
A research note on why the right objective for industrial synthetic data is the opposite of the objective driving the generative-AI mainstream, and what a controlled study with an automotive OEM measured.
Specialist CV models (object detection, semantic segmentation, OCR, depth estimation, tracking) are only as good as the data they were trained on. The hardest scenes for these models are not the common ones. They are the corner cases: rare object classes, unusual spatial arrangements, scenarios that cannot be staged or collected on demand. This is the gap that separates a detector that is impressive in a demo from one that holds up in production.
The mainstream response to the data problem is to scale collection: more labelled images, more annotators, more storage. For long-tail vision in safety-critical settings, that response runs out fast. The world is long-tailed. Corner cases cannot be collected on demand. Conventional augmentation (flips, crops, colour jitter) introduces invariance to nuisance variation but no new visual content. The cases that matter most are precisely the ones that are hardest to add to the training set.
This note works through the design objective that, in our reading of the problem, synthetic data for long-tail vision actually needs to satisfy, why that objective is deliberately the opposite of what mainstream generative AI optimizes for, and what a controlled study with an automotive OEM measured under that objective.
The mismatch: visual appeal versus training utility
The generative-AI industry competes on producing images that are beautiful. Visual quality, aesthetic coherence, prompt fidelity for human evaluators: these are the objectives that drive frontier text-to-image research and what most general-purpose generators are optimized for.
A model optimized for visual appeal is not, by default, a useful source of training data. Two properties that human evaluators don't penalize are exactly the properties that make synthetic data harmful as training material:
Positional drift. A generator can produce a beautiful image of a "truck partially extending past the frame on a Japanese highway" while placing the truck in slightly different positions than the prompt specifies. To a human grader, this is fine. To a downstream detector being trained on these images, the bounding-box annotation derived from the prompt no longer matches the rendered object location, and the model learns subtly wrong correspondences between annotations and pixels.
Domain drift. A generator trained on web-scale aesthetic imagery produces something that looks like "Japanese highway by fisheye camera" without actually matching the distortion profile, exposure characteristics, or noise floor of the target camera system. The synthetic image looks correct to a human evaluator and looks like a different domain to a CNN's feature extractor, and the model trained on the mix either ignores the synthetic data (best case) or learns the synthetic distribution at the cost of the real one (worst case).
Both properties are tolerable in a content-generation setting and disqualifying in a training-data one.
A different objective: functional correctness
The design objective that follows from the analysis above is simple to state: generate training data that makes recognition models better, not images that look better to a human grader. That objective splits into two measurable properties.
Positional fidelity
Generated objects appear exactly where their annotations specify. The input layout becomes the output annotation by construction; there is no separate labelling step, and no drift between the prompt's spatial intent and the rendered pixels. For a detection model, this is the property that makes synthetic data usable at all. For a segmentation model, the property has to hold at pixel granularity along object boundaries.
General-purpose generators are not just neutral on this property; they are actively optimized against it, because a generator that rigidly preserves a specified layout gets penalized by human evaluators for "looking constrained." That is the right loss for content and the wrong loss for training data.
Stylistic coherence
Generated images match the visual characteristics of the target deployment environment (the specific camera system, lighting, atmospheric conditions, sensor noise profile), and they do so from extremely few reference images and no annotations.
This is the property that closes the domain gap between synthetic and real. A model trained on a mix of real images and synthetic images that don't match the deployment domain will, in practice, perform worse than one trained on the real images alone. Stylistic coherence is what lets the synthetic data contribute training signal rather than dilute it.
A taxonomy of long-tail gaps, and the generation moves that address them
Different long-tail failure modes need different kinds of synthetic data. The four categories below are not features of a tool; they are a description of the gaps we kept running into in real datasets, and the kind of synthetic example each gap requires. In a given training run, they can be combined in a single batch.
1. Rebalancing the long tail
Replace over-represented object classes with rare ones in existing scenes. Scene composition is preserved; only the target objects change. The result is a directly rebalanced class distribution without new data collection.


2. Increasing instance density
Add new object instances at plausible positions within existing scenes. Each generated image carries more labelled objects than the source, providing a denser training signal per frame.


3. Targeting specific corner cases
Specify the exact scenario the detector needs to see (an extremely close truck, an unusual spatial arrangement, a rare configuration) and generate as many diverse examples as required.


4. Generating unknown objects
Generate objects that never appeared in the training data (road debris, unusual obstacles, animals) as new categories at specified positions with correct annotations. This extends the detector's vocabulary to classes with zero real-world training samples.


