
Yodo Labs' Synthetic Data Platform generates annotated training data for visual recognition models in safety-critical industries. Purpose-built for functional correctness , not visual appeal , the platform enables organizations to close the training data gap for corner cases, rare object classes, and scenarios that cannot be collected in the real world.
- Adapts to new visual domains with extremely few reference images
- Deployed in autonomous driving and manufacturing quality inspection
The Training Data Gap
Deep learning models in autonomous driving, manufacturing inspection, and other safety-critical applications share a common failure pattern: they perform worst on the scenarios that matter most. We built the Synthetic Data Platform to close this gap, generating annotated training data for the corner cases, rare classes, and scenarios that cannot be collected in the real world. The following is a pilot we conducted with a major automotive OEM.
Case Study: A Major Automotive OEM
We worked with the R&D division of a major automotive OEM, whose autonomous driving team operates a multi-camera sensor suite with wide-angle and fisheye lenses. The client provided a subset of 24,000 annotated images from their production dataset as the training set, along with a separate held-out test set.
The training data gap in their dataset was typical of the industry. Passenger cars appeared thousands of times; school buses, fire trucks, and construction vehicles appeared a handful of times each. Close-range vehicles filling the entire camera frame, among the most dangerous scenarios for an autonomous vehicle, were severely underrepresented. Trucks so close that they extend beyond the frame and appear only partially, for example, appeared only 233 times in 24,000 images.
This is primarily a data bottleneck, not an algorithmic one. The real world is long-tailed, corner cases cannot be staged or collected on demand, and conventional augmentation techniques cannot introduce visual diversity that was never captured.
We adapted the platform to each of the client's camera configurations and generated synthetic training data targeting four categories of gaps.
Rebalancing the Long Tail
Replace over-represented object classes with rare ones in existing scenes. The scene composition is preserved; only the target objects change , directly rebalancing class distribution without new data collection.


Increasing Instance Density
Add new object instances at plausible positions within existing scenes, increasing the number of labeled objects per image.


Targeting Specific Corner Cases
Define the exact scenario needed , an extremely close truck, an unusual spatial arrangement, a rare configuration , and generate as many diverse examples as required.


Generating Unknown Objects
Generate objects that never existed in the training data , road debris, unusual obstacles, animals , as new object categories at specified positions with correct annotations. This enables extending the detection vocabulary to classes that have zero real-world training samples.


