
AI Anime Production Research · February 2026
Open any social media feed and you'll find breathtaking AI-generated anime clips , characters with luminous eyes dashing through rain-soaked cityscapes, mecha suits pivoting through particle effects, all produced in seconds by typing a prompt. The technology is genuinely impressive. And yet, when we talk to professional animators at studios producing actual anime , the people who ship 24-minute episodes week after week , almost none of them can use these tools in production. This disconnect is not a temporary inconvenience. It reveals something fundamental about where generative AI stands today and what it actually needs to become useful.
We've spent considerable time evaluating the latest generation of AI animation tools against the requirements of real anime production pipelines. Our conclusion: there exists a "controllability gap" , a systematic mismatch between what generative models optimize for (visual impressiveness on individual outputs) and what production demands (precise, reproducible control over every element across thousands of frames). This gap is the central bottleneck preventing AI from graduating from demo showcase to production tool. Understanding why it exists, and what it would take to close it, has implications well beyond anime , it speaks to the broader question of when generative AI can participate in any creative pipeline that demands precision, not just plausibility.
What controllability actually means in anime production
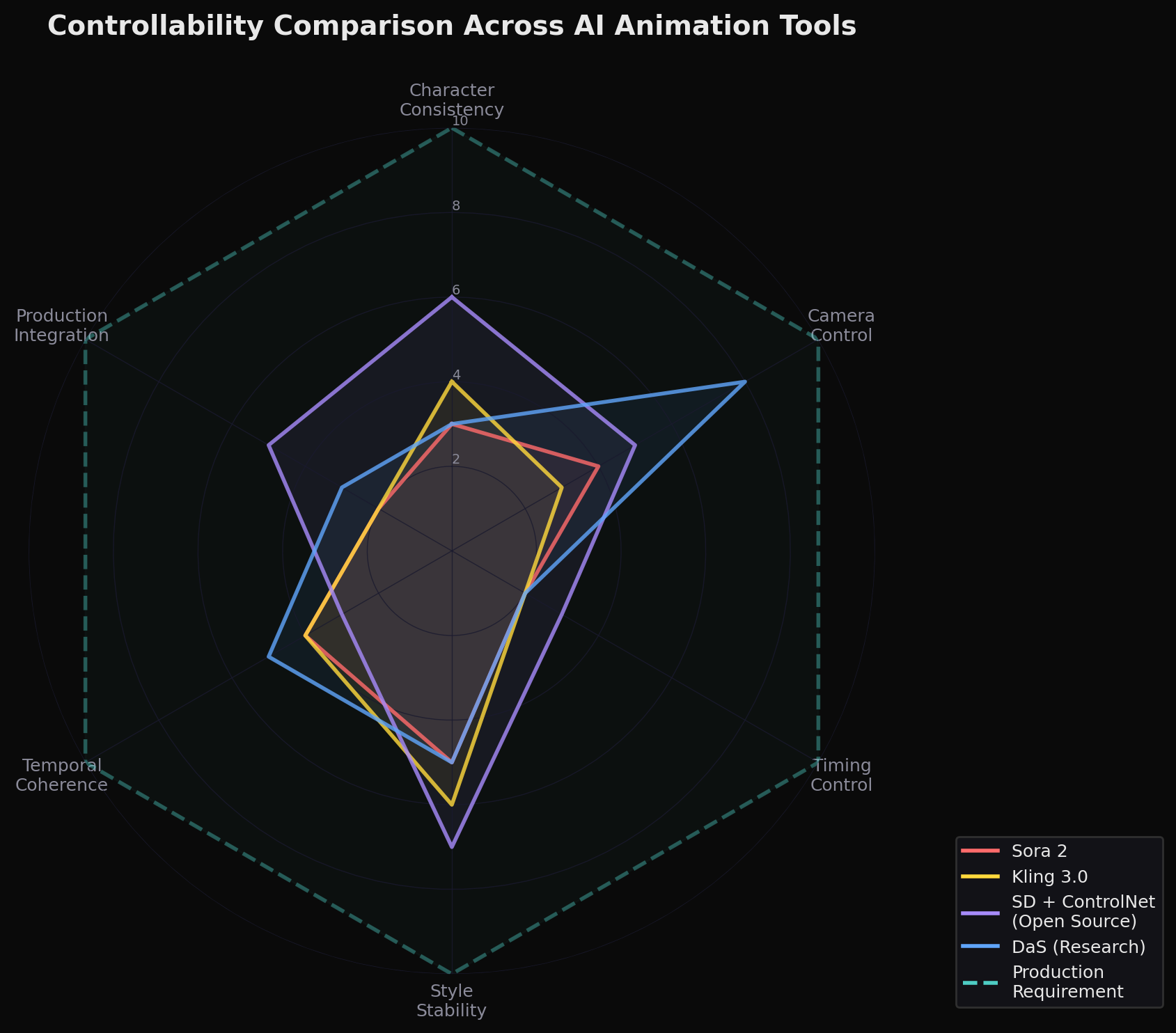
To understand the gap, you first need to understand what anime production actually requires. The word "controllability" might sound abstract, but in a working studio it translates to extremely concrete demands at every stage of the pipeline.
