
Why reliability demands engineering discipline, not just model scaling, and what the mathematics, benchmarks, and market data tell us about building agents that actually work in production.
AI agents that chain multiple steps together face a well-known mathematical problem: in a simple sequential pipeline with fixed per-step success and no effective recovery, reliability degrades exponentially with each additional step. A system where each individual step succeeds 95% of the time yields just 36% end-to-end success across 20 steps. This isn't a bug to be patched—it's a structural property of sequential systems without recovery mechanisms, and it demands architectural, not just model-level, solutions. As this article will show, architecture choices like decomposition, voting, and externalized state can materially change the decay curve, but only when they are deliberately engineered in.
As enterprises pour billions into agentic AI, understanding this compound reliability problem—and its economic twin, compound cost scaling—has become the central engineering challenge of the field. The past two years have seen extraordinary progress in AI agent capabilities. SWE-bench scores for coding agents leapt from 14% to over 80%. WebArena task completion rose from 14% to 62%. Yet production deployment tells a starkly different story. While the numbers come from different surveys with different methodologies, the directional picture is consistent: Capgemini found that only 2% of enterprises have fully scaled their AI agent deployments [1]; Menlo Ventures reports that just 16% of enterprise AI deployments qualify as "true agents" [2]; and Gartner projects that 40% of agentic AI projects will be canceled before deployment by 2027 [3]. These are not directly comparable metrics, but together they paint a picture of an industry where agentic AI adoption remains early-stage and fragile.
The gap between benchmark performance and production reliability remains stubbornly wide—and the evidence presented below suggests the two metrics may be measuring fundamentally different things. This post examines why, drawing on recent empirical research, mathematical analysis, and architectural insights from building agent systems in practice.
The mathematics of compound failure are unforgiving
The core reliability problem in multi-step agent systems follows directly from probability theory. If a pipeline consists of n sequential steps, each with independent success probability p, then end-to-end success probability is pⁿ. This exponential decay creates a brutal landscape for complex agent workflows:
| Per-step accuracy | Steps | End-to-end success |
|---|---|---|
| 99% | 10 | 90.4% |
| 95% | 10 | 59.9% |
| 95% | 20 | 35.8% |
| 90% | 10 | 34.9% |
| 99% | 100 | 36.6% |
