
Why reliability demands engineering discipline rather than model scaling, and what the mathematics, benchmarks, and market data tell us about building agents that work in production.
AI agents that chain multiple steps together face a well-known mathematical problem. In a simple sequential pipeline with fixed per-step success and no effective recovery, reliability degrades exponentially with each additional step. A system where each individual step succeeds 95% of the time yields just 36% end-to-end success across 20 steps. That decay curve is a structural property of sequential systems without recovery, rather than a bug to be patched, which is why the responses that materially change it (decomposition, voting, externalized state) are architectural choices that have to be deliberately engineered in.
Benchmark scores for coding and web-task agents have improved sharply, while production deployment data tells a different story: most enterprise AI rollouts remain copilots rather than agents [1][2], and a meaningful share of agentic-AI projects do not reach production [3]. The mathematics behind that gap is the subject of this note, with a focus on what it implies for agentic vision systems, where the cost of unreliability is paid in operational consequences rather than corrected paragraphs.
The mathematics of compound failure are unforgiving
If a pipeline consists of n sequential steps, each with independent success probability p, end-to-end success probability is pⁿ. This exponential decay creates a brutal landscape:
| Per-step accuracy | Steps | End-to-end success |
|---|---|---|
| 99% | 10 | 90.4% |
| 95% | 10 | 59.9% |
| 95% | 20 | 35.8% |
| 90% | 10 | 34.9% |
| 99% | 100 | 36.6% |
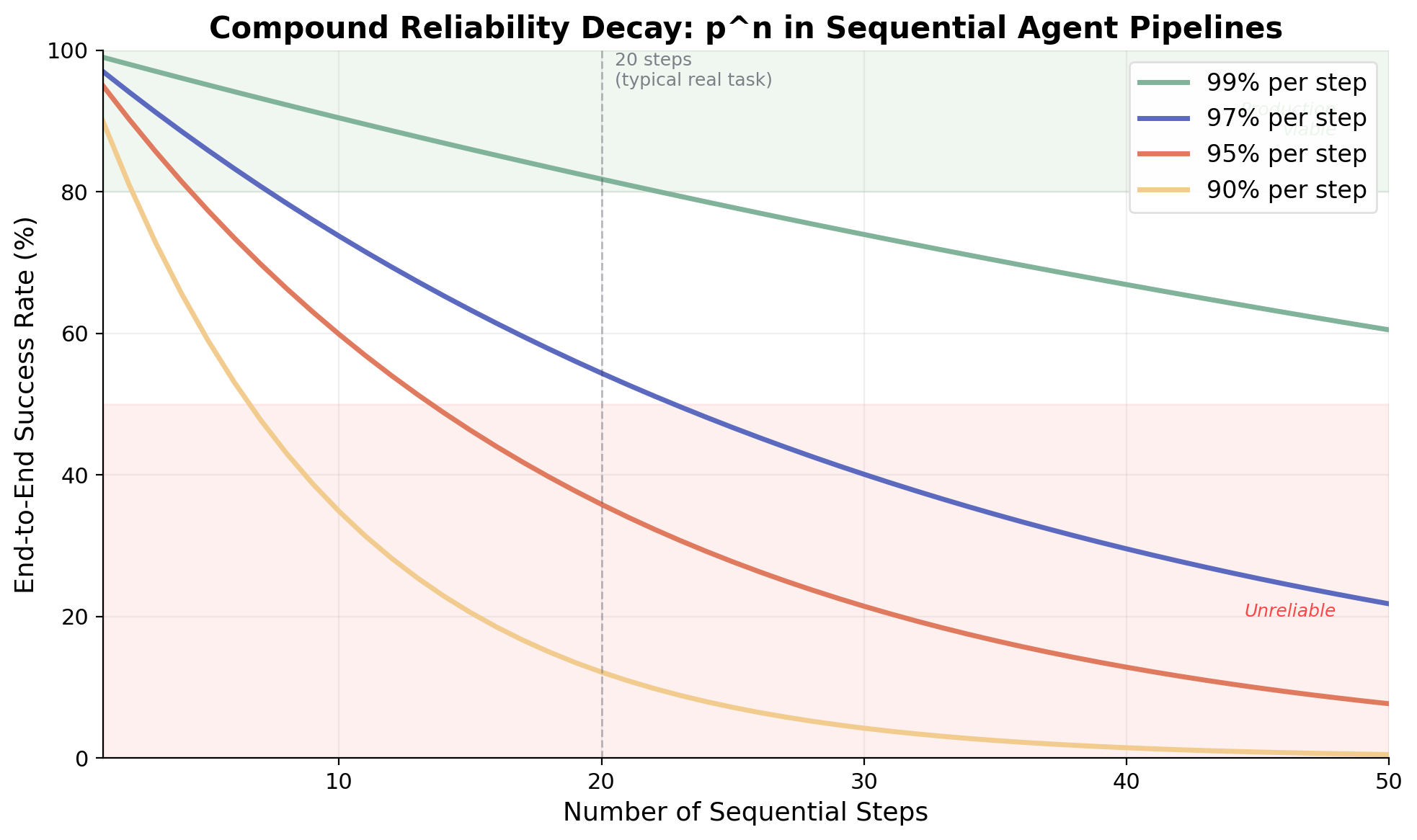 Figure 1. End-to-end success rate as a function of sequential step count, for various per-step reliability levels. Even 99% per-step accuracy yields only 60% success at 50 steps.
Figure 1. End-to-end success rate as a function of sequential step count, for various per-step reliability levels. Even 99% per-step accuracy yields only 60% success at 50 steps.
This simple model actually understates the real problem. Steps in agent pipelines are rarely independent. Errors propagate semantically, corrupting downstream context in ways difficult to detect or recover from. Pedder's concept of "failure stickiness" formalizes this: when errors propagate invisibly through a pipeline (what Pedder calls "absorbing failures"), a system with 95% per-step reliability and high failure stickiness performs dramatically worse than the independence assumption predicts [4]. His analysis shows that the ability to recover from errors is equivalent to making each step 2.7× more reliable, a finding that reframes the reliability problem as fundamentally about recovery architecture, not just step-level accuracy.