In pre-production, a character designer creates model sheets , turnaround drawings showing a character from multiple angles with precise specifications for proportions, line weights, color palettes, and expression ranges. Every subsequent frame of animation must remain faithful to these sheets. An animator drawing a key frame isn't generating a "plausible anime character"; they're producing a specific character whose left eye sits exactly 1.3 head-widths from the right eye, whose hair falls with a particular silhouette, whose costume wrinkles follow established conventions. This is what being "on-model" means, and studios employ entire teams of animation directors whose job is to correct drawings that drift off-model.
In the production phase, a layout artist specifies exact camera positions, often in coordination with a 3D previz that defines dolly trajectories and focal lengths. Key animators then draw the extremes of motion , the "keys" , while in-between animators fill in intermediate frames. A critical artistic decision here is timing: anime frequently animates "on twos" (one drawing held for two frames, yielding 12 unique drawings per second) or even "on threes," and the choice of when to switch to "on ones" for rapid action is a deliberate creative act that defines the feel of a scene. The spacing between key poses , how much a character's arm moves from frame to frame , communicates weight, emotion, and physics. These decisions are not ornamental; they are the animation.
Post-production introduces its own control requirements. Compositing in anime isn't simply layering elements; it involves precise management of separate cel layers (character, background, effects), each with specific opacity, blending modes, and color grading. A style transfer or upscaling tool that doesn't respect these layer boundaries , that bleeds a character's shadow into a background gradient, or smooths out intentionally flat cel-shaded regions , creates more cleanup work than it saves.
The core issue is this: anime production is an engineering discipline masquerading as an art form. Every creative decision is also a specification, and every specification must be reproducible across hundreds or thousands of frames by dozens of artists. Generative AI, by contrast, is designed to produce outputs that are statistically plausible given a prompt , but "plausible" and "precisely specified" are fundamentally different objectives.
The evidence: where current tools fall short
We examined the latest generation of tools across every stage of the pipeline, evaluating each against the production requirements described above: character identity consistency across shots, camera precision, temporal stability, and layer-level compositing control. Our method was qualitative , structured hands-on testing by practitioners familiar with production pipelines, not a formal benchmark with controlled prompts and blind scoring. With that caveat, the pattern was consistent: impressive individual outputs, inadequate production-level control.
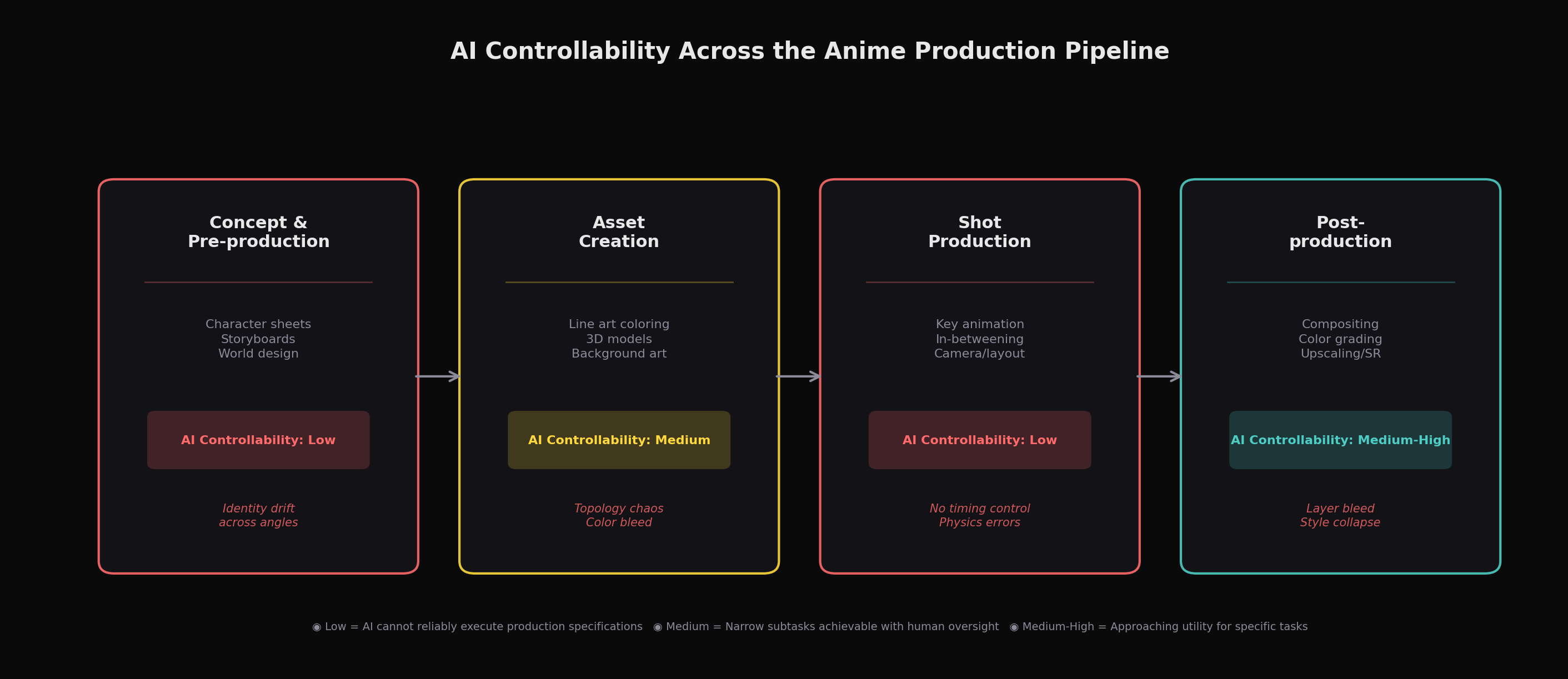
Video generation models struggle significantly with character identity across shots. We tested Sora 2, Kling 3.0, Runway Gen-4.5, Seedance 2.0, Luma Ray3, and Vidu Q1 for anime-style generation. All can produce visually striking anime clips of 5,20 seconds. Kling 3.0's "Stylistic Omni" engine is explicitly tuned for anime proportions and motion. Vidu markets itself as anime-optimized and has partnered with Aura Productions on a 50-episode AI anime series. Sora 2's official documentation claims it "excels at anime styles."