A controlled study with a major automotive OEM
The research above raises a measurable question: does training a detection model on this kind of synthetic data actually improve it on the corner cases the operator cares about? To answer that, we ran a controlled study with the R&D division of a major automotive OEM.
The OEM's autonomous-driving team operates a multi-camera sensor suite with wide-angle and fisheye lenses. They provided 24,000 annotated images from their production dataset as the training set, plus a held-out test set. The dataset's distribution was typical of the industry:
- Passenger cars: thousands of instances.
- School buses, fire trucks, construction vehicles: a handful of each.
- Close-range vehicles filling the entire frame, which are the most dangerous scenarios for an autonomous vehicle, severely underrepresented.
- Trucks so close that they extend beyond the frame and appear only partially: 233 instances in 24,000 images.
The generation model was adapted to the OEM's camera configurations, and ~36,000 synthetic images were produced across the four modes above. The synthetic data was added to the real training set; the detection model was retrained from scratch on each mix; performance was measured on the held-out test set.
Study design
The numbers reported below come from a single engagement with one OEM. We document the setup so readers can judge what the results do and do not show.
- Detector. A standard one-stage detection architecture in the YOLO family, trained from scratch (no ImageNet or COCO pretraining) for each data mix, on the same hyperparameter configuration the OEM uses internally for this sensor suite.
- Training data. 24,000 annotated production frames provided by the OEM. We did not modify the real-training-data labels in any of the runs reported here; the synthetic frames added to the mix carry annotations produced by construction (positional fidelity) and are tagged with their generation mode.
- Test data. A separately held-out test set provided by the OEM. The test set was never seen by the generator and was not used to select synthetic generations. We did not look at test-set imagery during the study.
- Metric. mAP@0.50:0.95 on the held-out test set.
- Baselines. Three baselines on real-only data: 24,000 real, 30,000 real, and 60,000 real frames (the largest the OEM could supply). The 30K-real baseline is the comparator for the "synthetic at parity volume" finding.
- Repetitions. Each data mix was trained on a single random seed for the runs reported here. We did not estimate variance via multiple seeds, and we therefore do not attach a confidence interval to any individual mAP point. The directional improvement (monotone increase as synthetic volume grows) is the load-bearing finding; the absolute numbers should be read as point estimates from a single engagement.
- External validity. This is one OEM, one camera suite (wide-angle and fisheye lenses), one detector family. The design objective (positional fidelity + stylistic coherence) is what we believe transfers; the specific magnitudes do not.
What this study does not establish: that synthetic data is universally a substitute for real data at any ratio, that the curve continues to slope upward indefinitely, or that the per-instance value of a synthetic example equals that of a real one across all difficulty levels. It establishes that, for this OEM, the synthetic data we generated contributed positive signal at the volumes tested, and that targeted synthetic examples improved a specific corner case that was systematically underrepresented in real data.
mAP improvement scales with synthetic volume
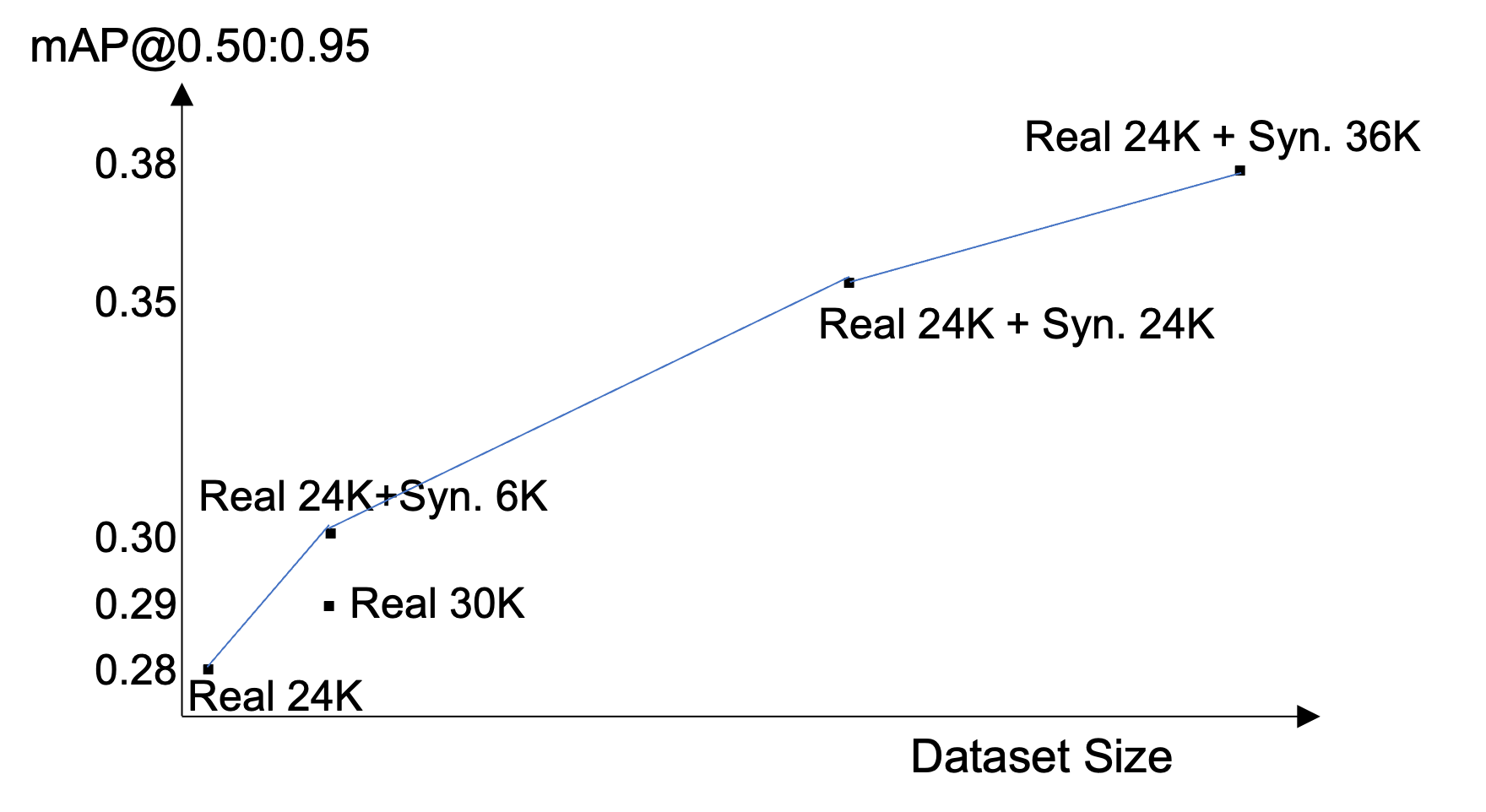
mAP from 0.279 to 0.378. Adding ~36,000 synthetic images improved mAP by +0.099 absolute (+35.5% relative). The curve had not plateaued at the maximum tested volume, though marginal gains likely diminish as the synthetic-to-real ratio increases further.
Synthetic outperformed real at this data ratio
In a controlled comparison, 24,000 real + 6,000 synthetic images achieved higher mAP than 30,000 real images. The result is not a claim that synthetic data is universally better than real. It is a claim that, at this volume and this domain, synthetic images generated via the addition strategy carry more annotated instances per frame, and the denser supervisory signal per image outweighs the value of the additional real images at the margin.
This is the kind of finding that requires both positional fidelity and stylistic coherence to hold. Without positional fidelity, the synthetic annotations would be wrong; without stylistic coherence, the synthetic images would form their own domain and the detector would learn to ignore them.
233 synthetic examples improved the corner case that mattered most
The most pointed result was on the single hardest corner case: trucks so close they extend beyond the frame and appear only partially. The training set had 233 such examples; the test set had 503. We generated 233 targeted synthetic examples matching the corner case and added them to the training set. Detection on this scenario improved.