A 2025 paper from UC Berkeley, Why Do Multi-Agent LLM Systems Fail? (Cemri et al., NeurIPS 2025) [5] annotated over 1,600 execution traces across seven popular multi-agent frameworks and identified 14 failure modes. Failure rates reached 86.7% in frameworks like OpenHands and MetaGPT on cross-application tests. Proposed interventions like improved role specification proved insufficient; the authors concluded the failures "require more complex solutions."
A more recent framework from Princeton (Rabanser, Kapoor, and Narayanan, "Towards a Science of AI Agent Reliability," 2026) [6] decomposed agent reliability into 12 metrics across consistency, robustness, predictability, and safety. Their central finding is that despite rapid capability improvements across 14 frontier models over 18 months, reliability has barely budged. Pass@1 metrics overestimate true reliability by 20 to 40 percent. The interpretation that follows is that accuracy and reliability are distinct properties: a model can get dramatically better at solving problems while remaining just as unpredictable about which problems it will solve on a given run.
How this looks different in agentic vision
The compound-unreliability problem applies to any sequential agent. A few properties of vision change the shape of the curve, and are worth stating explicitly because they shift which mitigations are even viable.
Visual perception calls sit at a different price point. A specialist CV model invocation costs more compute than a text tool call, so the naive response to unreliability (call more detectors and vote) has a steeper cost curve than the equivalent move in pure text.
Recovery looks different too. When a text reasoning step goes wrong, replaying the same prompt against the same context usually reproduces the failure or yields a comparably cheap retry. When a CV model misclassifies because the frame it saw was occluded, the corrective move is not to rerun the model on the same frame; it is to look at a different frame, a different angle, or the next pass. Recovery here is a coupling between the agent and the sensing layer, not just between agent steps.