But none of these models can reliably hold a character's identity across multiple shots , the absolute minimum requirement for even a single scene, let alone an episode. Small details vanish between cuts: watches, earrings, costume accessories. More critically, when Runway Gen-4 was tested on anime scene continuity, it exhibited what we call style collapse , characters spontaneously transitioned from anime to semi-realistic rendering mid-generation. Kling maintained better anime stylistic consistency in direct comparison, but still couldn't guarantee the kind of frame-level identity preservation that hand-drawn animation achieves by design. The fundamental problem is architectural: diffusion models sample from learned distributions, and each sample is partially independent. Current models struggle significantly with identity preservation across frames, though emerging approaches such as DaS show that targeted architectural solutions can partially address this gap. Without explicit conditioning mechanisms that enforce identity across temporal boundaries, drift remains a persistent challenge.
Camera control remains imprecise. Anime cinematography is highly deliberate , a slow pan across a cityscape, a snap zoom to a character's eyes, a tracking shot following a running figure. Recent research has made real progress here: Diffusion as Shader (DaS), a SIGGRAPH 2025 paper from HKUST, NTU, and others, introduces a unified architecture using 3D tracking signals to achieve camera control, object manipulation, and motion transfer within a single framework. The key insight is elegant: by colorizing dynamic 3D points according to their coordinates to produce a "tracking video," DaS grounds diffusion in 3D-aware control signals rather than the 2D heuristics (depth maps, optical flow) that prior methods relied on. I2VControl-Camera (ICLR 2025) takes a different approach, using point trajectories in camera coordinate space to separate camera motion from object motion.
These are genuine advances. Yet even DaS , arguably the most sophisticated control framework published to date , still operates within the generation paradigm. It provides significantly better guidance than predecessors, but it cannot guarantee deterministic rendering. An animation director who specifies a 3-second dolly-in ending at a 35mm-equivalent focal length needs that specification executed precisely, every time. "Significantly better than MotionCtrl" is not the same as "production-ready."
Colorization tools solve a narrow problem well but reveal broader limitations. MangaNinja, a CVPR 2025 Highlight paper from Alibaba, HKU, and HKUST, demonstrates genuinely impressive reference-guided line art colorization. Its dual-branch architecture , a reference U-Net combined with a patch shuffling module that forces local correspondence learning , can maintain character color identity even across extreme pose variations. The interactive point-based guidance system allows artists to specify matching points between reference and target, giving far more control than prior automated approaches.
This is perhaps the closest any current tool comes to production utility, because it solves a well-defined subtask (colorizing line art) with meaningful artist control (reference images plus point matching). But even MangaNinja operates in latent space, meaning fine details can shift subtly during the diffusion process. And crucially, it's a single-frame tool , applying it to sequential animation frames doesn't inherently guarantee temporal consistency across those frames. In a production context, even subtle color flickering between frames is unacceptable.
3D asset generation can't produce animation-ready topology. We examined Hunyuan3D 2.5 (Tencent's 10-billion-parameter model, released April 2025), Tripo AI's Prism 3.0, and Meshy AI's latest offering. Hunyuan3D 2.5 represents a notable improvement: geometric resolution doubled from 512 to 1024, and the team specifically addressed the topology problems that made v2.0 outputs unsuitable for rigging and skeletal animation. It now generates albedo, normal, roughness, and metallic PBR maps.
However, "improved topology for animation" is not the same as "animation-ready topology." AI-generated meshes remain dense , community tests report triangle counts in the hundreds of thousands from Hunyuan3D, though we have not found a definitive first-party figure , and require manual retopology for any production pipeline that involves skeletal deformation, blend shapes, or real-time rendering. Tripo AI generates cleaner quad-based topology for game assets, but the quality varies unpredictably. For anime 3D departments , which use 3D models as reference geometry for hand-drawn animation, or as direct render targets for hybrid productions , the inability to control edge flow, joint deformation zones, and face count makes these tools supplementary at best.
Why traditional evaluation metrics miss what matters
There is a deeper structural reason the controllability gap persists: the metrics the research community uses to evaluate generative models don't measure what anime production actually cares about.