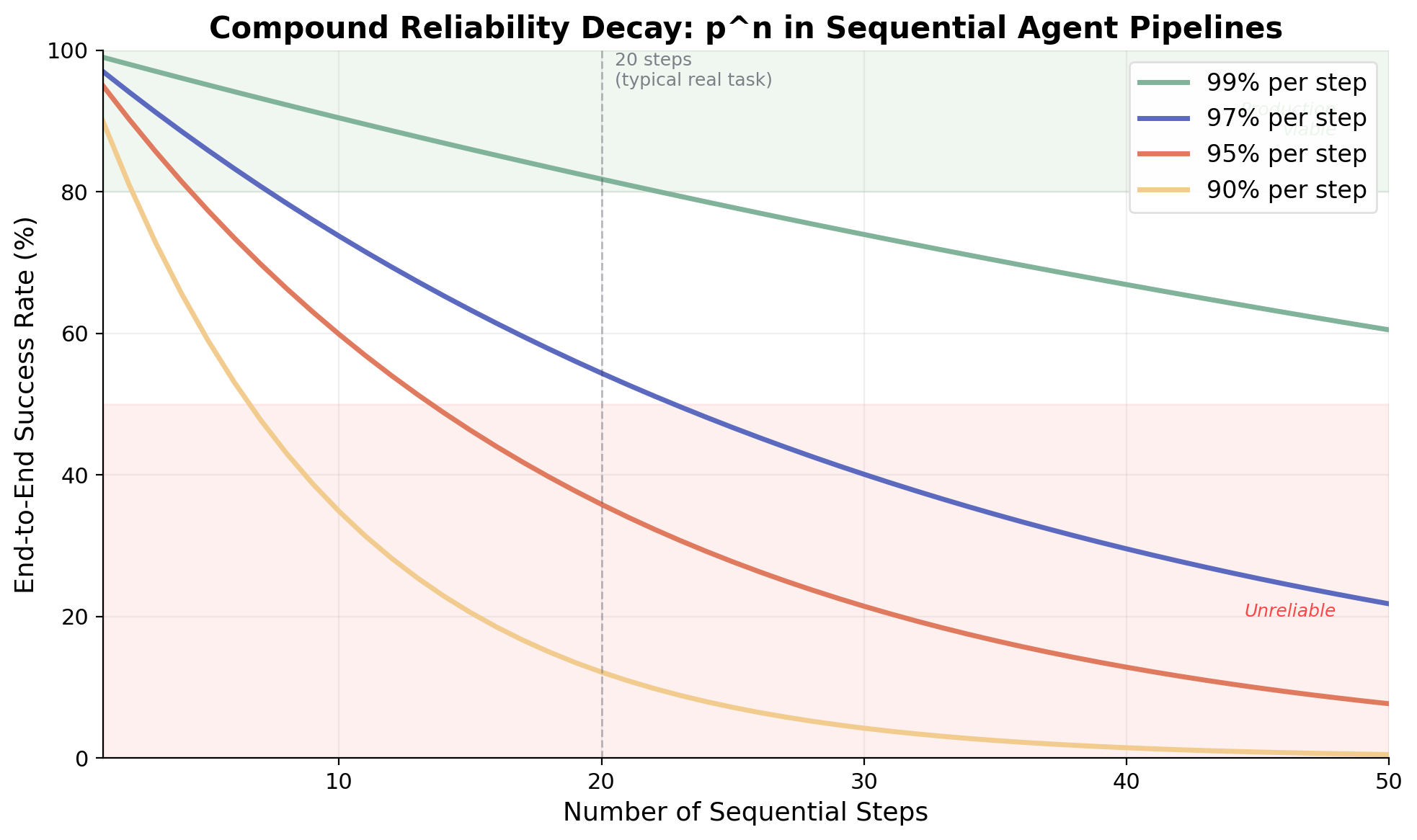
Figure 1. End-to-end success rate as a function of sequential step count, for various per-step reliability levels. Even 99% per-step accuracy yields only 60% success at 50 steps.
This simple model actually understates the real problem. Steps in agent pipelines are rarely independent, errors propagate semantically, corrupting downstream context in ways that are difficult to detect or recover from. Chris Pedder's concept of "failure stickiness" formalizes this: when errors propagate invisibly through a pipeline (what Pedder calls "absorbing failures"), a system with 95% per-step reliability and high failure stickiness performs dramatically worse than the independence assumption predicts [4]. His analysis shows that the ability to recover from errors is equivalent to making each step 2.7 times more reliable, a finding that reframes the reliability problem as fundamentally about recovery architecture, not just step-level accuracy.
A 2025 paper from UC Berkeley, "Why Do Multi-Agent LLM Systems Fail?" (Cemri et al., NeurIPS 2025), provides the most comprehensive empirical analysis to date [5]. The researchers annotated over 1,600 execution traces across seven popular multi-agent frameworks and identified 14 distinct failure modes. Failure rates reached 86.7% in popular frameworks like OpenHands and MetaGPT on cross-application tests. Perhaps most sobering: proposed interventions like improved role specification and enhanced orchestration proved insufficient, the authors concluded that the identified failures "require more complex solutions."
The most rigorous reliability framework comes from Princeton researchers Rabanser, Kapoor, and Narayanan ("Towards a Science of AI Agent Reliability," 2026) [6], who decomposed agent reliability into 12 metrics across four dimensions: consistency, robustness, predictability, and safety. Their central finding deserves emphasis: despite rapid capability improvements across 14 frontier models over 18 months, reliability has barely budged. The standard pass@1 metric, they found, overestimates true reliability by 20–40%.
Key insight: Accuracy and reliability are fundamentally different properties. A model can get dramatically better at solving problems while remaining just as unpredictable about which problems it will solve.
Agent success rates decay exponentially with task complexity
METR's landmark study "Measuring AI Ability to Complete Long Tasks" (Kwa et al., 2025) [7] provides the definitive empirical picture of how agent performance degrades with task complexity. The researchers measured the "50% time horizon", the task length (in human-equivalent time) at which an agent succeeds half the time. For Claude 3.7 Sonnet, this horizon sat at roughly 50 minutes.