And the consumer of the output is often physical. Vision pipelines drive decisions that schedule maintenance, move equipment, or alert operators. The cost of an unsupported claim is not a paragraph the user can edit.
None of these properties make compound unreliability worse in some absolute sense. They change which architectural responses are practical, which is the part worth being explicit about before discussing those responses.
Agent success rates decay exponentially with task complexity
METR's Measuring AI Ability to Complete Long Tasks (Kwa et al., 2025) [7] provides the definitive empirical picture. The researchers measured the "50% time horizon", the task length (in human-equivalent time) at which an agent succeeds half the time. For Claude 3.7 Sonnet, this horizon sat at ~50 minutes.
Toby Ord's subsequent analysis [8] explored the implications under a constant-hazard-rate assumption, a simplified model that treats failure probability as uniform across task duration. Under this framing, if an agent achieves 50% success on 50-minute tasks, it can only achieve 90% success on tasks of about 7 minutes, and 99% success on tasks of roughly 43 seconds. For enterprise applications requiring 99.9% reliability, usable task length collapses to seconds. These are back-of-the-envelope extrapolations rather than operational measurements, but the order of magnitude is the relevant part. Ord also noted that human survival curves on equivalent tasks are noticeably better than this constant-hazard model predicts, which is consistent with humans being better at recovery than current agents are.