Fréchet Video Distance (FVD), the standard benchmark for video generation quality, was shown in a 2025 ICLR paper ("Beyond FVD") to have three critical limitations: the I3D feature space it relies on violates the Gaussian assumption underlying the metric; it is insensitive to temporal distortions (it doesn't adequately penalize frame-ordering violations); and it requires far more samples than typically used for reliable estimation. For anime specifically, FVD cannot distinguish between a smooth 24fps interpolation and an intentionally limited animation running on twos or threes , yet this distinction is fundamental to the art form.
FID (Fréchet Inception Distance) relies on Inception v3 features pretrained on ImageNet , a photorealistic dataset whose distribution bears little resemblance to anime's flat colors, bold outlines, and simplified forms. Models that produce excellent anime may score poorly on FID simply because their outputs don't look like photographs. CLIP scores, meanwhile, are trained on web-crawled alt-text captions and are, as one CivitAI evaluation study noted, "not well-suited for anime models due to how different Booru tagging is from regular images." The Danbooru tagging system that anime AI practitioners use for precise character specification (hair color, eye shape, clothing details via thousands of specific tags) has no representation in CLIP's training distribution.
Even VBench, a comprehensive 16-dimensional evaluation suite, has a structural bias against anime: it penalizes temporal flickering while rewarding smoothness, which means a completely static image scores better than a dynamic but intentionally limited animation. No existing benchmark measures line weight consistency across frames, the quality of cel-shading boundary placement, whether animation timing follows ones-versus-twos conventions appropriately, or whether smear frames (intentional motion distortion used in fast action) are deployed correctly. The anime-specific evaluation gap means researchers lack systematic incentives to optimize for production-relevant capabilities , one significant factor, among others, in why those capabilities remain underdeveloped.
The industry's cautious, fractured response
The anime industry's relationship with AI tools reflects the controllability gap in practice. Despite a $25.25 billion market (¥3.84 trillion, per the Association of Japanese Animations' 2024 data , a new all-time record, up 14.8% year-over-year) and acute labor pressures, actual adoption remains narrow and cautious.
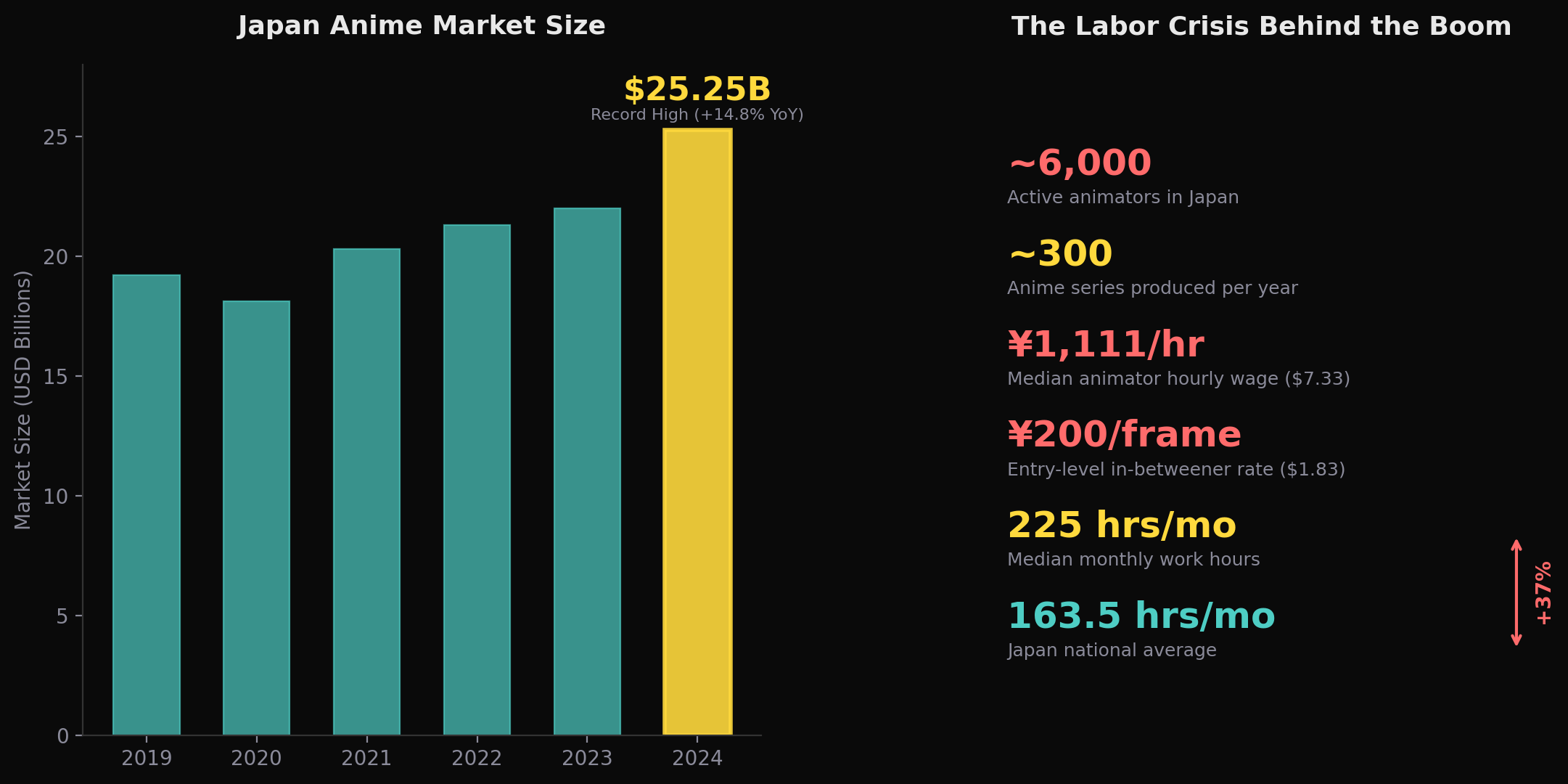
The labor situation is genuinely severe. Japan has approximately 6,000 animators (per Asahi Shimbun reporting), while annual anime series output has roughly tripled over two decades to around 300 titles per year (per industry tallies). These figures come from different surveys and time frames, so they should not be read as a single unified productivity metric , but the directional picture is clear: output has scaled far faster than headcount. The median hourly rate for animators is ¥1,111 ($7.33) , slightly below Tokyo's minimum wage , with entry-level in-betweeners earning roughly 200 yen ($1.83) per drawing (per the 2024 NAFCA survey). A 2024 UN Human Rights Council report explicitly condemned these conditions, citing "the stark contrast between the global profitability of the $20 billion anime business and the treatment of the artists who create it." The economic incentive for automation is enormous.
