The VLM, served via vLLM with an OpenAI-compatible API, processes only flagged images using structured system prompts, returning JSON with defect type, location coordinates, severity, and natural language rationale. Post-processing aggregates multi-tile results, applies business rules, and cross-references defect catalogs. Alerts integrate with existing MES/ERP systems.
Key vLLM configuration for this workload: --gpu-memory-utilization 0.9 to maximize available KV cache, prefix caching enabled for the repeated system prompt across inspections, --limit-mm-per-prompt "image=5" to bound memory per request, and chunked prefill to prevent long image prompts from blocking decode of existing requests.
On a single L40S with Qwen2.5-VL-7B, we observed approximately 10–60 images per minute for the VLM stage in our testing, depending on image resolution and output length. Sub-second latency for individual flagged images is achievable with the hybrid approach.
Results and outlook
This engagement established a practical route to corner-case detection under extreme data scarcity, with a workflow that supports multiple operational realities—from verbal-definition-only to labeled-examples-available.
Three findings shaped our approach. First, the hybrid architecture proved to be the strongest design for this engagement, and we believe the pattern is likely applicable to similar image-heavy inspection workloads with low anomaly rates—though this remains a single-engagement finding. Fast first-pass screeners running at millisecond latency filter the large majority of normal images (85–95% in our deployment), while VLMs provide the reasoning depth needed for corner cases that traditional detectors structurally cannot address.
Second, the adaptation stack matters more than the base model. In our deployment, a 7B VLM fine-tuned with LoRA on 1,000 domain-specific examples and augmented with visual RAG substantially outperformed a raw frontier model on our target inspection tasks—though we note this is a single engagement finding, not a controlled benchmark result. The staged approach—zero-shot deployment in days, LoRA fine-tuning in weeks, domain specialization in months—provides immediate value while building toward production accuracy.
Third, for image-heavy inspection workloads like ours, vLLM V1's multimodal innovations significantly improved the economics of VLM-based inference. Encoder caching, hybrid parallelism, and metadata-enhanced prefix caching specifically address the memory and throughput challenges of image-heavy workloads.
The remaining gap is accuracy: even the best VLMs reach only 74.9% on the MMAD industrial benchmark [15], and the recently released MVTec AD 2 dataset—designed specifically to expose current method limitations—shows state-of-the-art methods performing below 60% average AU-PRO [26]. Closing this gap through domain-specific fine-tuning, reinforcement learning from inspection feedback (as demonstrated by EMIT [27] and similar reinforcement-learning approaches), and active learning loops that prioritize labeling where it maximally improves field performance—this is where the highest-impact work lies in 2025–2026.
References
[1] Shihavuddin et al. "Barely-Visible Surface Crack Detection for Wind Turbine Sustainability." arXiv:2407.07186, 2024.
[2] Baitieva et al. "Supervised Anomaly Detection for Complex Industrial Images." CVPR 2024.
[3] Li et al. "Surface Defect Detection Methods for Industrial Products with Imbalanced Samples: A Review of Progress in the 2020s." Knowledge-Based Systems, 2024.
[4] Zhang et al. "Deep Learning in Automated Power Line Inspection: A Review." arXiv:2502.07826, 2025.
[5] Jiang et al. "T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy." ECCV 2024. arXiv:2403.14610.
[6] Liu et al. "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection." ECCV 2024. arXiv:2303.05499.
[7] Ren et al. "DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding." arXiv:2411.14347, 2024.
[8] Cheng et al. "YOLO-World: Real-Time Open-Vocabulary Object Detection." CVPR 2024. arXiv:2401.17270.
[9] Wang et al. "Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution." arXiv:2409.12191, 2024.
[10] Chen et al. "InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks." CVPR 2024.
[11] Li et al. "LLaVA-OneVision: Easy Visual Task Transfer." arXiv:2408.03326, 2024.
[12] Gu et al. "AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models." AAAI 2024 (Oral). arXiv:2308.15366.
[13] Kim et al. "LogicAD: Explainable Anomaly Detection via VLM-based Text Feature Extraction." AAAI 2025.
[14] Alani et al. "InfraGPT Smart Infrastructure: An End-to-End VLM-Based Framework for Detecting and Managing Urban Defects." arXiv:2510.16017, 2025.
[15] Jiang et al. "MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection." ICLR 2025. arXiv:2410.09453.
[16] Ueno et al. "Vision-Language In-Context Learning Driven Few-Shot Visual Inspection Model." arXiv:2502.09057, 2025.
[17] Hu et al. "LoRA: Low-Rank Adaptation of Large Language Models." ICLR 2022. arXiv:2106.09685.
[18] Chen et al. "PLG-DINO: Industrial Defect Detection via Prompt-Learning Grounding DINO." OpenReview, 2025.
[19] Yu et al. "VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents." arXiv:2410.10594, 2024.
[20] Wallace et al. "InspectVLM: Unified in Theory, Unreliable in Practice." ICCV 2025 Workshop. CVF.
[21] "RAG-enhanced visual language model for wind turbine blade inspection." IFAC-PapersOnLine, 2025. ScienceDirect.
[22] Kwon et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP 2023. arXiv:2309.06180.
[23] vLLM Project. https://github.com/vllm-project/vllm
[24] Red Hat Developer. "vLLM V1: Accelerating Multimodal Inference for Large Language Models." 2025.
[25] AMD ROCm Blogs. "Accelerating Multimodal Inference in vLLM: The One-Line Optimization for Large Multimodal Models." 2025.
[26] Bergmann et al. "The MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection." arXiv:2503.21622, 2025.
[27] Li et al. "EMIT: Enhancing MLLMs for Industrial Anomaly Detection via Difficulty-Aware GRPO." arXiv:2507.21619, 2025.