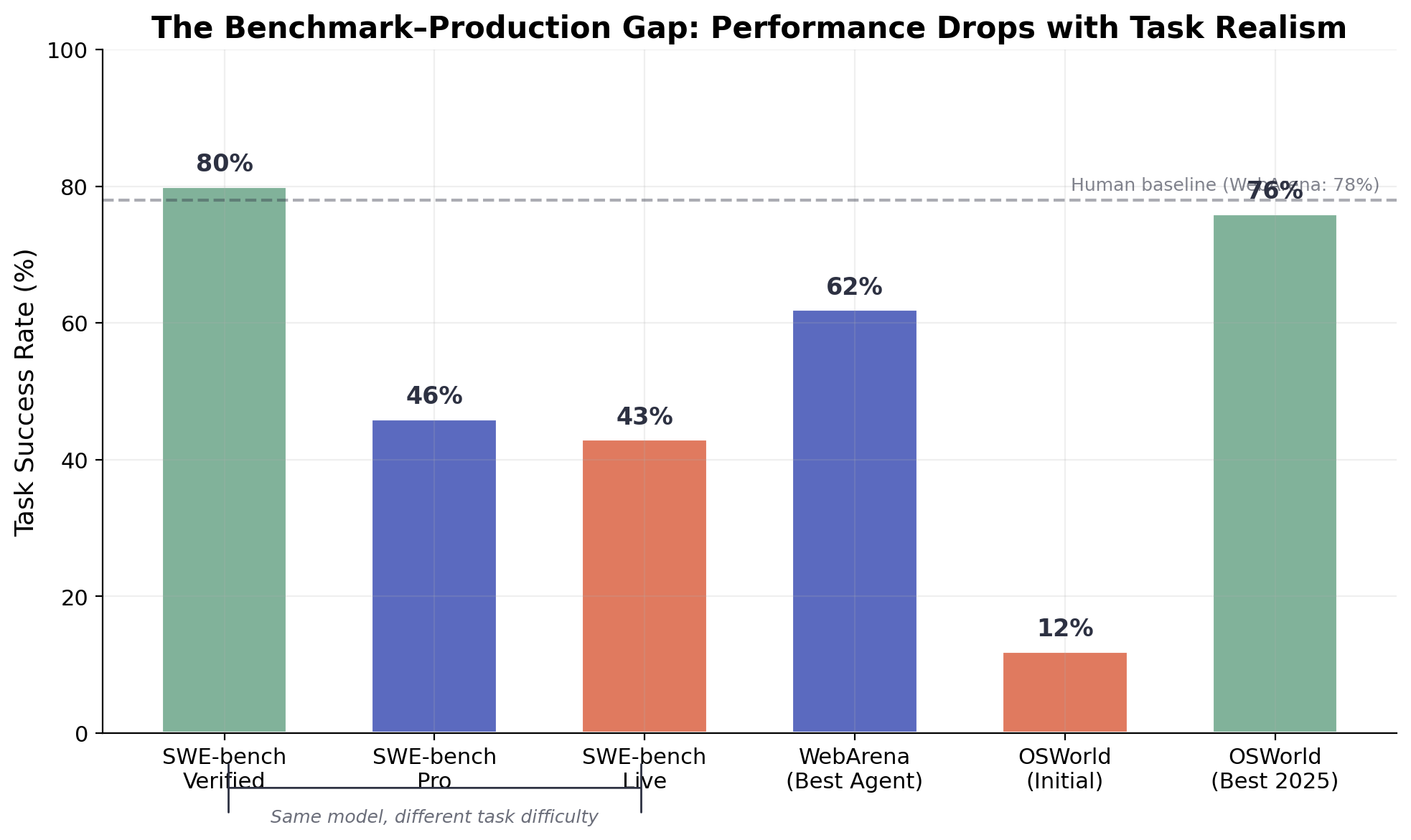 Figure 2. The gap between benchmark and production. The same model configurations show dramatically different success rates across SWE-bench variants (Verified → Pro → Live), WebArena, and OSWorld. Controlled benchmarks substantially overstate real-world capability.
Figure 2. The gap between benchmark and production. The same model configurations show dramatically different success rates across SWE-bench variants (Verified → Pro → Live), WebArena, and OSWorld. Controlled benchmarks substantially overstate real-world capability.
Benchmark data corroborates this across domains. On SWE-bench Verified, top agents score above 80%. SWE-bench Pro drops the same systems to ~46% [10]; SWE-bench Live shows 19–43% [9]. On WebArena, the best single-agent system reaches 61.7% against a human baseline of 78% [11]. On OSWorld desktop tasks, initial best-model success rates of 12.24% have climbed to 76% in some configurations, but Epoch AI notes that roughly 45% of those tasks can be completed with simple terminal commands rather than genuine GUI reasoning [12].
Benchmark performance and production reliability measure different things. The former captures peak capability under controlled conditions; the latter requires consistent performance across the long tail of real-world variation.
Token economics create a compounding cost crisis
The reliability problem has an economic twin. In naive iterative agent loops where each step re-processes the full growing conversation history, token costs accumulate quadratically rather than linearly. Analysis of the SWE-bench leaderboard shows high-performing agents consume 10–50× more tokens per task than single-shot approaches [13].