Yet the studios investing in AI are deploying it for tightly scoped subtasks, not generative production. Sony's AnimeCanvas software , developed through subsidiaries A-1 Pictures and CloverWorks , provides AI-assisted ink and paint that reduces click count by approximately 15% and an automatic lip-sync engine deployed on four productions. Toei Animation has invested in Preferred Networks, a Japanese AI firm, for future tools targeting background generation (publicly demonstrated through their Scenify collaboration), with storyboard generation and in-between correction also reported as areas of interest though not yet publicly confirmed , but explicitly clarified that "none of their productions are currently making use of the technology" after the announcement drew massive fan backlash. Sony Pictures Imageworks developed an ML tool for the Spider-Verse films that predicts lines artists might draw on each frame , but artists accept, modify, or reject each suggestion. The common thread among the most visible studio deployments we examined: AI as assistant within human-controlled workflows, never as autonomous generator.
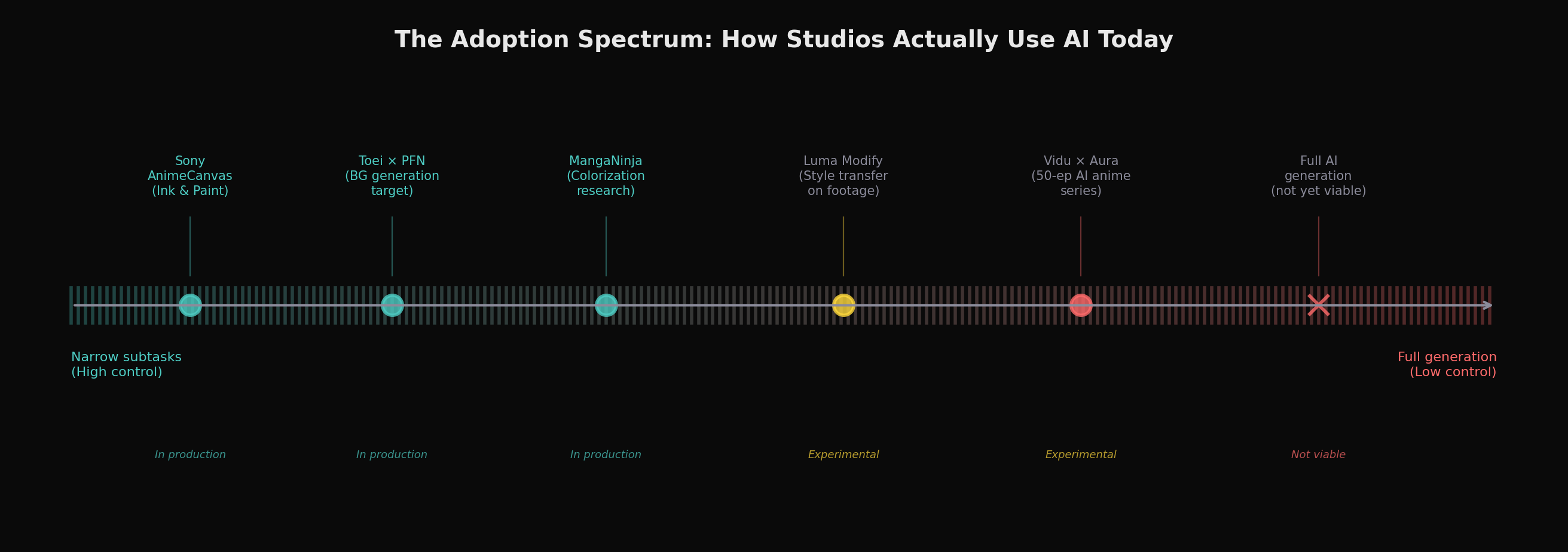
Every major attempt at more ambitious AI anime production has met significant criticism. Netflix Japan's The Dog & The Boy (2023), which used AI for all background images, was criticized by professionals for artistic inconsistencies and for crediting the human background artist as simply "AI (+Human)." Corridor Digital's Anime Rock, Paper, Scissors (2023), which used Stable Diffusion to style-transfer live-action footage, prompted Anime News Network to publish a detailed analysis titled "No, You Can't Make Anime with AI" , arguing that the AI understood what animators produce but not why they make the decisions they do. As animation industry analyst Matt Ferguson summarized in late 2025: "AI's role in animated TV and film remains fairly limited. The uses tend to be narrow and targeted, and supplement the work of artists, rather than completely automating the process."