Toby Ord's subsequent analysis [8] explored the implications under a constant-hazard-rate assumption—a simplified model that treats failure probability as uniform across task duration. Under this framing, if an agent achieves 50% success on 50-minute tasks, it can only achieve 90% success on tasks of about 7 minutes, and 99% success on tasks of roughly 43 seconds. For enterprise applications requiring 99.9% reliability, the usable task length collapses to just seconds. These are back-of-the-envelope extrapolations, not operational measurements, but they illustrate the severity of the compound reliability problem. Importantly, Ord found that human survival curves are noticeably better than this constant-hazard model, suggesting that humans recover from mistakes more effectively than current agents.
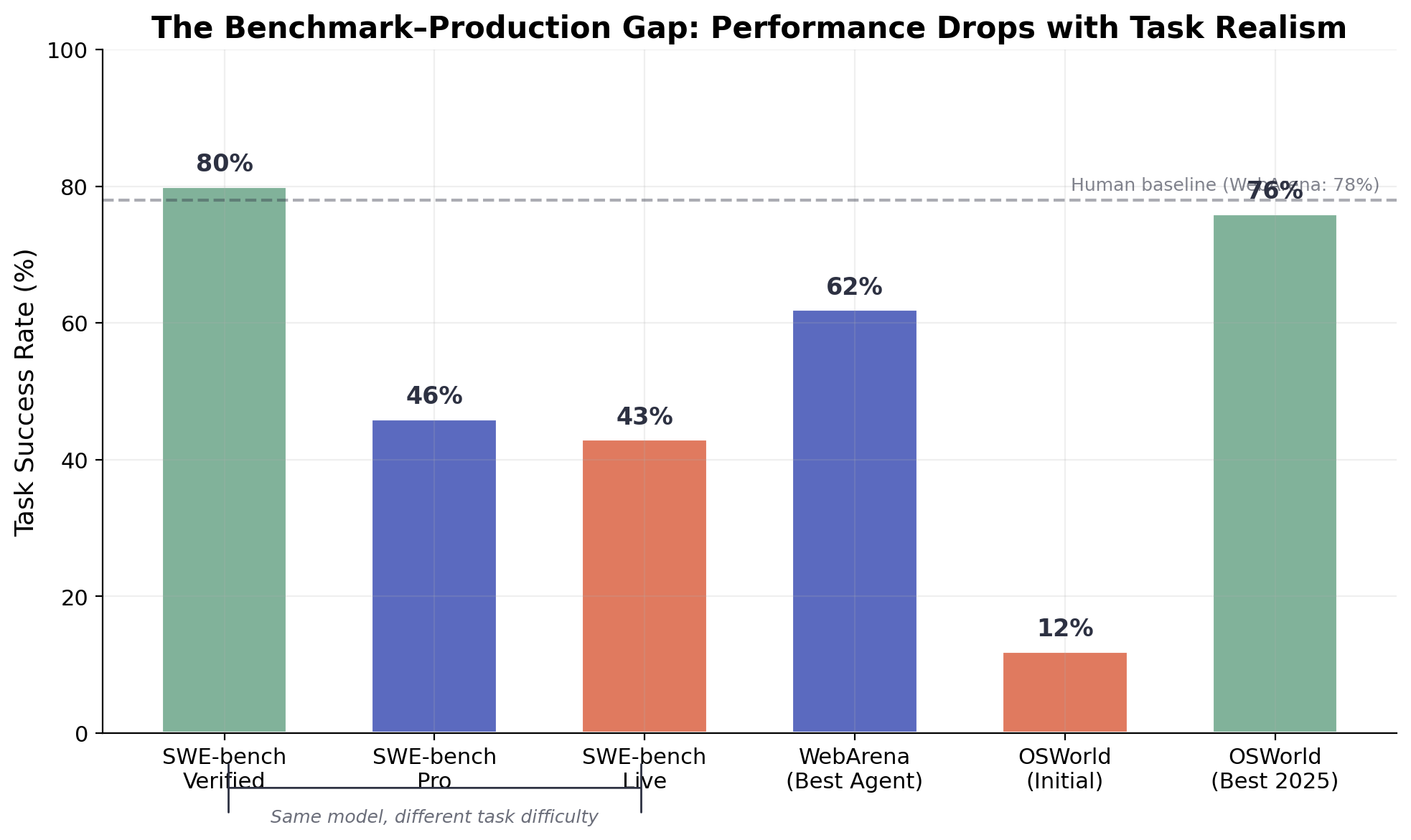
Figure 2. The benchmark–production gap. The same model configurations show dramatically different success rates across SWE-bench variants (Verified → Pro → Live), WebArena, and OSWorld. Controlled benchmarks substantially overstate real-world capability.