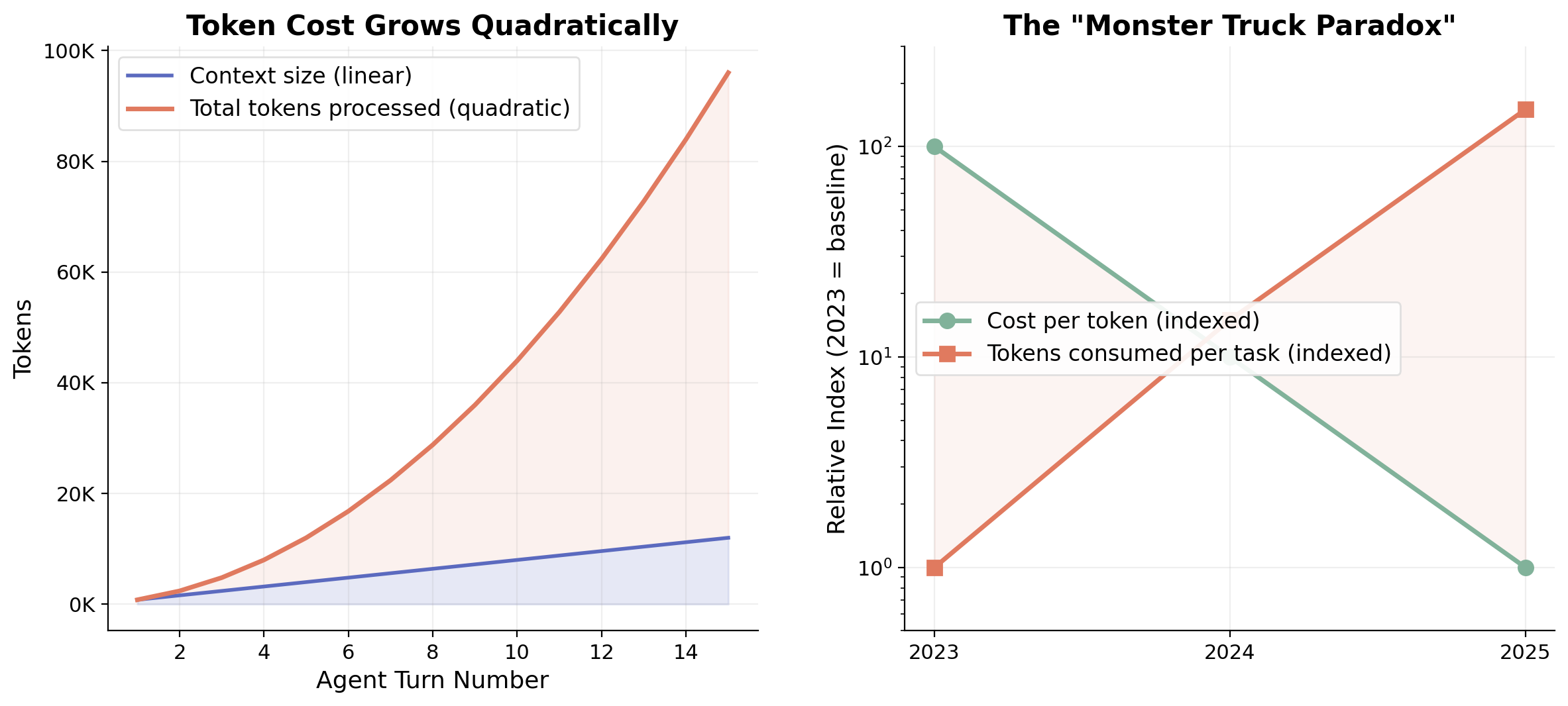 Figure 3. Left: Token costs grow quadratically as each agent turn re-processes all prior context. Right: The "Monster Truck Paradox": per-token costs fall ~10× per year, but consumption per task grows faster, driven by agentic workloads.
Figure 3. Left: Token costs grow quadratically as each agent turn re-processes all prior context. Right: The "Monster Truck Paradox": per-token costs fall ~10× per year, but consumption per task grows faster, driven by agentic workloads.
The scale is remarkable. The evolution from chat to agent has driven orders-of-magnitude increases in token consumption per session, with individual power users reporting billions of tokens consumed monthly [14]. Per-token costs have dropped ~10× per year since 2023, but consumption per task is growing faster than costs are falling.
In production, the economics tighten rather than loosen: per-token cost falls, consumption per task grows faster, and the gap between staging and production tends to widen rather than close [3][15]. Context compression (prompt caching, hierarchical summarization, selective attention) is the highest-ROI optimization in the literature, with reported reductions of 5–20× and savings of 70–94%. But these mitigations address symptoms.
Where feasible, the highest-leverage countermeasure is a stateless design: individual model calls are treated as specialized, single-purpose operations that take a clear instruction, return a result, and terminate. When state has to be preserved, it is externalized to a database or context store rather than carried along in the conversation. The combination is what lets the system both scale economically and remain auditable by a validation layer downstream.