Emerging paths toward closing the gap
Despite the current limitations, several research directions show genuine promise for narrowing the controllability gap. These approaches share a common strategy: rather than trying to generate anime end-to-end, they provide structured control interfaces that align with how production actually works.
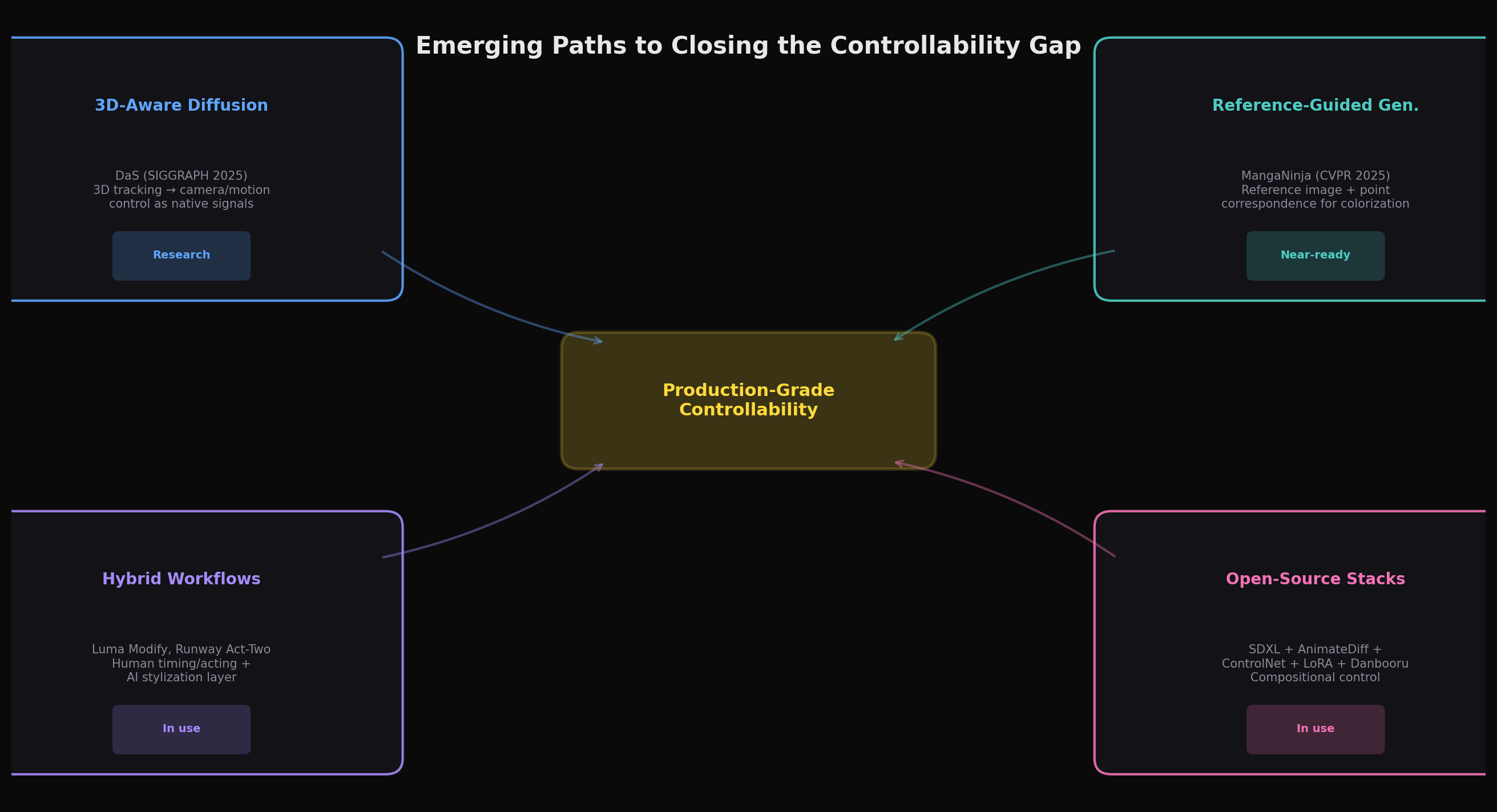
3D-aware diffusion represents, in our assessment, the most architecturally sound approach to camera and scene control. DaS's insight , that versatile video control requires 3D-aware signals because videos are fundamentally 2D renderings of dynamic 3D content , points toward a future where animators work with 3D scene representations and use diffusion models as sophisticated renderers. The system already supports camera control, object manipulation, mesh-to-video generation, and motion transfer through a single unified architecture, trained on fewer than 10,000 videos. If this approach matures to where 3D control signals produce deterministic (or near-deterministic) stylized outputs, it could map naturally onto anime production workflows that already use 3D previz extensively.