Benchmark data corroborates this pattern across domains. On SWE-bench Verified, top agents score above 80%. But SWE-bench Pro drops the same systems to roughly 46% [10], and SWE-bench Live shows 19–43% [9]. On WebArena, the best single-agent system reaches 61.7% against a human baseline of 78% [11]. On OSWorld desktop tasks, initial best-model success rates of 12.24% have climbed to 76% in some configurations, but Epoch AI notes that roughly 45% of those tasks can be completed with simple terminal commands rather than genuine GUI reasoning [12].
The broader pattern is clear: benchmark performance and production reliability are measuring different things. The former captures peak capability under controlled conditions; the latter requires consistent performance across the long tail of real-world variation.
Token economics create a compounding cost crisis
The reliability problem has an economic twin. In naive iterative agent loops where each step re-processes the full growing conversation history, token costs accumulate quadratically rather than linearly. Analysis of the SWE-bench leaderboard shows that high-performing agents consume 10–50 times more tokens per task than single-shot approaches [13].
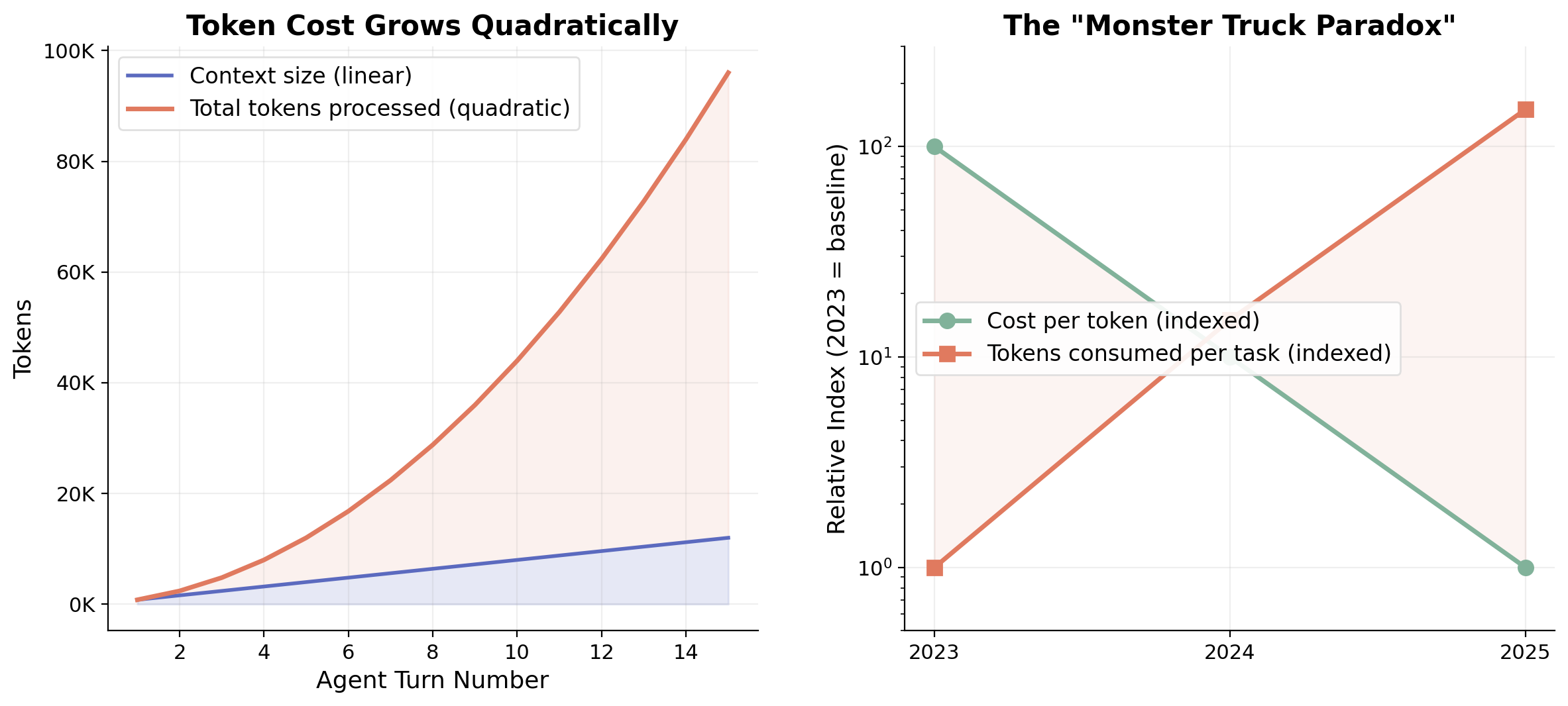
Figure 3. Left: Token costs grow quadratically as each agent turn re-processes all prior context. Right: The "Monster Truck Paradox", per-token costs fall ~10× per year, but consumption per task grows faster, driven by agentic workloads.