Architectural patterns that actually improve reliability
The most encouraging recent result comes from Cognizant's AI Lab. Meyerson et al. ("Solving a Million-Step LLM Task with Zero Errors," 2025) [16] demonstrated the MAKER framework completing over one million sequential LLM steps with zero errors. MAKER achieves this through three principles: extreme decomposition into atomic subtasks handled by stateless "microagents," multi-agent voting based on a generalization of the gambler's ruin problem, and "red-flagging" where syntax errors signal logic errors to be discarded rather than repaired. Most surprisingly, smaller, non-reasoning models provided the best reliability-per-dollar.
An important caveat: MAKER's million-step result was achieved on a highly structured, fully verifiable task (Towers of Hanoi) with deterministic verification. The architectural principles (decomposition, voting, stateless microagents) are broadly applicable; the specific zero-error result should not be extrapolated to ambiguous enterprise workflows.
This aligns with a growing consensus across major labs. Anthropic's Building Effective Agents (Schluntz and Zhang, 2024) [17] established a clear hierarchy: start simple, add complexity only when demonstrated necessary, and recognize that agentic systems trade latency and cost for task performance. Anthropic subsequently achieved state-of-the-art SWE-bench results in part through careful refinements to tool descriptions, not model changes, a concrete demonstration that infrastructure design can matter more than model capability.
OpenAI's Practical Guide to Building Agents (2025) independently reaches similar conclusions, advising teams to maximize a single agent's capabilities first before introducing multi-agent complexity [18]. The convergence of guidance from competing labs on the same principles (simplicity, narrow scope, careful tool design) is itself significant evidence.
The programmatic approach pioneered by DSPy (Khattab et al., NeurIPS 2023) [19] offers another response. Rather than hand-crafting prompts, DSPy treats LLM pipelines as optimizable programs. On specific task configurations, the framework improved pipeline quality from 33% to 82% for GPT-3.5, though this figure comes from a particular benchmark slice. The broader point holds: DSPy achieves substantial gains through systematic optimization of pipeline structure rather than changes to underlying models.
The foundational architectures (ReAct [20] for grounding, Reflexion [21] for learning from failures, Voyager [22] for hierarchical composition) each address a different failure mode in compound systems. None of them is, on its own, the answer. The pattern that has held up in practice is composing the right combination for the reliability budget the task actually has.
What an architectural response looks like in agentic vision
The general principles above translate into a more specific shape when the modality is vision and the deployment target is industrial inspection. A few design moves recur in the systems that hold up.
The first is decomposition by responsibility. Rather than asking a single model to perceive, interpret, and decide in one pass, the work splits into narrow CV models for perception (detection, segmentation, OCR, depth, tracking), a reasoning layer for interpretation, and a consistency layer for validation. Each layer's per-step reliability is high because each layer's task is narrow. The reasoning layer never works on raw frames; the validation layer never works on free-form prose. The interfaces between layers are typed.
A separate point, related but not identical, is treating recovery as a first-class component rather than a fallback. Pedder's 2.7× equivalent gain from recovery infrastructure [4] is roughly what a dedicated validation pass is meant to capture. A claim that cannot be reconstructed from the perception layer's structured outputs gets blocked rather than patched in prose. In vision this matters more than it does in text. When a finding has to wait for the next inspection pass or the next cleaning window before fresh evidence is available, a validator that refuses to ship an unsupported claim is the difference between a usable report and one that quietly hides its uncertainty.
Externalizing state is the third move. Domain knowledge (drawings, SOPs, history) and accumulated patterns live outside any single agent's conversation window, and each model call sees only the slice of context relevant to its narrow task. The quadratic token growth problem [13] then does not arise, because the prompt does not balloon with history.
The fourth is treating autonomy as a deliberate design choice rather than something that emerges from capability. Feng, Morris, and Mitchell (Levels of Autonomy for AI Agents, 2025) [23] formalize this distinction. In settings where the agent's output drives physical action, autonomy is most usefully high at the perception layer (the detector flags what it sees) and tightly bounded at the action layer (an operator confirms before action). An autonomous action that turns out to be wrong has its cost paid in operational consequence, not in a paragraph that can be edited.