Results
We added approximately 36,000 synthetic images to the 24,000-image training set and measured the impact on the client's object detection pipeline.
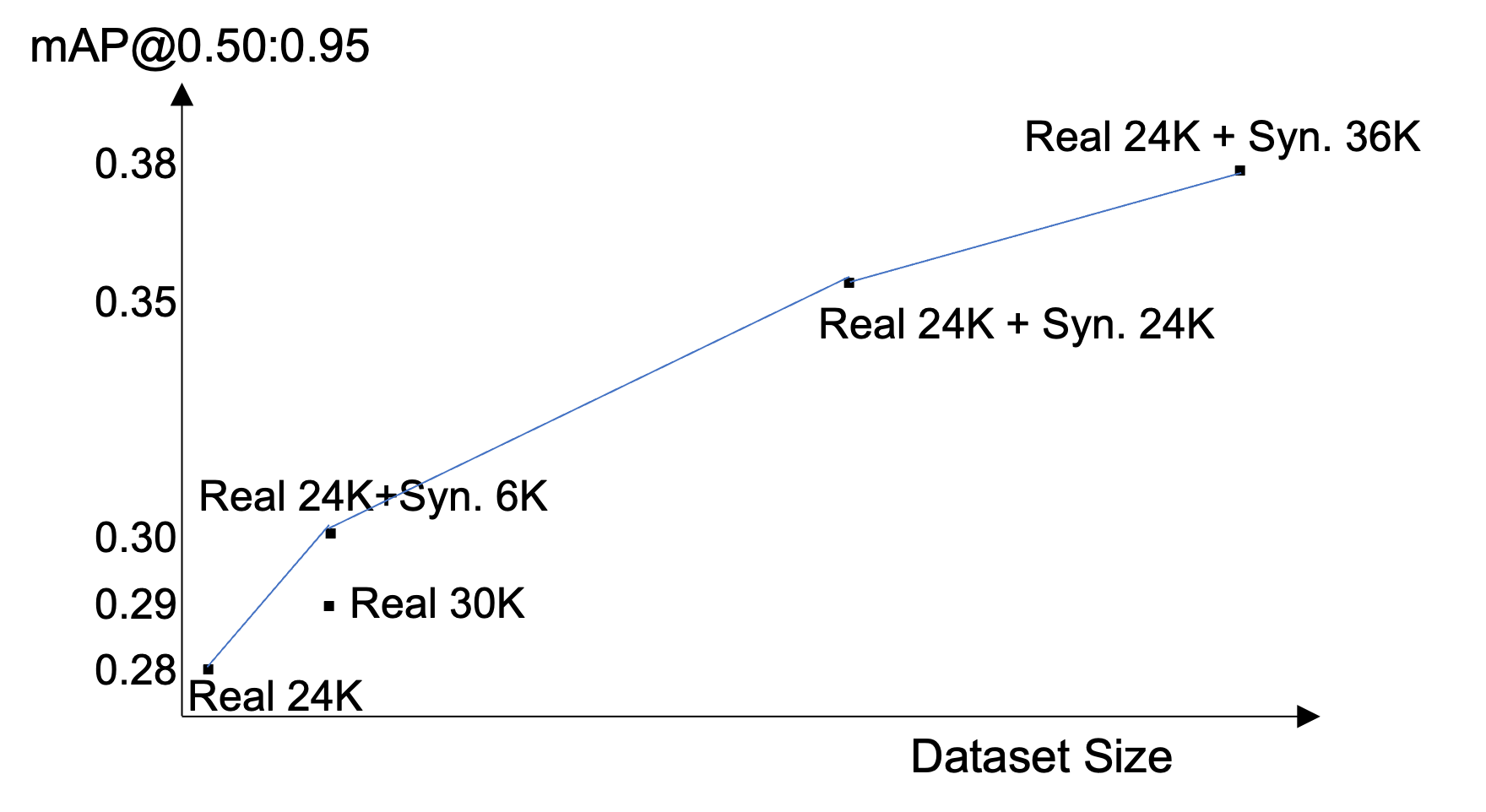
mAP from 0.279 to 0.378. Adding approximately 36,000 synthetic images improved mAP by +0.099 absolute (+35.5% relative). The performance curve had not plateaued at the maximum tested volume, though marginal gains may diminish as synthetic-to-real ratio increases further.
Synthetic outperformed real at this data ratio. In this specific comparison, 24,000 real + 6,000 synthetic images achieved higher mAP than 30,000 real images. Synthetic images generated via the addition strategy contain more annotated instances per image, providing a denser training signal.
233 images improved a critical corner case. For trucks so close they extend beyond the frame and appear only partially , only 233 examples in training vs. 503 in the test set , generating 233 targeted synthetic examples improved detection in this scenario.


The Synthetic Data Platform
The Synthetic Data Platform is built on a proprietary image generation model developed in-house by Yodo Labs, based on the computer vision research of founder Xiuxi Pan, PhD. It is neither a general-purpose generator repurposed for training data, nor a wrapper around existing generative AI services. It is a dedicated model architected from the ground up for one objective: generating training data that makes recognition models better.
The mainstream generative AI industry competes on producing images that are beautiful and interesting , optimizing for human visual preference. We deliberately go in the opposite direction. Our model optimizes for functional correctness: the two properties that determine whether synthetic data actually improves model performance, and that existing generators often fail to deliver.
Positional fidelity , generated objects appear exactly where their annotations specify. The input layout becomes the output annotation by construction, with no manual labeling required. This is the property that makes synthetic data usable as training data at all , and one that general-purpose generators often treat as an afterthought.
Stylistic coherence , generated images match the visual characteristics of the target deployment environment. The platform adapts to a new camera system or visual domain with extremely few reference images , no annotations needed. This is what closes the domain gap between synthetic and real data, helping synthetic images contribute to training rather than degrading it.
Applications
The Synthetic Data Platform is deployed across:
- Autonomous driving , corner case coverage, long-tail rebalancing, unknown obstacle detection, multi-camera adaptation
- Manufacturing quality inspection , rare defect augmentation, cold-start training for new product lines where no defect data yet exists
The underlying problem , too few examples of the scenarios that matter most , is common to any domain where visual recognition operates in safety-critical conditions.
Get Started
If your organization faces training data gaps for corner cases, rare classes, or new deployment scenarios, we would welcome a conversation.