The scale of consumption is remarkable. The evolution from chat-based to agent-based interaction has driven orders-of-magnitude increases in token consumption per session, with individual power users reporting billions of tokens consumed monthly [14]. Per-token costs have dropped dramatically, roughly 10× per year since 2023, but consumption per task is growing faster than costs are falling.
For production deployments, the economics are sobering. Moderate agent deployments cost $1,000–$5,000 per month at 5–10 million tokens. Claude Code runs average $6 per developer per day [15]. Enterprise prototypes frequently see cost jumps from $5,000/month to $50,000/month when moving from staging to production [3]. Context compression, achieving 5–20× reduction through prompt caching, hierarchical summarization, and selective attention, offers the highest-ROI optimization, with reported savings of 70–94%. But these mitigations address symptoms rather than the underlying architectural challenge.
Where feasible, stateless design is often the highest-leverage countermeasure. Wherever possible, avoid multi-turn conversations entirely. Treat agents as specialized, single-purpose tools: provide a clear instruction, receive a result, and terminate the session. This eliminates context accumulation at the source, no growing prompt, no runaway token cost. When state must be preserved, externalize it: write intermediate results to a database or file system rather than carrying them in the conversation context. The agent that remembers nothing between calls is the agent that scales.
Architectural patterns that actually improve reliability
The most encouraging recent result comes from Cognizant's AI Lab. Meyerson et al. ("Solving a Million-Step LLM Task with Zero Errors," 2025) [16] demonstrated the MAKER framework completing over one million sequential LLM steps with zero errors. MAKER achieves this through three principles: extreme decomposition into atomic subtasks handled by stateless "microagents," multi-agent voting based on a generalization of the gambler's ruin problem, and "red-flagging" where syntax errors signal logic errors to be discarded rather than repaired. Most surprisingly, smaller, non-reasoning models provided the best reliability-per-dollar.
An important caveat: MAKER's million-step result was achieved on a highly structured, fully verifiable, and extremely decomposable task (a highly structured combinatorial task (Towers of Hanoi) with deterministic verification). This makes it a compelling proof of principle for the power of decomposition and local verification, but not direct evidence that general enterprise agent workflows—which often involve ambiguous goals, unstructured data, and non-verifiable intermediate steps—can achieve similar reliability. The architectural principles (decomposition, voting, stateless microagents) are broadly applicable; the specific zero-error result should not be extrapolated beyond its domain.
This finding aligns with a growing consensus across major AI labs. Anthropic's influential "Building Effective Agents" guide (Schluntz and Zhang, 2024) [17] established a clear hierarchy: start with simple patterns, add complexity only when demonstrated necessary, and recognize that agentic systems trade latency and cost for task performance. Their subsequent work on tool design demonstrated that the company achieved state-of-the-art SWE-bench results in part through careful refinements to tool descriptions, not model changes, a concrete demonstration that infrastructure design can matter more than model capability.
OpenAI's "Practical Guide to Building Agents" (2025) independently reaches similar conclusions, advising teams to maximize a single agent's capabilities first before introducing multi-agent complexity [18]. The convergence of guidance from competing labs on the same principles, simplicity, narrow scope, careful tool design, is itself significant evidence.
These findings point to a pattern that practitioners consistently rediscover: in a production agent system, the AI model is often not the dominant factor in overall performance. Based on our own experience and conversations with teams in the field, tool design, orchestration, and error handling frequently matter more than model choice—though the exact ratio varies by application. How does the system communicate success to the model using minimal tokens? When a tool call fails, how does it express the error and the next step concisely? These are the questions that determine whether an agent works in production, and they cannot be solved by model intelligence alone.