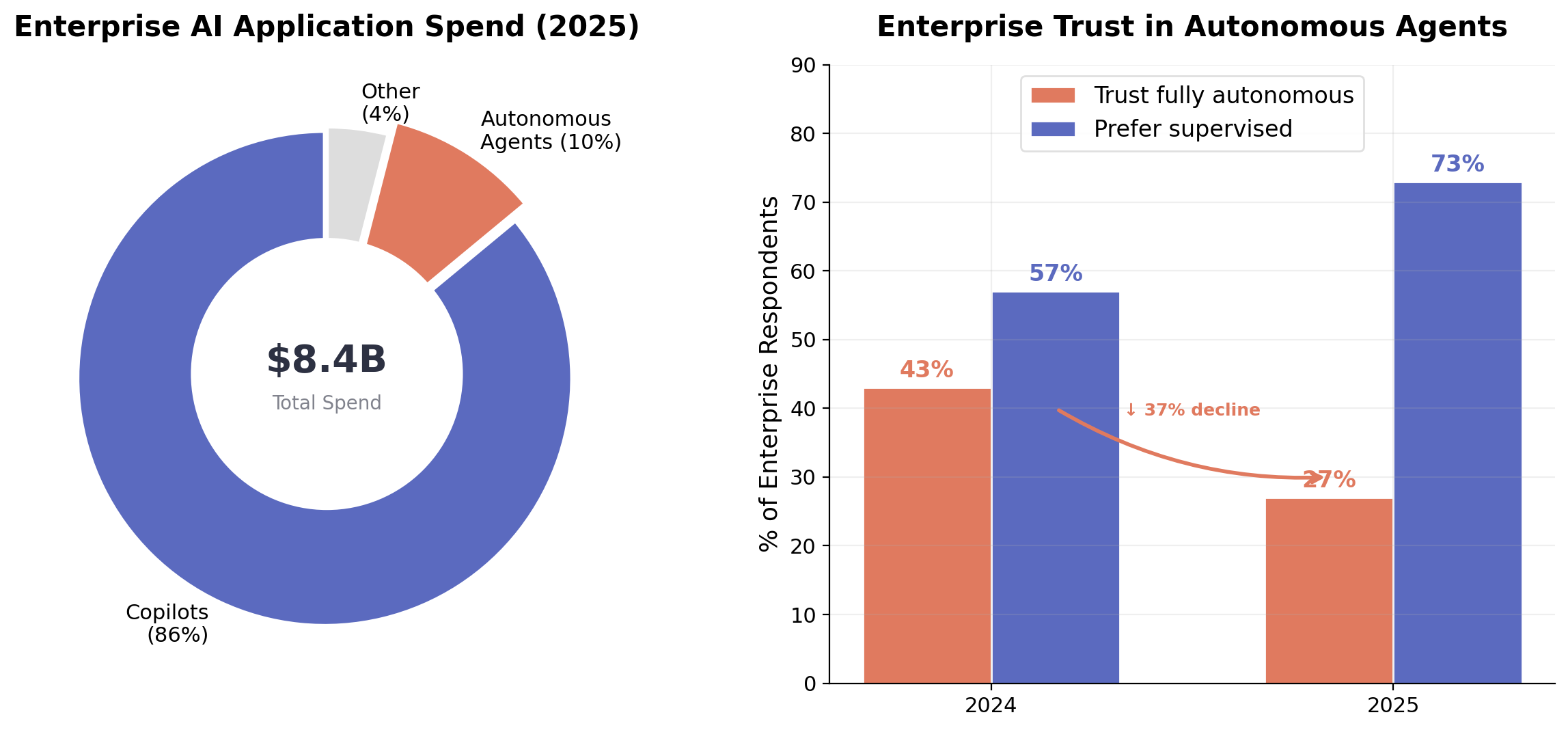 Figure 4. Left: Enterprise AI application spend in 2025: copilots versus autonomous agents [2]. Right: Surveyed trust in fully autonomous agents declined year-over-year [1].