The relevant detail is the parity of counts: 233 real, 233 synthetic, and the synthetic doubled the effective supervision on a scenario that the closed-set detector had previously been failing on. Whether the synthetic-real parity continues to hold as the count grows is an open question.
Open problems
The design above is not a solved system. The most important open questions, in our experience, are these.
- Marginal gains decay. The mAP curve in the OEM study had not plateaued at the 60% synthetic-to-real ratio tested, but at higher ratios the marginal contribution of additional synthetic data clearly diminishes. We do not have a good model of where the asymptote lives for a given domain.
- Synthetic-real parity is a single data point. That 233 + 233 closed a specific corner case is encouraging. Whether 1,000 synthetic substitutes for 1,000 real images on harder, more compositional corner cases is the next question, and we do not yet have a definitive answer.
- Domain transfer between datasets. A stylistic-coherence adaptation tuned for one fisheye system is not directly transferable to a different wide-angle pinhole. The right object here would be a learning-time procedure that adapts to a new sensor configuration from a small number of unlabeled reference frames, rather than a per-dataset engineering process.
Where this leaves the synthetic-data question
The broader claim worth taking from the study is structural rather than numerical. For long-tail vision, the right objective for synthetic data is positional fidelity and stylistic coherence, not visual appeal, and this objective is in active tension with what mainstream generative-AI evaluations reward. The OEM result is one data point that this objective is the right one to optimize against, on data the operator could not otherwise collect. Whether the same shape of result holds at higher synthetic-to-real ratios, on more compositional corner cases, and across sensor configurations is, in our view, the more interesting set of open questions than the headline mAP number.