The programmatic approach pioneered by DSPy (Khattab et al., NeurIPS 2023) [19] offers another architectural response. Rather than hand-crafting prompts, DSPy treats LLM pipelines as optimizable programs. On specific task configurations, the framework improved pipeline quality from 33% to 82% for GPT-3.5—though this figure comes from a particular benchmark slice, and results vary across tasks. The broader point holds: DSPy achieves substantial gains through systematic optimization of pipeline structure rather than changes to underlying models.
Key insight: The foundational architectures, ReAct [20] for grounding, Reflexion [21] for learning from failures, Voyager [22] for hierarchical composition, each address a different failure mode of compound systems. The winning pattern isn't choosing one, but composing the right combination for the task's reliability requirements.
Enterprise spending favors lower-autonomy AI products
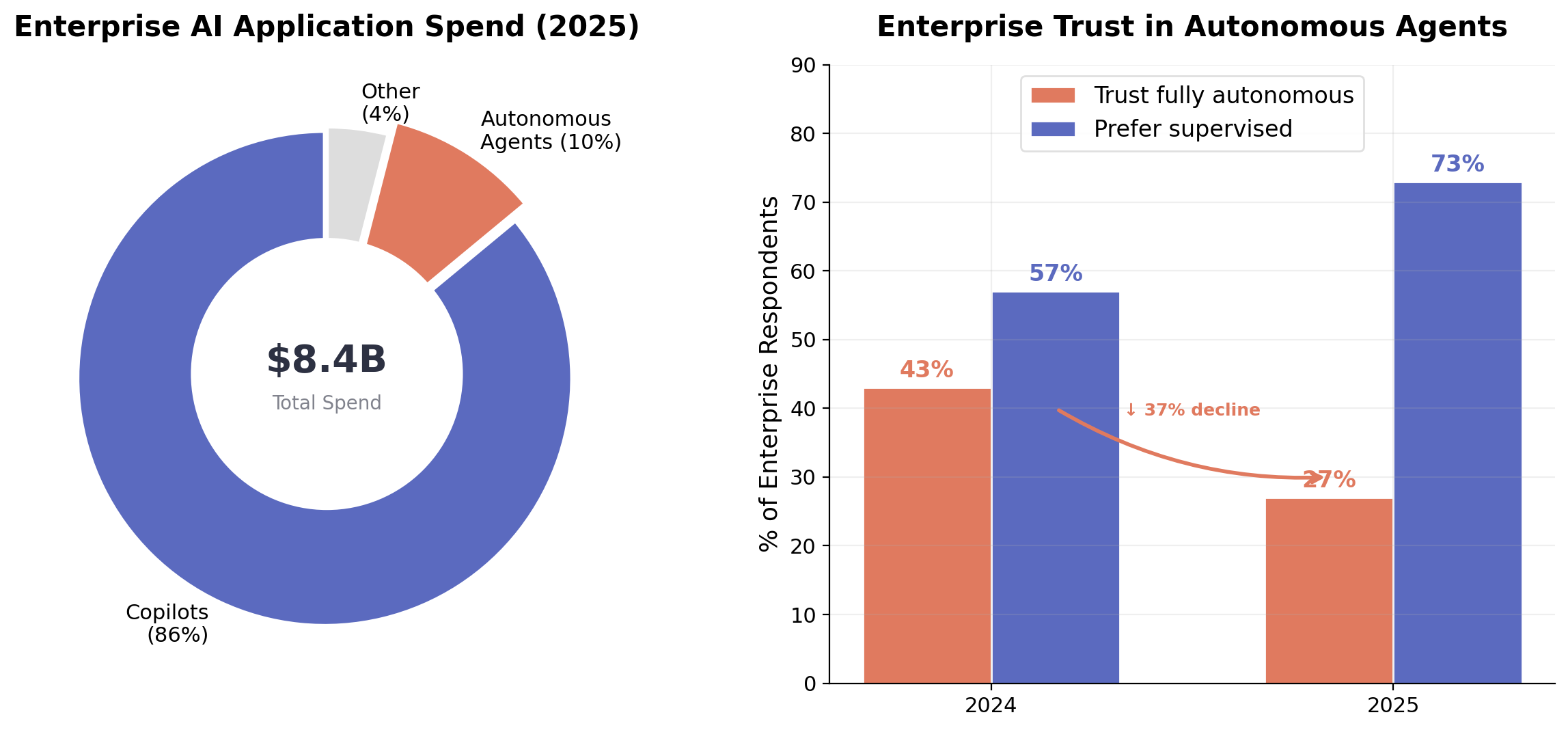
Figure 4. Left: Enterprise AI application spend in 2025 is overwhelmingly directed toward copilots (86%) rather than autonomous agents (10%). Source: Menlo Ventures 2025 Enterprise Survey [23]. Right: Trust in fully autonomous agents declined from 43% to 27% year-over-year. Source: Capgemini 2025 Agentic AI Report [1].