Figure 4. Left: Enterprise AI application spend in 2025: copilots versus autonomous agents [2]. Right: Surveyed trust in fully autonomous agents declined year-over-year [1].
The market data reflects where the reliability infrastructure currently is, and the architectural responses above are consistent with that picture.
An open question underneath all of this is whether the architecture itself can be learned rather than hand-engineered. Jointly training a reasoning model's tool-selection policy with the specialist models it calls, so that outcome quality rather than step plausibility is what is optimized, is an active research direction. It is one possible answer to Princeton's finding that 18 months of capability gains left reliability unchanged [6]: reliability is not a property of the model in isolation, and waiting for a better single model does not produce it.
Where this leaves us
The evidence converges on a single point: for production reliability, engineering discipline currently accounts for more of the gap than further model capability gains do. Princeton's finding that 18 months of capability improvements left reliability unchanged. Cognizant's demonstration that, in a highly structured domain, small models with the right architecture can match or exceed large ones on reliability-per-dollar. Anthropic's achievement of SWE-bench state-of-the-art in part through tool-description refinement.
The compound-reliability problem is not a temporary limitation to be overcome by the next model generation. It is a structural property of sequential systems, and the responses that work are also structural: decomposition, verification, recovery, and autonomy bounded to where the reliability infrastructure can support it. Whether those are bolted on by hand or eventually learned end-to-end is the part still open.
References
- Capgemini, "Trust and Human-AI Collaboration Set to Define the Next Era of Agentic AI." 2025. capgemini.com
- Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
- Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." June 2025. gartner.com
- C. Pedder, "When agents fail: compounding errors in organisational systems." Substack, 2025
- M. Cemri, X. Pan, et al., "Why Do Multi-Agent LLM Systems Fail?" NeurIPS 2025. arXiv:2503.13657
- S. Rabanser, S. Kapoor, A. Narayanan, "Towards a Science of AI Agent Reliability." 2026. arXiv:2602.16666
- T. Kwa et al., "Measuring AI Ability to Complete Long Tasks." METR, 2025. arXiv:2503.14499
- T. Ord, "Is there a Half-Life for the Success Rates of AI Agents?" tobyord.com, 2025
- J. Yang et al., "SWE-bench Goes Live!" arXiv:2505.23419
- SWE-bench Pro Leaderboard. swebench.com
- S. Zhou et al., "WebArena: A Realistic Web Environment for Building Autonomous Agents." arXiv:2307.13854
- Epoch AI, "What does OSWorld tell us about AI's ability to use computers?" epoch.ai, 2025; T. Xie et al., "OSWorld: Benchmarking Multimodal Agents." arXiv:2404.07972
- "How Do Coding Agents Spend Your Money?" ICLR 2026 submission. OpenReview
- IKANGAI, "The LLM Cost Paradox: How 'Cheaper' AI Models Are Breaking Budgets." ikangai.com
- Anthropic, "Manage costs effectively, Claude Code Docs." code.claude.com
- E. Meyerson et al., "Solving a Million-Step LLM Task with Zero Errors." Cognizant AI Lab, 2025. arXiv:2511.09030
- E. Schluntz, B. Zhang, "Building effective agents." Anthropic, Dec 2024. anthropic.com
- OpenAI, "A Practical Guide to Building Agents." 2025. openai.com
- O. Khattab et al., "DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines." NeurIPS 2023. arXiv:2310.03714
- S. Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. arXiv:2210.03629
- N. Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. arXiv:2303.11366
- G. Wang et al., "Voyager: An Open-Ended Embodied Agent with Large Language Models." TMLR 2024. voyager.minedojo.org
- G. Feng, M. Morris, K. Mitchell, "Levels of Autonomy for AI Agents." 2025. arXiv:2506.12469