Reference-guided generation aligns with production logic. MangaNinja's approach of using explicit reference images plus point-based correspondence matching mirrors how anime production actually works , colorists reference model sheets and prior frames. Extending this paradigm to temporal sequences (where each frame references both the model sheet and the previous frame) could provide the identity consistency that unconditioned generation lacks. The broader family of IP-Adapter and reference-conditioning approaches, particularly within the open-source Stable Diffusion ecosystem, enables artists to specify style and character through images rather than text , a far more natural interface for visual work.
Hybrid human-AI workflows may yield the earliest practical returns, judging by current deployment patterns. Luma Ray3's Modify feature can transform live-action footage into anime-styled output while preserving the original performance's motion, timing, and emotional delivery. Runway's Act-Two maps facial performances onto generated characters. These tools essentially treat AI as a sophisticated rotoscoping or style-transfer layer within an otherwise traditional pipeline , and this may be exactly the right level of ambition. Rather than asking AI to generate animation from scratch (a task requiring control over every element simultaneously), hybrid workflows let humans handle what they're good at (timing, acting, composition) while AI handles what it's good at (consistent stylization, texture generation, rapid iteration).
The open-source ecosystem currently offers the deepest controllability, in our assessment. The Stable Diffusion ecosystem , particularly SDXL-based anime models like Pony Diffusion V6 XL, combined with AnimateDiff for motion, ControlNet for structural guidance, and IPAdapter for style reference , provides a level of compositional control that we have not found replicated in closed commercial models as of this writing. Artists can stack multiple ControlNets (pose, depth, lineart), apply character-specific LoRAs trained on 30,100 images, and build reproducible ComfyUI workflows that chain these components. The Danbooru tagging system gives anime practitioners a precise vocabulary of thousands of specific visual attributes. This ecosystem is technically demanding and produces shorter, lower-resolution outputs than commercial models , but it's the clearest current path toward something resembling production-level control.
What needs to happen next
For generative AI to move from impressive demo to production tool in anime, several things need to converge , and some of them are not purely technical.
First, the research community needs anime-specific evaluation benchmarks that measure what production actually cares about: line consistency across frames, cel-shading quality, on-model character fidelity to reference sheets, timing appropriateness (ones versus twos versus threes), and spatial consistency of flat color regions. Without these metrics, researchers lack a systematic incentive to optimize for animation precision , and while benchmark gaps are not the only reason models skew toward photorealism (training data distribution, commercial demand, and RLHF tuning all contribute), they remove one of the most effective levers the research community has for redirecting effort. The 2025 survey paper "Anime Generation through Diffusion and Language Models" identifies this gap explicitly but no comprehensive benchmark yet exists.
Second, model architectures need to move from generative to controllable-generative , systems that accept structured specifications (character model sheets, timing charts, camera layouts) as first-class inputs, not afterthoughts conditioned through adapter modules. The DaS approach of treating 3D scene information as a native control signal, rather than a ControlNet-style bolt-on, points in the right direction. What anime production needs is something closer to a "programmable renderer" than a "creative generator."
Third, the copyright landscape must stabilize. Japan occupies a paradoxical position: its Copyright Act Article 30-4 has been historically permissive in comparative terms, with provisions that allow use of copyrighted works for information analysis. However, the statute is subject to a "non-enjoyment purpose" requirement and a condition that use must not "unreasonably prejudice the interests of the copyright owner" , and Japan's Agency for Cultural Affairs has emphasized that its interpretive guidance on these provisions is not legally binding. The practical scope of Article 30-4 is increasingly contested. Yet in October 2025, CODA , the Content Overseas Distribution Association, representing Studio Ghibli, Toei Animation, Bandai Namco, Kadokawa, Shueisha, and dozens of other rights holders , formally demanded that OpenAI stop using member content for training without prior authorization. This unresolved tension creates legal uncertainty that discourages studios from adopting tools whose training data provenance is unclear.
Fourth, the industry needs to honestly confront its labor economics. The controllability gap and the labor crisis are connected: studios operating on razor-thin margins with exploited workers have neither the resources to develop bespoke AI tools nor the organizational capacity to redesign workflows. The framing of AI as a solution to "labor shortages" rings hollow when the core issue is compensation , Netflix Japan's The Dog & The Boy triggered backlash precisely because professionals pointed out there is no shortage of animation labor, only a shortage of adequately compensated animation labor. AI tools that reduce costs without restructuring how value flows to creators risk deepening the exploitation that makes the industry unsustainable.
The broader lesson about generative AI
The anime production case crystallizes a truth that applies far beyond animation: the gap between "can generate impressive outputs" and "can participate in a professional workflow" is far larger than demos suggest, and controllability , not raw visual quality , is the dimension where the shortfall is most acute. Current generative models are already good enough, visually, for many production applications. What they lack is the ability to be precisely directed , to accept detailed specifications and execute them faithfully, repeatedly, across the sustained timescales that real production demands.