The most telling evidence for the appropriate-autonomy thesis comes from market data. Menlo Ventures' 2025 enterprise survey found that copilots capture 86% of horizontal AI application spend ($7.2 billion) while autonomous agents account for just 10%, and only 16% of enterprise AI deployments qualify as "true agents" [23]. Separately, Capgemini's 2025 survey on agentic AI found that trust in fully autonomous agents has actually declined, from 43% to 27% year over year [1].
Real-world deployment data tells the same story. Answer.AI tested Devin across 20 diverse tasks and achieved 3 successes, 14 failures, and 3 inconclusive results [24]. Cognition Labs' own performance review acknowledged that Devin excels with clear, upfront requirements but cannot independently tackle ambiguous projects end-to-end [25].
Feng, Morris, and Mitchell ("Levels of Autonomy for AI Agents," 2025) [26] formalized this into a five-level autonomy framework. Their key argument: autonomy is a deliberate design decision, separable from capability. A highly capable agent can and often should operate at low autonomy levels. The compound AI systems paradigm articulated by Zaharia et al. (BAIR, 2024) [27] provides the theoretical grounding: state-of-the-art results increasingly come from engineered systems with multiple interacting components, not monolithic autonomous agents.
Why does lower autonomy tend to correlate with higher reliability in current deployments? Not because narrow scope is inherently more reliable, but because lower-autonomy designs make it easier to insert human review, step-level verification, and rollback mechanisms—the very recovery architecture that, as discussed above, can be equivalent to multiplying per-step reliability. The market signal is not that autonomous agents are a dead end, but that at the current state of the technology, the reliability infrastructure needed to support high autonomy is not yet in place for most enterprise use cases.
Where this leaves us: engineering discipline matters at least as much as model scaling
The evidence converges on a conclusion that the field has been slow to internalize: for production reliability, engineering discipline matters at least as much as—and in many current deployments, more than—further model capability gains. Princeton's finding that 18 months of capability improvements left reliability unchanged; Cognizant's demonstration that, in a highly structured domain, small models with the right architecture can match or exceed large ones on reliability-per-dollar; Anthropic's achievement of SWE-bench state-of-the-art in part through tool description refinement, these all point in the same direction.
What this looks like in practice is best illustrated by contrast. Consider an autonomous customer support agent designed to resolve all incoming tickets end-to-end, reading the complaint, querying internal systems, issuing refunds, and composing the final response without human involvement. This is the vision that demos well on stage. In production, such a system will misclassify edge cases, issue incorrect refunds, and generate responses that escalate frustrated customers. A far more valuable system is a triage and drafting assistant: one that classifies tickets by urgency, pulls relevant order history, drafts a response for human review, and flags cases that require escalation. The latter is narrow, verifiable at each step, and can significantly multiply analyst throughput while keeping a human in control of consequential decisions.
Or consider an autonomous due diligence agent that produces complete investment memos from raw filings, the kind of end-to-end workflow that sounds transformative. In reality, a single hallucinated revenue figure or a missed risk factor renders the entire memo unreliable. A more deployable version is a research assistant that monitors SEC filings around the clock, extracts key financial metrics, detects anomalies against historical baselines, and surfaces time-sensitive insights for analysts to act on. It doesn't replace the analyst's judgment, it ensures no signal is missed while the analyst sleeps.
The practical implications for teams building agent systems are clear. First, treat compound reliability as a first-class design constraint. The pⁿ decay means that a 20-step pipeline needs per-step reliability above 99% to achieve even 80% end-to-end success, a bar that current models rarely clear without architectural support. Second, invest in recovery mechanisms over prevention. Pedder's analysis shows that the ability to detect and recover from errors has an effect on system reliability equivalent to making each step 2.7 times more reliable—a strong argument for prioritizing recovery architecture. Third, scope agent autonomy to match reliability requirements. Under Ord's constant-hazard extrapolation of METR's data, achieving 99% reliability would limit agents to tasks roughly 1/70th the length of their 50% reliability horizon—an illustrative order-of-magnitude that underscores how sharply usable task scope contracts as reliability requirements rise.
The economic case reinforces the architectural one. Quadratic-like token scaling in naive iterative loops, high cost variance, and the Monster Truck Paradox mean that unconstrained agent autonomy without architectural mitigations is not just unreliable, it's economically unsustainable. The enterprises succeeding with AI agents are those treating them as precision instruments deployed within well-engineered systems, not as general-purpose autonomous workers.
The field of AI agents is advancing rapidly, METR's 50% time horizon is doubling every seven months, and benchmark scores continue to climb. But the gap between capability and reliability persists, and closing it requires a shift in how we think about these systems. The compound reliability problem isn't a temporary limitation to be overcome by the next model generation. It's a structural property of sequential systems that demands structural solutions: decomposition, verification, recovery, and appropriate autonomy. The organizations that internalize this insight, building well-scoped, reliable, well-instrumented agents—and expanding autonomy only where the reliability infrastructure can support it—will be the ones that capture real value from the agentic era.
References
Capgemini, "Trust and Human-AI Collaboration Set to Define the Next Era of Agentic AI." 2025. capgemini.com
Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." Press release, June 2025. gartner.com
C. Pedder, "When agents fail: compounding errors in organisational systems." Substack, 2025
M. Cemri, X. Pan, et al., "Why Do Multi-Agent LLM Systems Fail?" NeurIPS 2025. arXiv:2503.13657
S. Rabanser, S. Kapoor, A. Narayanan, "Towards a Science of AI Agent Reliability." 2026. arXiv:2602.16666
T. Kwa et al., "Measuring AI Ability to Complete Long Tasks." METR, 2025. arXiv:2503.14499
T. Ord, "Is there a Half-Life for the Success Rates of AI Agents?" tobyord.com, 2025
J. Yang et al., "SWE-bench Goes Live!" arXiv:2505.23419
SWE-bench Pro Leaderboard. swebench.com
S. Zhou et al., "WebArena: A Realistic Web Environment for Building Autonomous Agents." arXiv:2307.13854
Epoch AI, "What does OSWorld tell us about AI's ability to use computers?" epoch.ai, 2025; T. Xie et al., "OSWorld: Benchmarking Multimodal Agents." arXiv:2404.07972
"How Do Coding Agents Spend Your Money? Analyzing and Predicting Token Consumptions in Agentic Coding Tasks." ICLR 2026 submission. OpenReview
IKANGAI, "The LLM Cost Paradox: How 'Cheaper' AI Models Are Breaking Budgets." ikangai.com
Anthropic, "Manage costs effectively — Claude Code Docs." code.claude.com
E. Meyerson et al., "Solving a Million-Step LLM Task with Zero Errors." Cognizant AI Lab, 2025. arXiv:2511.09030
E. Schluntz, B. Zhang, "Building effective agents." Anthropic, Dec 2024. anthropic.com
OpenAI, "A Practical Guide to Building Agents." 2025. openai.com
O. Khattab et al., "DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines." NeurIPS 2023. arXiv:2310.03714
S. Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. arXiv:2210.03629
N. Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. arXiv:2303.11366
G. Wang et al., "Voyager: An Open-Ended Embodied Agent with Large Language Models." TMLR 2024. voyager.minedojo.org
Menlo Ventures, "2025: The State of Generative AI in the Enterprise." menlovc.com
J. Howard, Answer.AI, "Testing Devin: 20 diverse tasks." 2024.
Cognition Labs, "Devin's 2025 Performance Review." cognition.ai
G. Feng, M. Morris, K. Mitchell, "Levels of Autonomy for AI Agents." 2025. arXiv:2506.12469
M. Zaharia et al., "The Shift from Models to Compound AI Systems." BAIR Blog, Feb 2024. bair.berkeley.edu