We suspect this lesson extends to other precision-dependent visual domains , architecture, industrial design, scientific illustration, medical imaging , though each has its own workflow structure, regulatory constraints, and tolerance thresholds that we have not examined here. What we can say is that the anime industry, with its extreme demands for consistency, its well-documented production pipeline, and its acute economic pressures, makes the controllability gap maximally visible. Closing this gap is, we believe, one of the most important and underappreciated challenges in applied AI research , and the solutions developed for anime's demands would likely transfer to other fields where specification-adherence matters more than plausibility.
Frequently Asked Questions
Q: Can AI already produce anime today?
It depends on what you mean by "produce." AI can generate short anime-style video clips of 5,20 seconds that are visually impressive in isolation. Tools like Vidu (which markets anime optimization as a core feature) and Kling 3.0 (with its Stylistic Omni engine tuned for anime proportions) produce results that genuinely look like anime frames. Vidu has partnered with Aura Productions on a 50-episode AI-generated sci-fi series, reporting "several-fold reduction in post-production costs." However, no AI tool can currently produce animation that meets the standards of professional studios like Toei, MAPPA, or WIT Studio without extensive human intervention. The core limitations , character consistency across shots, precise timing control, style stability over long sequences , remain unsolved. What AI can do today is assist with specific subtasks: colorization, background generation, lip-sync, and super-resolution. Sony's AnimeCanvas and Toei's investment in Preferred Networks represent this assistive paradigm.
Q: What about tools like Google Flow that claim full pipeline support?
Google Flow, launched at Google I/O in May 2025, is an impressive filmmaking platform powered by Veo 3 and Imagen 4. It supports text-to-video, scene extension, start-frame/end-frame transitions, and native audio generation, and has been used to create over 275 million videos. However, Flow is designed primarily for photorealistic and cinematic content, not anime specifically. It lacks anime-specific style controls (no equivalent to LoRA fine-tuning or Danbooru tag conditioning), has no mechanism for enforcing character model sheet consistency, and provides no control over animation timing conventions. Users have successfully animated hand-drawn illustrations through Flow, and the keyframe transition feature could theoretically support key-to-key interpolation , but it remains a general-purpose tool without the specialized control interfaces anime production requires.
Q: Will AI replace animators?
Not in the foreseeable future, and the question itself may be poorly framed. The controllability gap means that the roles requiring the highest creative judgment , key animators and animation directors who make the decisions that define how animation looks and feels , are the hardest for current AI to replicate. Roles involving more repetitive, specification-following work , such as in-betweening and colorization , may be more exposed to automation, though other functions like background painting, layout assistance, and post-production cleanup are plausibly in a similar position. The exact exposure depends on how quickly controllability improves in each subtask. What is clear is that the lowest-paid positions (entry-level in-betweeners earn roughly $1.83 per drawing in Japan) overlap significantly with the most automatable ones. Ironically, automating these roles without restructuring the industry's economics could worsen conditions rather than improve them , removing entry-level positions that serve as training grounds while concentrating more work on fewer senior artists. The more constructive framing is whether AI can make anime production sustainable by reducing the brutal workload (median 225 hours per month, versus Japan's national average of 163.5) while preserving creative control and creating new career paths around AI-assisted workflows.
Q: What's the most promising near-term application?
Reference-guided colorization is arguably closest to production readiness. MangaNinja (CVPR 2025) demonstrates that diffusion models can colorize line art while following reference images and artist-specified point correspondences with high fidelity. This maps directly onto a real production bottleneck , colorization is repetitive, specification-driven work that consumes significant resources. The key remaining challenge is temporal consistency: ensuring colors don't flicker between frames when applied independently. If reference-guided approaches can be extended to enforce consistency across frame sequences (perhaps by conditioning each frame on both the reference sheet and the previous frame's output), this subtask is among the most likely candidates for near-term automation, though we lack a reliable basis for predicting a specific timeline. AI-assisted background generation is another strong candidate; Toei Animation explicitly identified it as a target application, and the task is less constrained by the character consistency requirements that make character animation so challenging.
Q: How does this relate to the broader AI video generation landscape?
The anime controllability gap is an especially visible instance of a general problem. All frontier video generation models , Sora 2, Kling 3.0, Runway Gen-4.5, Seedance 2.0 , struggle with precise controllability. Camera directions are interpreted approximately (dolly-ins become zooms, orbits become pans). Character details drift across shots. Complex multi-element choreography requires extensive iteration. These limitations are tolerable for social media content, marketing videos, and creative exploration, where each output stands alone and approximate adherence to intent is sufficient. They become disqualifying in any production context , not just anime, but film VFX, architectural visualization, or medical animation , where outputs must meet exact specifications and maintain consistency across long sequences. The anime industry's extreme requirements make it a useful bellwether: if AI tools can satisfy anime production demands, that would be a strong signal of readiness for other precision-dependent visual work , though each domain has its own constraints that would need independent validation.
Key references: Diffusion as Shader (SIGGRAPH 2025) · MangaNinja (CVPR 2025) · I2VControl-Camera (ICLR 2025) · Beyond FVD (ICLR 2025) · Hunyuan3D 2.5 (Tencent, 2025) · APISR (CVPR 2024) · AJA Market Report 2024 · NAFCA Animator Survey 2024